1、BP神经网络
1.1 神经网络基础
神经网络的基本组成单元是神经元。神经元的通用模型如图 1所示,其中常用的激活函数有阈值函数、sigmoid函数和双曲正切函数。 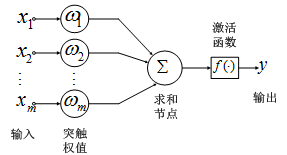
图 1 神经元模型
神经元的输出为:
神经网络是将多个神经元按一定规则联结在一起而形成的网络,如图 2所示。
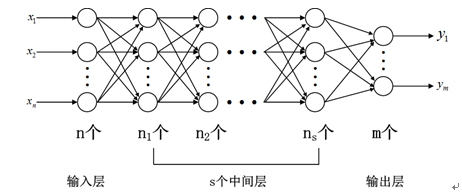
图 2 神经网络示意图
从图 2可以看出,一个神经网络包括输入层、隐含层(中间层)和输出层。输入层神经元个数与输入数据的维数相同,输出层神经元个数与需要拟合的数据个数相同,隐含层神经元个数与层数就需要设计者自己根据一些规则和目标来设定。在深度学习出现之前,隐含层的层数通常为一层,即通常使用的神经网络是3层网络。
以通用的神经网络模型来分析神经网络的输出。首先规定一些参数的意义:用 wl+1ijwijl+1 来表示第 l层第j 个节点和第l+1层第i个节点之间的权值,激活函数为f(x),第l层一共有 lnln 个节点,偏置参数 θlθl ,则第l+1层第j个节点的输出为:
设置一个中间变量 zl+1=∑lnj=1wl+1ijIl+1i+θlzl+1=∑j=1lnwijl+1Iil+1+θl ,而l+1层的输入与上一层对应神经元的输出是相同的,即 Il+1i=OliIil+1=Oil ,因此网络中某个神经元的输出可写如下等式:
第 l+1l+1 层的输出,又是下一层的输入。设一共有 mm 层网络(包含输出和输入),则网络输出层第i个节点的输出为:
由以上几个等式就可以得到从对应输入的输出层某个神经元的输出值。那怎么保证输出的值是所想要的?通常采用后向反馈方法,将误差层层传递,并利用梯度下降法更新每一层的参数,这就是BP神经网络。
1.2 后向反馈
假设网络的输入序列为: (x1,y1),(x2,y2),......,(xn,yn)(x1,y1),(x2,y2),......,(xn,yn) ,其中 yiyi 是 xixi 的期望输出,网络对应的实际输出为 aiai ,则其代价函数为:
定义输出层第 jj 个神经元的残差为:
更新参数的目的就是使得代价函数最小,即要代价函数对相应参数的偏导数为 00 。为了快速达到最小值,需要参数沿着梯度反方向更新:
其中 αα 是学习率。因此参数更新问题就转换成如何求偏导的问题。
代价函数与每一层每一个神经元的输入都相关,因此第 ll 层第 jj 个神经元的残差为:
第 l−1l−1 层第 ii 个神经元的残差为:
由前面分析可知, zljzjl 和 zl−1izil−1 相关,因此第 l−1l−1 层的残差为:
上式表明,当前层和下一层的残差满足一定的关系,因此可以通过输出层的残差逐层计算出每一层的残差。
根据残差,计算更新参数所需要的偏导数:
根据偏导就可以更新参数。
2、深度学习之卷积神经网络
2.1 卷积神经网络概要
