概述
首先来说几个概念:
字符:是各种文字和符号的总称,包括国家文字、标点符号、图形符号、数字等。
字符集:是多个字符的集合。常见字符集有:ASCII、GBK、BIG5、Unicode等。
我们知道在计算机的世界里,所有的东西最终都表示为二进制的比特流。一个二进制叫做位,8位成为“字节”,根据计算一个字节一共可组合出256(2的8次方)种不同的状态。
在计算机存储字符时,就需要对字符进行编码,字符与编码出的二进制流必须要一一对应,要不之后就还原不了信息。在电脑的发明国美国,所有的字符(英文大小写、数字、符号等)使用127种状态就能表示出来,于是大家都把这个方案叫做"ASCII"编码(American Standard Code For Information Interchange,美国信息互换标准)。
随着计算机的发展,世界各地都开始使用计算机,但是很多国家用的不是英语,于是就开始给127之后的状态进行编码,从128到255这一页的字符集被称为“扩展字符集”。
对于一些国家256种字节状态还是满足不了需要,比如中国的汉字有十万多,常用的也要6000,聪明的中国人民就对ASCII进行了中文扩展,使用了双字节的方式对汉字进行了编码(具体的编码方式可以上网去查,这不重要),这样我们组合了常用的大约6000多个简体汉字,于是我们叫这种汉字方案叫做“GB2312”。之后又对GB2312进行了扩展,增加了一些不常用字符,形成了“GBK”标准。后来又在GBK基础上增加了少数民族的字符,GBK扩展成了“GB18030”。
类似于中国,其它国家也相应的制定了自己的编码标准,比如BIG5等,这样的结果就是不同的编码之间谁也不懂谁的编码。如果你在中国使用计算机编写了一份中文文档,拿到韩国打开就成乱码了。于是一些组织就开始着手统一编码格式,然后就出现了Unicode和USC字符集。
Unicode和USC字符集
Unicode是由Unicode Consortium组织制定的一种计算机行业标准,用于世界上大多数语言(书写系统中表达的文本)进行一致编码、表示和处理。于1990年开始研发,1994年正式公布。
USC是由ISO制定的一种计算机行业标准,跟Unicode的目的是一样的。
在1991年前后,双方都认识到世界不需要两个不兼容的字符集。于是它们开始合并双方的工作成果,并为创立一个统一编码表而协同工作。这个编码表相当于一个数据库,里面存储着每一个字符对应的唯一ID,统一用U+XXXX来表示(X为16进制的字符),如 【很】U+E5BE88、【知】U+77E5。现在这个数据库已经拥有100多万的字符,还在不停的更新。之前介绍的各个编码标准之间不兼容的问题就是这个编码表没有进行统一,各个国家拥有自己的标准导致的。
知道了这么多,让我们重新看两个概念:
字符集:为每一个字符分配一个唯一的ID(学名为码位/码点/Code Point)。
字符编码:将 [码位] 转换为字节序列的规则(即将字符对应编码表中的数据转换成0101010101)。
有时我们提到了某一种字符集,其实它隐式地指明了字符编码,如GB2312或者ASCII。
介绍完字符集,下面看看字符编码。
字符编码
字符编码说白了就是对字符对应的ID转换为计算机认识的0101010101。对于各个国家的字符编码就没必要介绍了,大家都不统一,我也搞不明白,现在主要介绍Unicode和USC对应的字符编码。
UniCode有多种字符编码方式,其中主要的是:UTF-8、UTF-16、UTF-32
USC主要的字符编码方式有:USC-2、USC-4
其中USC-2、USC-4、UTF-32是定长字符编码,UTF-8和UTF-16是可变长度字符编码(一个字符可用1-4个字节表示)
UTF-8
UTF-8是可变长度的字符编码,能够使用1~4个8位字节对编码表中的有效代码点进行编码,它被设计成向后兼容,Unicode的前128个字符与ASCII一一对应,所以有效的ASCII文本也是有效的UTF-8编码。UTF-8是互联网上使用最广的字符编码规则,占所有网页的92%左右。
