就库的范围,个人认为网络爬虫必备库知识包括urllib、requests、re、BeautifulSoup、concurrent.futures,接下来将结对concurrent.futures库的使用方法进行总结
建议阅读本博的博友先阅读下上篇博客: python究竟要不要使用多线程,将会对concurrent.futures库的使用有帮助。
1. concurrent.futures库简介
python标准库未我们提供了threading和mutiprocessing模块实现异步多线程/多进程功能。从python3.2版本开始,标准库又为我们提供了concurrent.futures模块来实现线程池和进程池功能,实现了对threading和mutiprocessing模块的高级抽象,更大程度上方便了我们python程序员。
concurrent.futures模块提供了ThreadPoolExecutor和ProcessPoolExecutor两个类
(1)看下来个类的继承关系和关键属性
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor print('ThreadPoolExecutor继承关系:',ThreadPoolExecutor.__mro__) print('ThreadPoolExecutor属性:',[attr for attr in dir(ThreadPoolExecutor) if not attr.startswith('_')]) print('ProcessPoolExecutor继承关系:',ProcessPoolExecutor.__mro__) print('ThreadPoolExecutor属性:',[attr for attr in dir(ProcessPoolExecutor) if not attr.startswith('_')])

都继承自futures._base.Executor类,拥有三个重要方法map、submit和shutdow,这样看起来就很简单了
(2)再看下futures._base.Executor基类实现


class Executor(object): """This is an abstract base class for concrete asynchronous executors.""" def submit(self, fn, *args, **kwargs): """Submits a callable to be executed with the given arguments. Schedules the callable to be executed as fn(*args, **kwargs) and returns a Future instance representing the execution of the callable. Returns: A Future representing the given call. """ raise NotImplementedError() def map(self, fn, *iterables, timeout=None, chunksize=1): """Returns an iterator equivalent to map(fn, iter). Args: fn: A callable that will take as many arguments as there are passed iterables. timeout: The maximum number of seconds to wait. If None, then there is no limit on the wait time. chunksize: The size of the chunks the iterable will be broken into before being passed to a child process. This argument is only used by ProcessPoolExecutor; it is ignored by ThreadPoolExecutor. Returns: An iterator equivalent to: map(func, *iterables) but the calls may be evaluated out-of-order. Raises: TimeoutError: If the entire result iterator could not be generated before the given timeout. Exception: If fn(*args) raises for any values. """ if timeout is not None: end_time = timeout + time.time() fs = [self.submit(fn, *args) for args in zip(*iterables)] # Yield must be hidden in closure so that the futures are submitted # before the first iterator value is required. def result_iterator(): try: # reverse to keep finishing order fs.reverse() while fs: # Careful not to keep a reference to the popped future if timeout is None: yield fs.pop().result() else: yield fs.pop().result(end_time - time.time()) finally: for future in fs: future.cancel() return result_iterator() def shutdown(self, wait=True): """Clean-up the resources associated with the Executor. It is safe to call this method several times. Otherwise, no other methods can be called after this one. Args: wait: If True then shutdown will not return until all running futures have finished executing and the resources used by the executor have been reclaimed. """ pass def __enter__(self): return self def __exit__(self, exc_type, exc_val, exc_tb): self.shutdown(wait=True) return False
提供了map、submit、shutdow和with方法,下面首先对这个几个方法的使用进行说明
2. map函数
函数原型:def map(self, fn, *iterables, timeout=None, chunksize=1)
map函数和python自带的map函数用能类型,只不过该map函数从迭代器获取参数后异步执行,timeout用于设置超时时间
参数chunksize的理解:
The size of the chunks the iterable will be broken into before being passed to a child process. This argument is only used by ProcessPoolExecutor; it is ignored by ThreadPoolExecutor.
例:
from concurrent.futures import ThreadPoolExecutor import time import requests def download(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Connection':'keep-alive', 'Host':'example.webscraping.com'} response = requests.get(url, headers=headers) return(response.status_code) if __name__ == '__main__': urllist = ['http://example.webscraping.com/places/default/view/Afghanistan-1', 'http://example.webscraping.com/places/default/view/Aland-Islands-2'] pool = ProcessPoolExecutor(max_workers = 2)
start = time.time() result = list(pool.map(download, urllist)) end = time.time() print('status_code:',result) print('使用多线程--timestamp:{:.3f}'.format(end-start))
3. submit函数
函数原型:def submit(self, fn, *args, **kwargs)
fn:需要异步执行的函数
args、kwargs:函数传递的参数
例:下例中future类的使用和as_complete后面介绍
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor,as_completed import time import requests def download(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Connection':'keep-alive', 'Host':'example.webscraping.com'} response = requests.get(url, headers=headers) return response.status_code if __name__ == '__main__': urllist = ['http://example.webscraping.com/places/default/view/Afghanistan-1', 'http://example.webscraping.com/places/default/view/Aland-Islands-2'] start = time.time() pool = ProcessPoolExecutor(max_workers = 2) futures = [pool.submit(download,url) for url in urllist] for future in futures: print('执行中:%s, 已完成:%s' % (future.running(), future.done())) print('#### 分界线 ####') for future in as_completed(futures, timeout=2): print('执行中:%s, 已完成:%s' % (future.running(), future.done())) print(future.result()) end = time.time() print('使用多线程--timestamp:{:.3f}'.format(end-start))
输出:
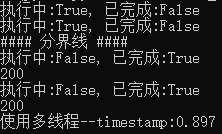
4. shutdown函数
函数原型:def shutdown(self, wait=True)
此函数用于释放异步执行操作后的系统资源
由于_base.Executor类提供了上下文方法,将shutdown封装在了__exit__中,若使用with方法,将不需要自己进行资源释放
with ProcessPoolExecutor(max_workers = 2) as pool:
5. Future类
submit函数返回Future对象,Future类提供了跟踪任务执行状态的方法:
future.running():判断任务是否执行
futurn.done:判断任务是否执行完成
futurn.result():返回函数执行结果
futures = [pool.submit(download,url) for url in urllist] for future in futures: print('执行中:%s, 已完成:%s' % (future.running(), future.done())) print('#### 分界线 ####') for future in as_completed(futures, timeout=2): print('执行中:%s, 已完成:%s' % (future.running(), future.done())) print(future.result())
as_completed方法传入futures迭代器和timeout两个参数
默认timeout=None,阻塞等待任务执行完成,并返回执行完成的future对象迭代器,迭代器是通过yield实现的。
timeout>0,等待timeout时间,如果timeout时间到仍有任务未能完成,不再执行并抛出异常TimeoutError
6. 回调函数
Future类提供了add_done_callback函数可以自定义回调函数:
def add_done_callback(self, fn): """Attaches a callable that will be called when the future finishes. Args: fn: A callable that will be called with this future as its only argument when the future completes or is cancelled. The callable will always be called by a thread in the same process in which it was added. If the future has already completed or been cancelled then the callable will be called immediately. These callables are called in the order that they were added. """ with self._condition: if self._state not in [CANCELLED, CANCELLED_AND_NOTIFIED, FINISHED]: self._done_callbacks.append(fn) return fn(self)
例子:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor,as_completed import time import requests def download(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Connection':'keep-alive', 'Host':'example.webscraping.com'} response = requests.get(url, headers=headers) return response.status_code def callback(future): print(future.result()) if __name__ == '__main__': urllist = ['http://example.webscraping.com/places/default/view/Afghanistan-1', 'http://example.webscraping.com/places/default/view/Aland-Islands-2', 'http://example.webscraping.com/places/default/view/Albania-3', 'http://example.webscraping.com/places/default/view/Algeria-4', 'http://example.webscraping.com/places/default/view/American-Samoa-5'] start = time.time() with ProcessPoolExecutor(max_workers = 2) as pool: futures = [pool.submit(download,url) for url in urllist] for future in futures: print('执行中:%s, 已完成:%s' % (future.running(), future.done())) print('#### 分界线 ####') for future in as_completed(futures, timeout=5): future.add_done_callback(callback) print('执行中:%s, 已完成:%s' % (future.running(), future.done())) end = time.time() print('使用多线程--timestamp:{:.3f}'.format(end-start))
7. wait函数
函数原型:def wait(fs, timeout=None, return_when=ALL_COMPLETED)
def wait(fs, timeout=None, return_when=ALL_COMPLETED): """Wait for the futures in the given sequence to complete. Args: fs: The sequence of Futures (possibly created by different Executors) to wait upon. timeout: The maximum number of seconds to wait. If None, then there is no limit on the wait time. return_when: Indicates when this function should return. The options are: FIRST_COMPLETED - Return when any future finishes or is cancelled. FIRST_EXCEPTION - Return when any future finishes by raising an exception. If no future raises an exception then it is equivalent to ALL_COMPLETED. ALL_COMPLETED - Return when all futures finish or are cancelled. Returns: A named 2-tuple of sets. The first set, named 'done', contains the futures that completed (is finished or cancelled) before the wait completed. The second set, named 'not_done', contains uncompleted futures. """ with _AcquireFutures(fs): done = set(f for f in fs if f._state in [CANCELLED_AND_NOTIFIED, FINISHED]) not_done = set(fs) - done if (return_when == FIRST_COMPLETED) and done: return DoneAndNotDoneFutures(done, not_done) elif (return_when == FIRST_EXCEPTION) and done: if any(f for f in done if not f.cancelled() and f.exception() is not None): return DoneAndNotDoneFutures(done, not_done) if len(done) == len(fs): return DoneAndNotDoneFutures(done, not_done) waiter = _create_and_install_waiters(fs, return_when) waiter.event.wait(timeout) for f in fs: with f._condition: f._waiters.remove(waiter) done.update(waiter.finished_futures) return DoneAndNotDoneFutures(done, set(fs) - done)
wait方法返回一个中包含两个元组,元组中包含两个集合(set),一个是已经完成的(completed),一个是未完成的(uncompleted)
它接受三个参数,重点看下第三个参数:
FIRST_COMPLETED:Return when any future finishes or iscancelled.
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor,\ as_completed,wait,ALL_COMPLETED, FIRST_COMPLETED, FIRST_EXCEPTION import time import requests def download(url): headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0', 'Connection':'keep-alive', 'Host':'example.webscraping.com'} response = requests.get(url, headers=headers) return response.status_code if __name__ == '__main__': urllist = ['http://example.webscraping.com/places/default/view/Afghanistan-1', 'http://example.webscraping.com/places/default/view/Aland-Islands-2', 'http://example.webscraping.com/places/default/view/Albania-3', 'http://example.webscraping.com/places/default/view/Algeria-4', 'http://example.webscraping.com/places/default/view/American-Samoa-5'] start = time.time() with ProcessPoolExecutor(max_workers = 2) as pool: futures = [pool.submit(download,url) for url in urllist] for future in futures: print('执行中:%s, 已完成:%s' % (future.running(), future.done())) print('#### 分界线 ####') completed, uncompleted = wait(futures, timeout=2, return_when=FIRST_COMPLETED) for cp in completed: print('执行中:%s, 已完成:%s' % (cp.running(), cp.done())) print(cp.result()) end = time.time() print('使用多线程--timestamp:{:.3f}'.format(end-start))
输出:
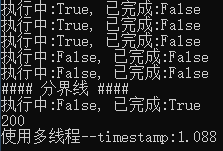
只返回了一个完成的