卷积神经网络是基于动物视觉感受野设计而成,由卷积层、池化层和其他层构成。
BP神经网络中,每一层都是全连接的,假如输入是一幅1000*1000*1 的图像,则输入层与隐层某一个节点将有1000*1000 个权重需要训练,这会导致训练困难。而卷积神经网络的卷积层每个节点与上一层某个区域通过卷积核连接,而与这块区域以外的区域无连接。同样对于一副1000*1000*1的图像,采用10*10的卷积核,那么卷积层每个节点只需要训练100个节点;假若卷积核在图像上扫描的步长为1个像素,则卷积层需要991*991个节点,若每个节点对应不同的卷积核,则需要训练的参数依然是一个天文数字。为此,卷积神经网络提出了权值共享概念,即同一个卷积层内,所有神经元的权值是相同的,也就是用同一个卷积核生成卷积层上的所有节点。因此对于上面的训练,只需要训练100个权重。
池化层夹在卷积层中间,其主要作用逐步压缩减少数据和参数的数量,也在一定程度上减少过拟合现象。其操作是把上一层输入数据的某块区域压缩成一个值。
其他层:以前设计卷积神经网络时,在后面都有归一化层,用来模拟人脑的抑制作用,但是后来认为对最终的效果没什么帮助,就用的很少了;最后用的分类层是全连接层。
CNN的训练也采用前向和后向传播。
2.2 前向传播
(1)卷积层
卷积操作是用一个卷积核与图像对应区域进行卷积得到一个值,然后不断的移动卷积核和求卷积,就可完成对整个图像的卷积。在卷积神经网络中,卷积层的计算不仅涉及一般图像卷积概念,还有深度和步长的概念。深度决定同一个区域的神经元个数,也就是有几个卷积核对同一块区域进行卷积操作;步长是卷积核移动多少个像素。
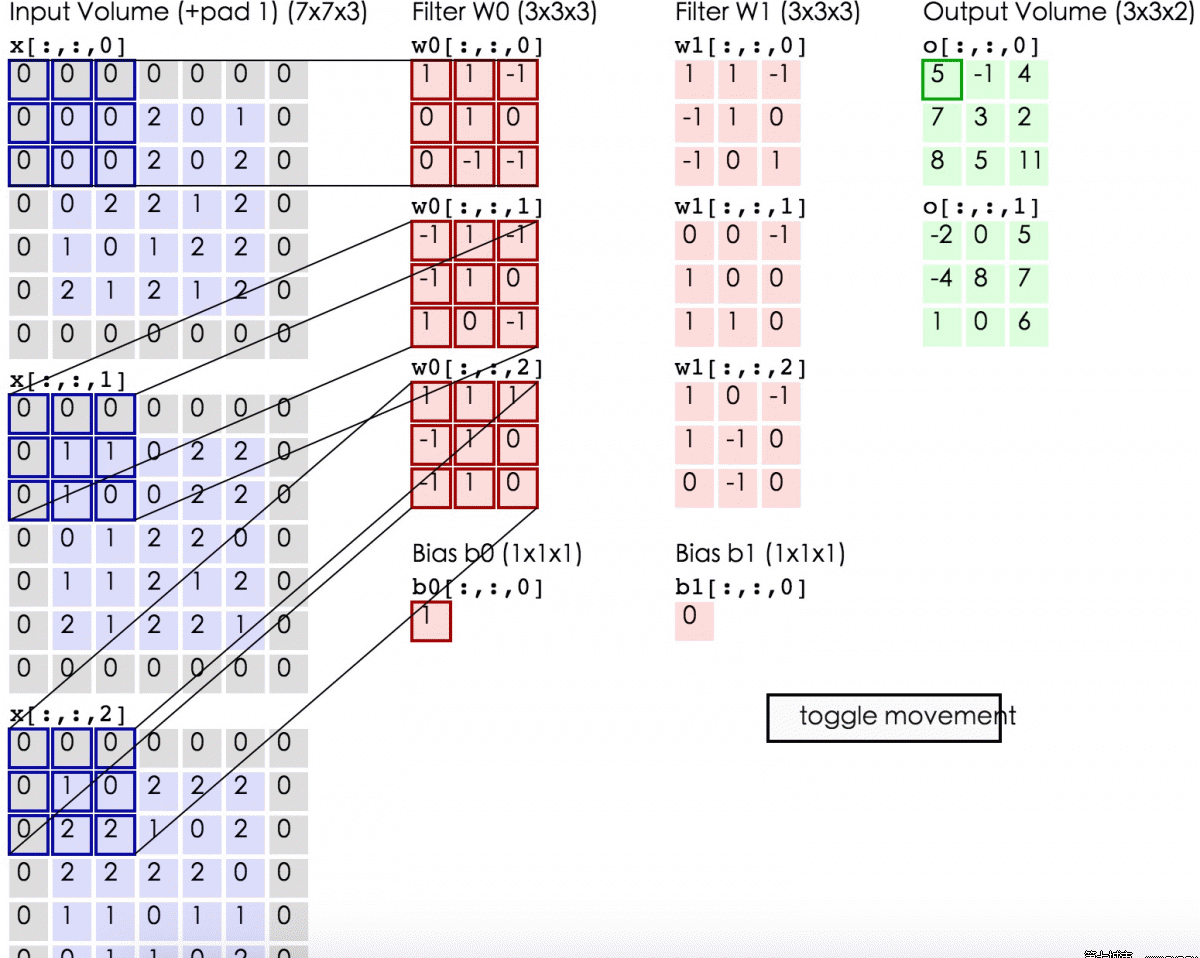
以一个例子来说明卷积层的具体操作。输入数据的大小为5*5*3,卷积核大小为3*3,输出的深度为2,如图 4所示。图中将输入数据在长宽方向进行了填0扩充。
图 4 卷积层操作例子
输入数据是一个3通道数据,因此卷积层每个深度的节点都有3个不同的卷积核,分别与输入的3个通道进行卷积,每个通道卷积后都得到一个值,也就是3个通道卷积完成后,有3个值,再把这3值和偏置求和就得到节点的值。每移动卷积核都进行这样的计算。在这篇博客中有卷积计算的动态图。
得到了卷积层每层深度的特征图后,需要将这些特征输入到激活函数中,从而得到卷积层最终的输出。神经网络中常用的sigmoid函数和双曲正切函数容易饱和,造成梯度消失。在CNN中采用的是另外一种激活函数:ReLU。
ReLU函数是有神经科学家Dayan、Abott从生物学角度,模拟脑神经元接受信号更精确的激活模型,其表达式为:
(2)池化层(下采样)
池化层现在通常采用区域最大值来代表整个区域,在最大值之前常采用的平均值。最大值操作如图 5所示。池化层操作主要涉及核大小的选择。
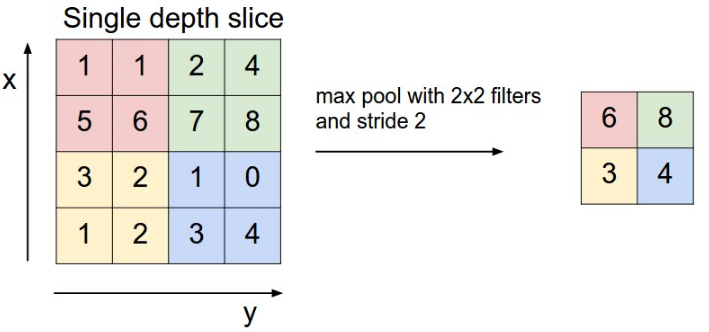
图 5 池化层操作
(3)全连接层
