文章目录
本文对 计算机领域中的字符,字符集和字符编码做简要介绍。
一、字符
字符是一个信息单位,包括 文字、数字、符号(包括标点符号,图形符号,控制字符)等,是用来给人显示的(控制字符也可以看做是控制显示格式), 是数据结构中最小的数据存取单位。
二、字库
所有可显示字符的集合。
三、字符集
1、产生背景
计算机需要将字符转换成二进制后,才能对字符做处理。
2、定义
字符集,字符的集合和计算机二进制序列间的映射关系。
3、举例
1) ASCII
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码),最早的字符集。
用8个bit存储,第一位规定为0,用后面7个bit表示128个字符,包含常见英文字符和一些控制符号。
2) ANSI
为了能表示英语之外的其他语言,利用闲置的最高位编入信道符号,是ASCII的扩展。
用8个bit存储,最多256个符号,其中0~127个符号和ASCII相同, 128~255是相对ASCII的扩展,被称为“扩展字符集”。ISO组织制定了一系列的字符编码: ISO-8859-1~ISO-8859-15。其中,ISO-8859-1(又称Latin-1)涵盖了大多数西欧语言字符,所有应用的最广泛。
3) Unicode
为了整合全世界的所有语言文字而诞生,全称是Universal Multiple-Octet Coded Character Set。也即UCS (Universal Character Set)(还有其他的以整合所有为目的的字符集,后来大家达成共识,使用UCS作为Unicode字符集)。
-
UCS-2
用
2个字节编码。 -
UCS-4
用
4个字节编码,最高位为0。UCS-4将最高位分成27=128个Group,每个Group再根据第2个字节分为28=256个Plane,每个Plane根据第3个字节分成256个Row,每个Row又根据第4个字节分成256个Cell。

其中,Group 0 的Plane 0 (高两个字节为0) 的码被称为 Basic Multilingual Plane,即BMP。
将BMP去掉前面的两个零字节就得到了UCS-2。而目前的UCS-4规范中还没有任何字符被分配在BMP之外。
4) 中文字符集
GB,即GuoBiao(国标)的缩写,是中文汉字对应的字符集。
GB系列编码中的区位码可以认为是字符集。
四、字符编码
1、产生原因
为更加适应计算机存储、网络传输,直接按照字符集存储并不合适,需要对字符集中定义的序号(二进制序列)再次转换,这便产生了字符编码。
2、定义
字符编码,规定了如何编码、存储这些字符对应的二进制序列。
3、举例
1) ASCII
直接以ASCII字符集中规定的字符和序列间的对应方式存储和传输字符。
2) ANSI
直接以ANSI字符集中规定的字符和序列间的对应方式存储和传输字符。
3) UTF
UTF(Unicode/UCS,Transformation Format),Unicode 字符集对应的字符编码。
Unicode用两个或四个字节表示一个字符,使得很多英文字母前面的编码都是0,浪费系统资源。因此产生了UTF编码。
-
UTF-8
使用
变长(1~4个字节)的编码方式,即根据不同符号而变化字节长度,以是的最长出现的字符编码尽量的短。其编码规则为:- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于
英语字母,UTF-8编码和ASCII码是相同的。 - 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。单字节编码的第一字节为00-7F,双字节编码的第一字节为C2-DF,三字节编码的第一字节为E0-EF。
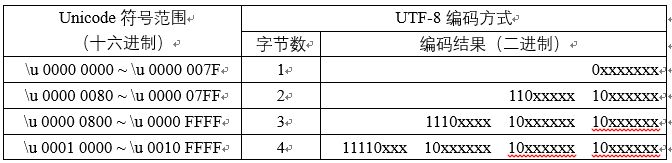
因此,UTF-8有如下特点:
- 只要一看到
第一个字节的范围就可以知道编码的字节数,大大简化编解码算法; - 不再需要BOM字节表明字节顺序,但可以用BOM表明编码方式。字符"Zero Width No-Break Space"的UTF-8编码是EF BB BF,所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码。Windows就是使用BOM来标记文本文件的编码方式的,但实际上,由于一些软件、语言和受COOKIE送出机制的限制等并不能识别或者使用BOM头,因此为避免出错,
不建议UTF-8格式的文件使用BOM。如果非要使用UTF-8的话,只包含英文字符(或者说ASCII编码内的字符)时,可以把文件存成ASCII码方式;包含中文字符时,可以将文件另存为“UTF-8 无 BOM”
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的Unicode码。因此对于
-
UTF-16
由RFC2781协议规定。使用
两个字节或四个字节表示一个字符,使用两个字节表示时,和UCS-2中规定的字符和序列间的关系基本相同;使用四个字节表示时,UTF-16能表示一部分的UCS-4字符(\u10000~\u10FFFF)。UTF-16可以分为三种:-
UTF-16
需要在文件开头以
BOM (Byte Order Mark)的字符来表明文件是Big Endian还是Little Endian(详见字节序(大端&小端))。 -
UTF-16BE(Big Endian)
-
UTF-16LE(Little Endian)
举例: “ABC” 这三个字符用各种方式编码后的结果如下:

-
-
UTF-32
使用
四个字节表示字符,可以完全表示UCS-4的所有字符,而无需向UTF-16那样使用复杂算法才能表示一些UCS-4字符。UTF-16可以分为三种:-
UTF-32
需要在文件开头以
BOM (Byte Order Mark,字节顺序的标识)的字符来表明文件是Big Endian还是Little Endian(详见字节序(大端&小端))。 -
UTF-32BE(Big Endian)
-
UTF-32LE(Little Endian)
举例: "ABC"这三个字符用各种方式编码后的结果如下:

-
4) GB系列
GB,即GuoBiao(国标)的缩写,是中文汉字对应的字符集。
-
GB2312
用16个bit(2个bite),表示中文常见字和一些符号。
同时
兼容单字节ASCII编码,可以理解是单字节和双字节混合的变长编码。 -
GBK1.0
兼容GB2312,收纳了更多的文字和符号。目前
使用最广泛。同时
兼容单字节ASCII编码,可以理解是单字节和双字节混合的变长编码。 -
GB18030
兼容GB2312和GBK,收纳了更多的文字和符号,是
国家正式标准。变长编码,采用
单字节、双字节和四字节方案。其中,单字节、双字节和GBK是完全兼容的,四字节是扩展。
4、使用
-
操作系统
UTF-8:大多Linux系统、Mac OS默认编码
GBK:中文版Windows系统默认编码
-
shell
对于单机系统而言,终端编码
与操作系统编码一般是一致的,但在远程登录时,可能会遇到一些问题. -
文本文件
大多可选
-
程序
与具体的编程语言相关,涉及到程序运行时变量在内存中的状态。
如,Java和Python3里,字符均采用Unicode编码(Java.lang.String 采用 UTF-16 编码方式存储所有字符),因此可以很好地支持中文。但是,Python2中Unicode不是字符默认编码格式(Python从2.2才开始支持Unicode),因此需要进行编码的转换。函数decode( char_set )可以实现其它编码到Unicode的转换,函数encode( char_set )可以实现Unicode到其它编码方式的转换。这里所讲的Unicode String是指 UCS-2或者UCS-4 编码的Code Points。注意,只有字符到字节或者字节到字符的转换才存在编码、转码的概念。
常见问题
字符集V.S.字符编码
字符编码可以看作是字符集的一种实现,或者二次编码,因此,一个字符集可以对应多种字符编码。
如果对于某一个字符集,如果其存储和编码方式就是字符集中定义的字符和二进制序列间的要求,那么字符集和字符编码就是一样的。如:ASCII和ANSI。
MySQL中的utf8和utf8mb4
- MySQL 的“utf8mb4”是真正的“UTF-8”。
- MySQL 的“utf8”是一种“专属的编码”,它能够编码的 Unicode 字符并不多。
为什么使用Unicode存储,使用UTF-8传输?
- 为什么使用Unicode存储?
首先,“使用Unicode存储”这种说法并不完全正确,确切地应该说是“使用定长UTF-16存储”。原因如下。
起初,Unicode是Windows对自己使用的定长16比特LE编码的命名,计算机也确实是使用Unicode(定长16比特LE)存储的。但是后来中文字符的引入,使得Unicode不得不升级成32位(不再是原来16位编码格式)才能包含所有字符。并且定义了UTF-16表示16bit定长编码,并且将部分Unicode中的32位编码加入到了UTF-8,变成了不定长编码。不过,现在计算机的存储,一般仍采用之前的定长UTF-16,不过一直沿用使用Unicode编码存储这种说法。采用定长UTF-16便于计算机快速读取数据,并且覆盖了大部分常用字符。 - 为什么使用UTF-8传输?
UTF-8在传输ANSI字符的时候,非常节省空间,于是在数据传输中经常使用。但是在计算机中存储时,不定长的编码规则需要计算机先要从头扫描一遍,才能知道每个字符的位置,非常浪费时间。
base64和UTF的区别?
参考文献
https://zh.wikipedia.org/zh-cn/%E5%AD%97%E7%AC%A6_(%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%A7%91%E5%AD%A6) 字符-维基百科
https://baike.baidu.com/item/%E5%AD%97%E7%AC%A6 字符-百度百科
https://dailc.github.io/2017/05/03/char_charset_charEncoding.html 字符,字符集,字符编码解惑
http://cenalulu.github.io/linux/character-encoding/ 十分钟搞清字符集和字符编码
https://www.zhihu.com/question/20152853/answer/95576659 对于字符编码,程序员的话应该了解它的那些方面?- 知乎
https://www.cnblogs.com/jy107600/p/7208455.html 关于UTF8文件带BOM头可能会引起的错误解析 - 博客
https://zhuanlan.zhihu.com/p/73971487 记住,永远不要在 MySQL 中使用“utf8” - 知乎
https://blog.csdn.net/fhzaitian/article/details/51482556 UTF-8格式编码与UTF-8无BOM格式编码的区别(包括java文件)- CSDN博客
https://www.zhihu.com/question/52346583/answer/130139771 计算机中为何不直接使用UTF-8编码进行存储而要使用Unicode再转成UTF-8?