1. 文本分类
(1)分词: 中文分词系统 -- NLPIR(也叫ICTCLAS2013), 还有庖丁解牛分词器。
召回率(Recall):是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。
精度(Precise):是指检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。
(2)文本表示。 也就是文本的向量化。用得比较多的模型是向量空间模型(VSM)。其基本思想是把文档简化为特征项的权重为分量的向量表示。权重用词频表示。词频分为:
(a)绝对词频:词在文本中出现的频率表示文本
(b)相对词频: 即归一化的词频。
归一化就是从绝对数量转化为比例的一种思路。主要运用 TF-IDF(Term Frequency-Inverse Document Frequency)公式。例如:一篇文章的总词语数是100个,而词语“汽车”出现了5次,那么“汽车”一词在该文章听词频就是 5/100=5%,一个计算文件频率(IDF)的方法是测定有多少份文件出现过“汽车”一词,然后除以文件集里包含的文件总数。所以如果“汽车”一词在 100份文件中出现过,而文件总数是10000份,其逆向文件频率(IDF)是 lg(10000/100)=2 (lg 是底为10的对数)。最后的 TF-IDF=5%*2=10%。如果某个词汇在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为这个词汇有很好的类别区分能力,适合用来分类。TF 表示该词汇在文档中出现的频率,而 IDF则表示含有该词汇的文档比例越低,则IDF越大,则说明该词汇具有越好的类别区分能力。
(3)分类标记
分词和分词权重最后要和分类的标签之间产生一个映射关系,而描述这种映射的过程是需要算法来实现的,可以用概率来实现,也可以用基于向量空间的回归来实现。常用的算法有 Rocchio 算法、朴素贝叶斯分类算法、K-近邻算法、决策树算法、神经网络和支持向量机算法等。
2. Rocchio 算法

核心思路是给每一个文档的类别都做一个标准向量 ---- 也有的地方称为原型向量,然后用待分类的文档的向量和这个标准向量比一下余弦相似度,相似度越高越可能属于该分类,反之则不然。计算公式:
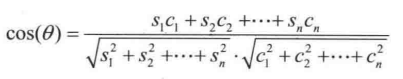
其中 S1, S2, S3...Sn 是原型向量的各个维度, C1, C2, C3...Cn 是待分类的向量的各个维度。
Rocchio 算法的改进版本是不仅依据正样本计算正向量,还根据负样本计算负向量。
Rocchio 算法做了两个假设,使得它的分类能力打了很大的折扣:
假设一: 一个类别的文档仅仅聚集在一个质心的周围,实际情况往往不是如此。
假设二:训练数据是绝对正确的,因为它没有任何定量衡量样本是否含有噪声的机制,错误的分类数据会影响质心的位置。
3. 朴素贝叶斯算法
朴素贝叶斯算法关注的是文档属于某类别的概率。文档属于某个类别的概率等于文档中每个词属于该类别的概率的综合表达式。而每个词属于该类别的概率又在一定程度上可以用这个词在该类别训练文档中出现的次数(词频信息)来粗略估计。
步骤如下:
(1) 对训练文章进行分词和向量化
(2) 对所有文章类别计算 P(Dj | x)、P(y | Dj) 和 P(z | Dj) 等
(3) 对待分类的文章进行分词和向量化
(4)用待分类文章的词向量中的每个词计算 P(x | Dj )、P(y | Dj) 和 P(z | Dj) 等
注意: P(x | Dj ) 可不是计算一个值,而是计算整个词向量中所有的词,如果词向量有 1000 个元素,那么 Dj 就是 D1 到 D1000,这 1000个词都要进行计算。
(5) 计算概率,看待分类文章属于哪个类型的文章概率最大。
公式: 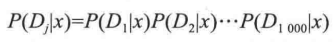 变形简化成:
变形简化成: 
其中, P(x | Dj ) 就是要求的值,即完整的词向量 Dj 最终属于 x 文章分类的概率。
P(Dj)可以设为1,因为对于已经拿到的特分类文本,所有的词频发生概率就已经是 1 了。
P(x) 是所有训练文章中 x 类文章出现的概率。
4. K-近邻算法
算法思路: 没有必要去总结原型向量,只需原始的训练样本,这些样本具有最基础最原始而且准确的向量信息。
流程: (1) 对每个样本都进行分词和向量化
(2) 对需要判定的样本也进行分词和向量化
(3) 玍判定的样本的向量和所有训练的样本进行向量特征比对,也就是相似度比对。这样会得到它与所有训练样本的相似度排名列表。
(4) 从这个列表中找出相似度最高的 K 篇文章,根据这 K 篇文章的类别分别投票决定待判定的样本属于哪一类。
优点: 可以克服 Rocchio 算法中无法处理线性的缺陷,同时“训练成本”也非常低,只需加入新的训练样本即可。
缺点: 计算成本比较高。非常致命的缺点。
5. 支持向量机(SVM)算法
SVM 分类器的文本分类效果很好,可以认为是最好的分类器之一。
优点:通用性较好,分类精度高,分类速度快,分类速度与训练样本个数无关。在查准率和查全率方面都优于KNN及朴素贝叶斯方法
缺点:训练速度很大程度上受到训练集规模的影响,计算开销比较大。一些改进方法: Chunking 方法, Osuna 算法、SMO 算法 和交互 SVM。