全连接层主要用来进行学习,和传统BP神经网络类似。CNN一般通常采用SoftMax方法进行分类。
2.3 后向传播(参照论文Notes on Convolutional Neural Networks)
学习的目的是获得对输入准确精炼的描述。影响输出结果的是每层的权重和偏置,因此为了达到目标,需要将输出误差层层传递回去,看每个参数对误差的影响,并因此调整参数。
(1)误差传递概述
对于输入数据对(x,y)(x,y),经过CNN网络处理,其输出为 aa。根据上面BP神经网络的分析可知,层的残差满足递推关系。但是卷积神经网络在结构上和bp神经网络不同,需要对CNN网络做一些处理,使得可以套用bp网络的公式。
(2)当前层(l)为卷积层
卷积层的输出是由若干个卷积核与上一层输出卷积之和,并将这些和通过激活函数而生成的:
其中 MjMj 表示选择的输入maps的集合。通常maps是人工选择的,也可以自动选择。
假设卷积层 的下一个是池化层 l+1l+1 。池化层输出的每一个像素都对应上一层(卷积层)的一个区域,即这两层之间不是全连接。因此需要对池化层的残差进行上采样(upsample)构造一个新的残差map,使得残差map和卷积层的map一致,然后再根据新池化层( l+1l+1 层)的残差计算卷积层的残差:
其中 up(⋅)up(⋅) 表示上采样: up(x)=x⨂1n×nup(x)=x⨂1n×n
则可以得到偏导:
可采用后向传播来计算该权重的偏导。因为权重是共享的,因此需要对与该核有联系的所有点对进行求梯度,然后对这些梯度进行求和:
其中 (pl−1i)uv(pil−1)uv 是 l−1l−1 层中与核逐元素相乘的区域。
(3)当前层为池化层
池化层的输入maps和输出maps个数相同,但是输出maps维数都减小了:
池化层的下一层是卷积层,必须要找到对应的区域,即找到当前层残差map对应下一层残差map的像素,这样就可以利用BP方法实现 δδ 的递推:
得到残差,就可以对偏置和权值进行偏导:
(4)卷积层输出的组合
卷积层的输出是由上一层多个maps决定的。有些文献中采用人工选择maps组合。为了提升组合效率,可以让CNN网络学习如何组合maps。设 αijαij 为第 ii 个输入map对第 jj 个输出map的贡献,则可得到第 jj 个map的输出为:
其中满足 ∑iαij=1∑iαij=1 和 0≤αij≤10≤αij≤1 。
对 αijαij 的约束可以用包含隐含变量 cijcij 的softmax函数来表示 αijαij :
为了方便,只考虑卷积输出一个map,因此上式的下标 jj 可以省略。故softmax函数的倒数可以表示为:
误差对第 ll 层变量 αiαi 的偏导为:
则误差对参数 cici 的偏导数为:
由于输出map不是和所有的输入map连接,也即 αiαi 满足一定的稀疏性,故需要在代价函数中增加稀疏约束项 Ω(α)Ω(α) ,则代价函数为:
这个约束项对参数 cici 的偏导为:
因此对参数 cici 的偏导数为: