iris_dataset 数据结构
11-22-2018
数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性
‘data’: array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],…
‘target’: array([0, 0, 0, 0, 0, 0, 0, 0…
‘target_names’: array([‘setosa’, ‘versicolor’, ‘virginica’]
‘DESCR’: '… _iris_dataset:\n\nIris plants dat…
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
from sklearn.datasets import load_iris
iris_dataset = load_iris()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split
(
iris_dataset['data'], iris_dataset['target'],
random_state=0
)
#
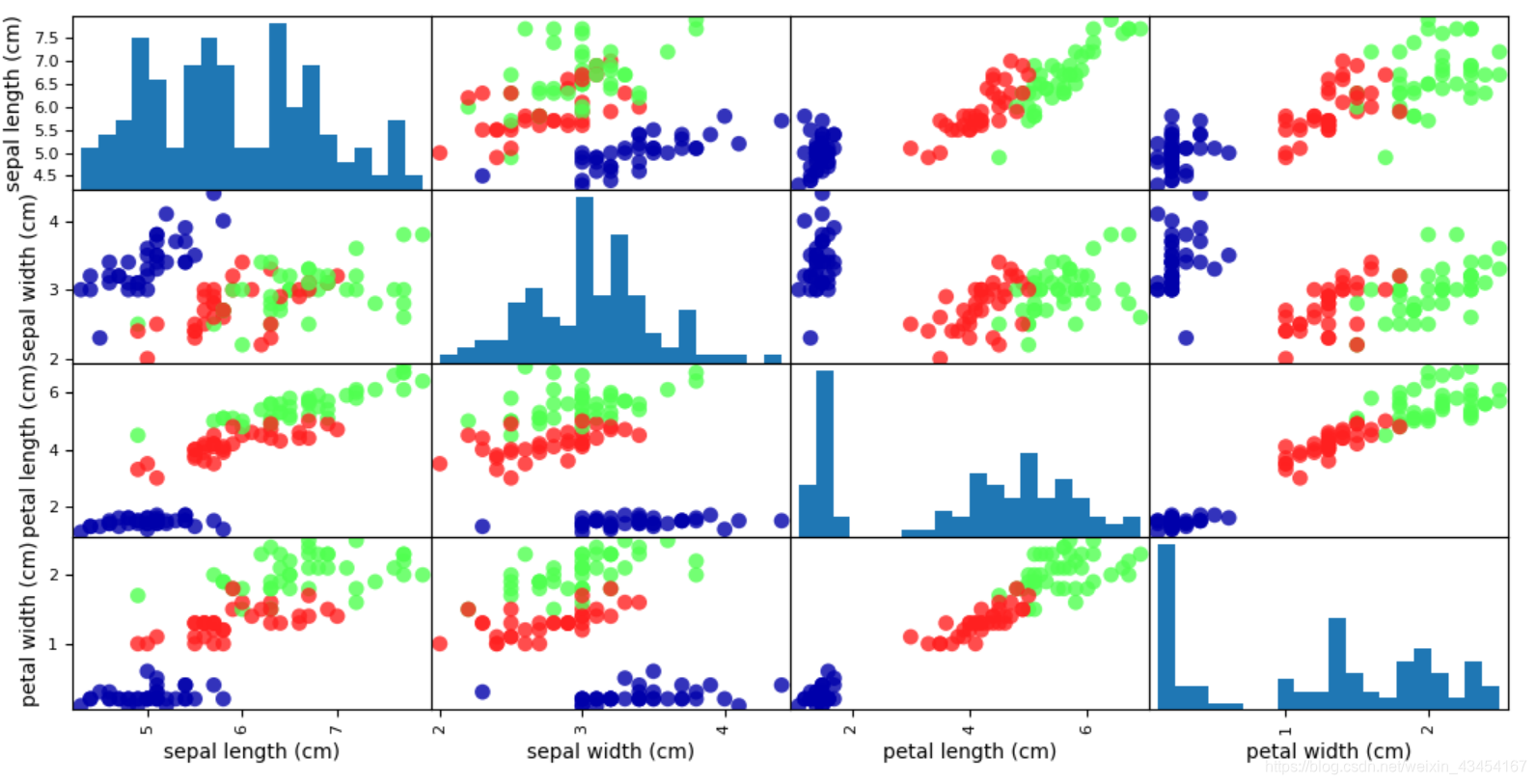
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
grr = pd.scatter_matrix
(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
plt.show()
将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不同品种的花),可以构建12种组合(其实只有6种,另外6种与之对称)