1、元组(Tuple)
元组(Tuple),是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个value的List。
拓扑的每个节点必须声明emit(发射)的元组的输出字段。例如,下面的DoubleAndTripleBolt类在declareOutputFields方法中声明输出字段为["double","triple"]二元组。
- public class DoubleAndTripleBolt extends BaseRichBolt {
- private OutputCollectorBase _collector;
- @Override
- public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
- _collector = collector;
- }
- @Override
- public void execute(Tuple input) {
- int val = input.getInteger(0);
- _collector.emit(input, new Values(val*2, val*3));
- _collector.ack(input);
- }
- @Override
- public void declareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(new Fields("double", "triple"));
- }
- }
首先,在declareOutputFields方法中声明了输出为["double", "triple"]的二元组。接着,在prepare方法中把OutputCollectorBase对象赋给私有成员变量_collector。最后,使用_collector发射元组,输出元组是一个二元组,第一个值为原值的2倍,第二个值为原值的3倍,并使用_collector的ack方法,保证消息处理,提供可靠性机制。
2、流(Stream)
流(Stream)是Storm的核心抽象,是一个无界的元组序列。源源不断传递的元组就组成了流,在分布式环境中并行地进行创建和处理。
流被定义成一个为流中元组字段进行命名的模式,默认情况下,元组可以包含整型(integer)、长整型(long)、短整型(short)、字节(byte)、字符(string)、双精度数(double)、浮点数(float)、布尔值(boolean)和字节数组(byte array),还可以自定义序列化器,以便本地元组可以使用自定义类型。
流由元组组成,使用OutputFieldsDeclarer声明流及其模式。Serialization是Storm的动态元组类型的信息,声明自定义序列化。自定义序列化必须实现ISerialization接口,自定义序列化可以注册使用CONFIG.TOPOLOGY_SERIALIZATIONS这个配置。
Storm提供可靠的方式把原语转换成一个新的分布式的流,执行流转换的基本元素是Spout和Bolt。
Spout是流的源头,通常从外部数据源读取元组,并emit到拓扑中。例如,Spout从Kestrel队列中读取元组,并作为一个流提交到拓扑。
Bolt接收任何数量的输入流,执行处理后,可能提交新的流。复杂流的转换,如从tweets流中计算一个热门话题,需要多个步骤,因此需要多个Bolt。Bolt可以执行运行函数、过滤元组、连接流和连接数据库等任何事情。
如图所示,Spout和Bolt的网络被打包成一个“拓扑”,即顶级抽象,之后提交这个拓扑到Storm集群中执行。拓扑是一个图的流转换,节点表示Spout或Bolt,弧边指示哪些Bolt订阅了该流。当一个Spout或Bolt发射一个元组到一个流时,它会发射元组到每一个订阅该流的Bolt。
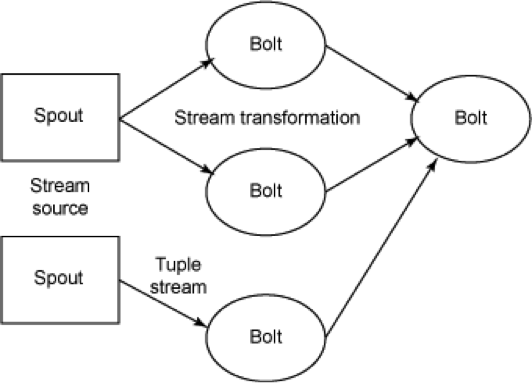
拓扑节点之间的连接表示元组应该如何传递。例如,如果从Spout A到Bolt B有一个连接,从Spout A到Bolt C有一个连接,从Bolt B到Bolt C有一个连接,那么每次Spout A将同时发射元组到Bolt B与Bolt C,Bolt B也会发射元组到Bolt C。
一个Storm拓扑中的每个节点均可以并行执行,也可以指定拓扑中跨集群执行的线程数量。
一个拓扑会一直运行,直到你杀死它。Storm会自动重新分配任何失败的任务。此外,即使主机已经关闭,消息已经被删除,Storm也能保证不会有数据丢失。
每个流被声明后都会赋予一个id。因为单个流的Spout和Bolt是如此普遍,OutputFieldsDeclarer有方便的方法来声明一个不指定id的单流。在这种情况下,流被赋予默认的id值。
3、喷口(Spout)
喷口(Spout)是拓扑的流的来源,是一个拓扑中产生源数据流的组件。通常情况下,Spout会从外部数据源(例如Kestrel队列或Twitter API)中读取数据,然后转换为拓扑内部的源数据。Spout可以是可靠的,也可以是不可靠的。如果Storm处理元组失败可靠的Spout能够重新发射,而不可靠的Spout就尽快忘记发出的元组。Spout是一个主动地角色,其接口中有一个nextTuple()函数,Storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
Spout可以发出超过一个流。为此,使用OutputFieldsDeclarer类的declareStream方法来声明多个流,使用SpoutOutputCollector类的emit执行流的提交。
Spout的主要方法是nextTuple()。nextTuple()会发出一个新的Tuple到拓扑,如果没有新的元组发出则简单地返回。nextTuple()方法不阻止任何Spout的实现,因为Storm在同一个线程调用所有的Spout方法。