UTF-8中的8意思是以8位为一个编码单元进行的编码,同理UTF-16就是以16位为一个单元进行编码。为了更好的理解后面所介绍的内容,这里介绍一下UTF-8的编码规则。
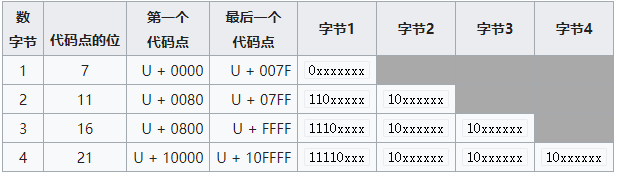
上图的意思是:
编码之后占1个字节的对应码点范围为U+0000 ~ U+007F,转换之后的二进制数据为0xxxxxxx
编码之后占2个字节的对应码点范围为U+0080 ~ U+07FF,转换之后的二进制数据为110xxxxx 10xxxxxxx
以此类推…
举个简单的例子:【知】的码位是U+77E5,看图可得到编码之后占三个字节,如下图:

这样将U+77E5进行UTF-8字符编码之后就变成了OXE79FA5。
总结一下UTF-8的编码规则其实就两点:
① 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
② 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
UTF-16
UTF-16也是一种可变长度的字符编码,因为代码点使用一个或两个16位的编码单元进行编码,所以主要占2个或4个字节。
UTF-16源于早起的固定宽度16位编码USC-2(后面介绍),因为USC-2只能表示65535个字符,不能满足需求就对它进行了扩展,形成了UTF-16。下面对UTF-16的编码进行简单的介绍:
1. 基本多语言平面(码点在U+0000~U+FFFF的)
码点范围为U+0000 到 U+FFFF的,包含了最常见字符,UTF-16将这个范围内的码位编码为2个字节,数值等于对应的Unicode码位,即0x0000~0xFFFF。
2. 辅助平面(码点在U+010000~U+10FFFF)
码位范围为U+10000到U+10FFFF,UTF-16将这个范围内的码位编码为4个字节,称为代理对(surrogate pair)。
具体的编码方式如下:
码位减去0x10000,得到的值的范围为0x00000至0xFFFFF,长度为20个比特;
高位的10比特的值(0至0x3FF)加上0xD800得到第一个码元或称作高位代理(high surrogate),值的范围是0xD800至0xDBFF;由于高位代理比低位代理的值要小,所以为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates);
低位的10比特的值(0至0x3FF)加上0xDC00得到第二个码元或称作低位代理(low surrogate),值的范围是0xDC00至0xDFFF;由于低位代理比高位代理的值要大,所以为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
综上所述,前导代理、后尾代理和基本语言平面的码位,三者互不重叠,因此可以通过检查一个码元就可以判定给定字符的下一个字符的起始码元,这意味着UTF-16是自同步的。
例如U+10437编码:
大于0xFFFF,采用4个字节进行编码;
0x10437减去0x10000,结果为0x00437,二进制为0000 0000 0100 0011 0111。
分区它的上10位值和下10位值(使用二进制):0000000001 and 0000110111。
添加0xD800到上值,以形成高位:0xD800 + 0x0001 = 0xD801。
添加0xDC00到下值,以形成低位:0xDC00 + 0x0037 = 0xDC37。
综合之后得到的UTF-16为0x D8 01 DC 37
USC-2
USC-2是固定2个字节长度的字符编码,平时所说的Unicode编码其实隐式的说的就是USC-2字符编码。它是两个组织合并支出的产物。
Unicode的码空间从U+0000到U+10FFFF,共有1,112,064个码位(code point)可用来映射字符. Unicode的码空间可以划分为17个平面(plane),每个平面包含216(65,536)个码位。每个平面的码位可表示为从U+xx0000到U+xxFFFF, 其中xx表示十六进制值从0016 到1016,共计17个平面。
第一个Unicode平面(码位从U+0000至U+FFFF)包含了最常用的字符,该平面被称为基本多语言平面(Basic Multilingual Plane),缩写为BMP。其他平面称为辅助平面(Supplementary Planes)。
USC-2的编码就是对应的基本多语言平面,不够2个字节的使用0把高位补齐。所以有一些字符使用USC-2是无法存储的。
UTF-32和USC-4
UTF-32和USC-4一样是固定4个字节长度的字符编码。因为统一的编码表也是4个字节32位的,所以编码就是一一对应,不够32位的高位补0,比如字母“A”用UTF-8编码1个字节就可以,使用UTF-32就要用0补足高位形成4个字节。这样对于存储和传输都很不友好,所以很少使用。
乱序的原因
简单的说乱码的出现是因为:编码和解码时用了不同或者不兼容的字符集。对应到真实生活中,就好比是一个英国人为了表示祝福在纸上写了bless(编码过程)。而一个法国人拿到了这张纸,由于在法语中bless表示受伤的意思,所以认为他想表达的是受伤(解码过程)。这个就是一个现实生活中的乱码情况。在计算机科学中一样,一个用UTF-8编码后的字符,用GBK去解码。由于两个字符集的字库表不一样,同一个汉字在两个字符表的位置也不同,最终就会出现乱码。
我们来看一个例子:假设我们用UTF-8编码存储很屌两个字,会有如下转换:
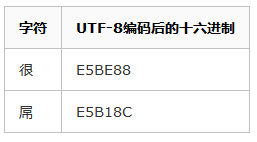
于是我们得到了E5BE88E5B18C这么一串数值。而显示时我们用GBK解码进行展示,通过查表我们获得以下信息:
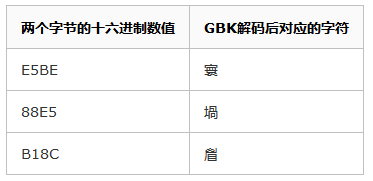
解码后我们就得到了“寰堝睂”这么一个错误的结果。
说一下一个小的问题:
Windows下默认的是ANSI格式保存,Linux默认的是UTF-8格式保存,所以有的Windows文件放到Linux系统下会乱码。解决办法可以把文件按照一种编码方式保存,或者修改系统的默认编码格式。
Windows记事本里面四种存储格式对应的字符编码
通过以上的介绍,估计大家都知道了字符编码的问题,咱现在就来看看Windows平台下记事本程序里面的编码格式,先看下图:
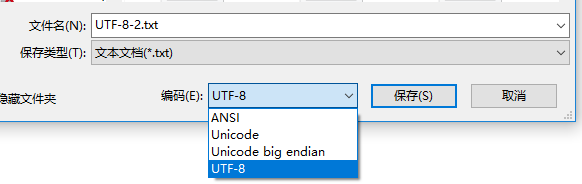
这里有四个选项:ANSI、Unicode、Unicode big endian、UTF-8
- ANSI:相当于“本地编码”,如果为英文就是ASCII编码,如果超出两个字节就用本地编码,即中国用GBK,台湾用BIG5,日本用JIS。
- Unicode:使用的UCS-2编码,使用的是little endian(小端)存储。
- Unidoe big endian:使用的USC-2编码,不过使用的big endian(大端)储存。
- UTF-8:顾名思义,使用的UTF-8格式存储。
关于大端小端的问题,大家可以自行查阅资料了,若有机会我在整理一下
好了就写到这了,有不对的地方希望大家指正。
感谢大家,我是假装很努力的YoungYangD(小羊)。
参考文章:
https://www.cnblogs.com/happyday56/p/4135845.html
https://en.wikipedia.org/wiki/Unicode
https://en.wikipedia.org/wiki/Universal_Coded_Character_Set
https://en.wikipedia.org/wiki/UTF-16
https://en.wikipedia.org/wiki/UTF-8
https://www.zhihu.com/question/23374078
https://www.jianshu.com/p/7ae9005e0671