1 one-word context
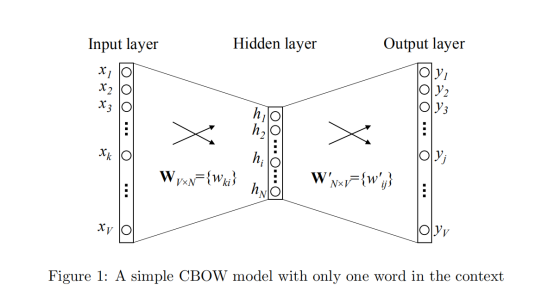
假设:
词汇表里面有3个单词 ‘今天’,‘天气’,‘不错’; 即V=3
隐藏层具有2个节点;即N=2
目的是当输入一个单词,我们来预测其下一个单词?
则在input layer由one-hot编码:
- 今天······[1,0,0]
- 天气······[0,1,0]
- 不错······[0,0,1]
接着我们需要初始化一下输入矩阵和输出矩阵
这里的值你可以任意定义,反正最后都会由梯度下降到最低点的:
首先以‘天气‘为例:
1.由公式可以推出:
2.接着由公式可以推出:(
为
矩阵中的第
列)
3.再由公式:
更新隐藏层→输出层权重的等式
我们知道‘天气’后面正确的输出应该是‘不错’,所以真实值为:
则 可以理解为,当
等于不错时
等于1,其余等于0;
由公式得:
再由:和
可得:
这里假设学习率
更新隐藏层→输出层权重的等式
由公式和公式
可得:
对比一下更新前与更新后:
输入单词‘天气’:
更新前:
更新后
期望输出单词‘不错’:
更新前:
更新后:
余弦相似度距离:

更新前:
In [1]:cosine_similarity([3,4],[3,6])
Out[1]: 98.39更新后:
In [1]:cosine_similarity([x1,y1],[x2,y2])
Out[1]: 98.39已经很接近了所以几乎没变。
再看看 输入 天气 输出 今天 的相似度变化:
更新前:
In [1]:cosine_similarity([3,4],[1,4])
Out[1]: 92.16更新后:
In [1]:cosine_similarity([x1,y1],[x2,y2])
Out[1]: 92.12从结果来看,因为不是期望的输出,所以距离越来越远了。
2.CBOW
还是以上面例子为例:
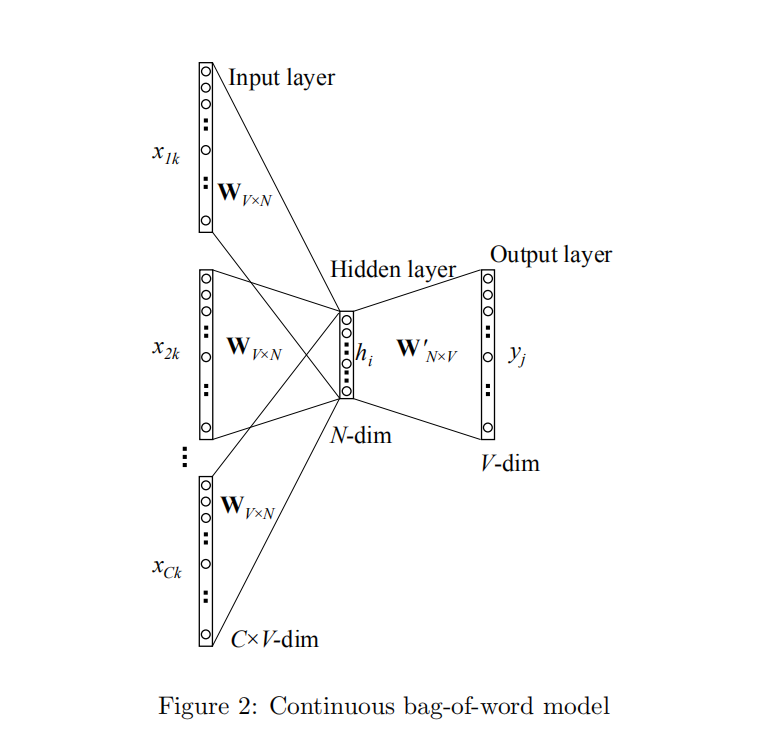
由3个单词组成的句子:
- 今天······[1,0,0]
- 天气······[0,1,0]
- 不错······[0,0,1]
不过我们的规则变为:
当给予附近单词,来预测中心单词?
对应这里就是给予 今天/不错 来预测 中心词是 天气 的概率。
接着依然初始化一下输入矩阵和输出矩阵
:
由公式可以得到:
(emmm,运气这么好,凑的结果与之前一模一样....因为h的值与前面one-word-text的一样,推到更新过程也是一模一样的,使用就不写了,其实就是复制上面的粘贴下来)
---------------------------略---------------------------
3.skip-gram
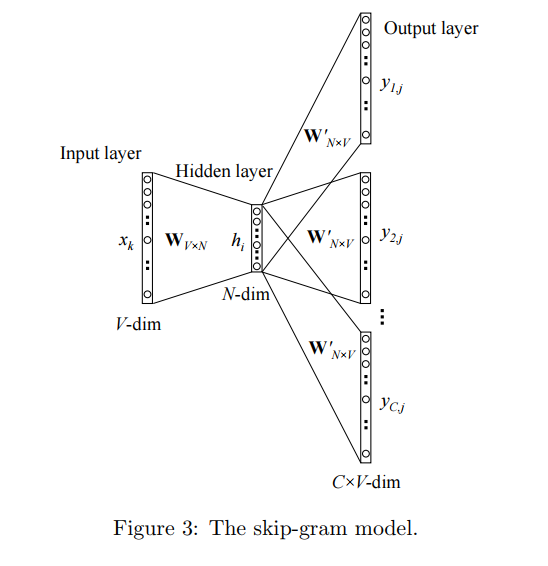
在skip-gram中我们的规则变为:
当给予中心单词,来预测附近单词?
对应这里就是给予 天气 来预测 附近词是 今天,不错 的概率。
