在阿里云中搭建大数据实验环境
第4步:在云服务器Ubuntu 16.04.4 LTS中安装Hadoop2.9.2
https://www.cnblogs.com/87hbteo/p/7606012.html
一、更新apt
用liuxv用户登录后,先更新apt,能使apt安装以后要使用的软件
sudo apt-get update

二、 安装SSH,配置SSH无密码登陆
1、Ubuntu默认已经安装了SSH client,此外还需安装SSH Server
sudo apt-get install opensh-server
2、安装后,用如下命令登陆本机:
$ssh localhost
3、改成无密码登陆
exit #首先退出刚才的SSH
cd ~/.ssh/
ssh-keygen -t ras #利用ssh-keygen生成密钥
cat .lib_rsa.pub >> ./authorized_keys #加入授权
再输入ssh localhost即可无密码登陆

三、安装hadoop
1、通过MobaXterm把Hadoop安装包传到/home/liuxv/Downloads中
2、解压到/usr/local中
cd ~
sudo tar -zxf ~/Downloads/hadoop-2.9.1.tar-gz -C /usr/local
cd /usr/local
sudo mv ./hadoop-2.9.1/ ./hadoop
#将文件夹改为hadoop
sudo chown -R liuxv:liuxv ./hadoop
#修改文件权限
3、给Hadoop配置环境变量
sudo vim ~/.bashrc
添加如下代码
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后保存退出,执行
source ~/.bashrc
使配置生效
再查看是否安装成功:
hadoop version

四、Hadoop伪分布式配置
1、首先将jdk的路径添加到、usr/local/hadoop/etc/hadoop/hadoop-env.sh文件中:
添加代码:export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
2、修改配置文件core-site.xml和hdfs-site.xml
core-site.xml:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化
$ ./bin/hdfs namenode -format启动namenode和datanode进程,并查看启动结果
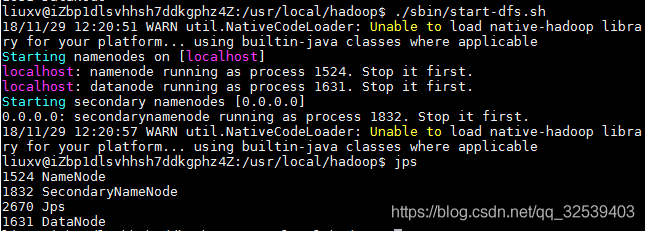
$ ./sbin/start-dfs.sh
$ jps启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
如果要停止Hadoop,可以使用如下命令:
cd /usr/local/hadoop
./sbin/stop-dfs.sh