Spout的其他主要方法是ack()和fail()。当Storm检测到一个元组从Spout发出时,ack()和fail()会被调用,要么成功完成通过拓扑,要么未能完成。ack()和fail()仅被可靠的Spout调用。IRichSpout是Spout必须实现的接口。
4、螺栓(Bolt)
在拓扑中的所有处理都在Bolt中完成,Bolt是流的处理节点,从一个拓扑接收数据然后执行进行处理的组件。Bolt可以完成过滤、业务处理、连接运算、连接与访问数据库等任何操作。Bolt是一个被动的角色,其接口中有一个execute()方法,在接收到消息后会调用此方法,用户可以在其中执行自己希望的操作。
Bolt可以完成简单的流的转换,而完成复杂的流的转换通常需要多个步骤,因此需要多个Bolt。例如,将tweet数据流转换为热门图片流至少需要两个步骤:首先一个Bolt为每个图像的转发做一个滚动的计数,然后一个或多个Bolt流找出排名前X的图片。
Bolt可以发出超过一个的流。为此,使用OutputFieldsDeclarer类的declareStream()方法声明多个流,并使用OutputCollector类的emit()方法指定发射的流。
当声明一个Bolt的输入流时,总是订阅另一个组件的特定流。如果想订阅另一个组件的所有的流,必须订阅每一个过程。InputDeclarer()方法有语法以订阅声明默认流id的流:declarer.shuffleGrouping("1")是指订阅组件1的默认流,相当于declarer.shuffleGrouping("1", DEFAULT_STREAM_ID)。
Bolt的主要方法是execute()方法,该方法将一个新的元组作为输入。Bolt使用OutputCollector对象发射新的元组。Bolt必须为它们处理的每个元组调用OutputCollector类的ack()方法,以便Storm知道什么时候元组会完成(并最终确定它是安全应答原始的Spout的元组)。对于处理一个输入元组的常见情况是发射0个或者更多基于该元组的元组,然后应答输入元组(Storm提供了一个自动应答的IBasicBolt接口)。
我们完全可以在Bolt中启动新的线程进行异步处理。OutputCollector类是线程安全的,可以在任何时间被调用。
IRichBolt是Bolt的通用接口。IBasicBolt是定义Bolt进行过滤或简单功能的一个很方便的接口。使用OutputCollector类的实例可以让Bolt发送元组到其输出流。
5、拓扑(Topology)
拓扑(Topology)是Storm中运行的一个实时应用程序,因为各个组件间的消息流动而形成逻辑上的拓扑结构。
把实时应用程序的运行逻辑打成jar包后提交到Storm的拓扑(Topology)。Storm的拓扑类似于MapReduce的作业(Job)。其主要区别是,MapReduce的作业最终会完成,而一个拓扑永远都在运行直到它被杀死。一个拓扑是一个图的Spout和Bolt的连接流分组。
在Java中,使用TopologyBuilder类来构造拓扑。
6、主控节点和工作节点
Storm集群中有两类节点:主控节点(Master Node)和工作节点(Worker Node)。其中,主控节点只有一个,而工作节点可以有多个。
7、Nimbus进程与Supervisor进程
主控节点运行一个称为Nimbus的守护进程,类似于Hadoop的JobTracker。Nimbus负责在集群中分发代码,对节点分配任务,并监视主机故障。
每个工作节点运行一个称为Supervisor的守护进程。Supervisor监听其主机上已经分配的主机的作业,启动和停止Nimbus已经分配的工作进程。
8、流分组(Streaming grouping)
流分组,是拓扑定义中的一部分,为每个Bolt指定应该接收哪个流作为输入。流分组定义了流/元组如何在Bolt的任务之间进行分发。
Storm内置了7种流分组方式,通过实现CustomStreamGrouping接口可以实现自定义的流分组。
9、工作线程(Worker)
Worker是Spout/Bolt中运行具体处理逻辑的进程。拓扑跨一个或多个Worker进程执行。每个Worker进程是一个物理的JVM和拓扑执行所有任务的一个子集。例如,如果合并并行度的拓扑是300,已经分配50个Worker,然后每个Worker将执行6个任务(作为在Worker内的线程)。Storm尝试在所有上均匀地发布任务。
可使用Config.TOPOLOGY_WORKERS配置项设置执行拓扑时分配的Worker的数量。
10、任务(Task)
Worker中每一个Spout/Bolt的线程成为一个任务(Task)。每个Spout或者Bolt在集群中执行许多任务。每个任务对应一个线程的执行,流分组定义如何从一个任务集到另一个任务集发射元组。可以通过TopologyBuilder类的setSpout()方法和setBolt()方法来设置每个Spout或者Bolt的并行度(parallelism)。
11、执行器(Executor)
在Storm 0.8以后,Task不再与物理线程对应,同一个Spout/Bolt的Task可能会共享一个物理线程,该线程称为执行器(Executor)。
12、可靠性(Reliability)
Storm保证每一个Spout元组将被拓扑完全可靠地处理。它跟踪每个Spout元组的元组树,检测树中的元组什么时候可以成功完成。每个拓扑都有“消息超时时间”,如果Storm在超时之前未能检测到Spout元组已经完成,那么会设元组为失败并在之后重新发射它。
要利用Storm的可靠性优势,当元组树的新边缘被创建时必须通知Storm,并告之Storm什么时候处理完该元组。这些都是通过使用OutputCollector对象实现的,Bolt使用OutputCollector对象发射元组。在emit()方法中完成Anchoring,声明已经使用ack()方法完成一个元组。