一、增强学习概念
增强学习特点:
增强学习是机器学习的一种,机器学习主要分为监督学习、非监督学习、半监督学习,增强学习就是让计算机学着自己去做事情,进行自学习,人只需要给计算机设定一个“小目标”,具体的策略就需要计算机自己去设计啦!
- 跟增强学习相关的例子
- 动态规划法
逐步去找出最优子结构的状态,然后找到这些状态求解的先后顺序,在状态之间构成一个有向无环图,来一步步求解最后的问题。
2.PageRank算法
Google最先使用的网页排序算法,搜索引擎需要对网页进行排序,越重要的网页排名越靠前,有越多的网站指向这个网页就越重要。
PageRank算法使用迭代方法解决了这个问题,首先将网页的权重设成一样的,然后计算一圈,很多网页的权重和一开始不一样了,这时候使用这个计算出来的权重再计算一次,最后结果是收敛的。
- 例子
把机器人放在一个陌生的环境中,希望机器人自己能够到目标房间中去。
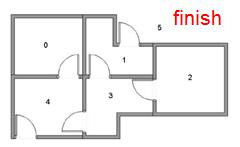
使用传统方法会通过搜索,或是记忆化的搜索(动态规划)找出全局的布局。
我们首先设定下目标房间的权重,即我们给它一个奖励,当机器人走到目标房间时,就会给它对应的奖励。写出状态之间切换的权重以及权重矩阵。


一步一步的对相邻的房间也赋予权重,通过迭代训练,只要机器人向当前结点周围分值最高的点走过去就可以找到目标房间。
- 增强学习介绍
增强学习的特点是,从现有的状态出发,不断的优化自己的策略,过程中使用到了agent(主体)、environment(主体所处的环境)、episode(一个完整的训练的阶段,即训练开始到结束)、step(一个episode中的一个操作)、state(主体当前所处的状态)、action(要采取的操作是什么)、value(采取的每个动作,所具有的价值)。

Agent和environment是最基本的交互,agent观察environment的状态,然后做出一个action,environment接收action又产生新的状态。Agent只能获得它观测到的数据,不能有上帝视角。
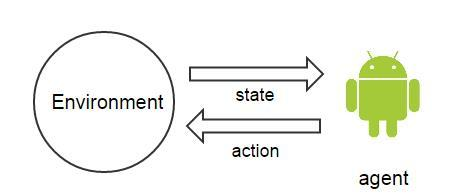
- 增强学习的数学表示:
使用S表示状态集合,A表示行为集合,π作为策略。当采取策略π时,根据当前状态来选择下一刻的行为:a=π(s)
对于状态中的每一个状态s,都有对应的回报值R(s)与之对应;对于状态序列中的每下一个状态,设置一个衰减系数γ;对于每一个策略π,设置一个相应的权值函数Vπ(S0)=E[R(S0)+γR(S1)+γ2R(S2)+…|S0=S,π]
这个表达式满足Bellman-Ford Equation,即可简化为Vπ(S0)=E[R(S0)+γVπ(S1)]
- 用大白话来讲就是,需要知道当前状态的价值是多少,从而选择最大化价值的那个状态来进行操作,当前状态的价值,就是之后所有价值的叠加,越往后,噪声越大,这就需要让他们的权重减小。后面所有状态的价值和,又可以写成下一状态的价值。当前状态的回报值reward可以直接获得,我们只需要计算下一状态的权值函数就可以,这一点,我们需要神经网络来进行计算。
二、增强学习的策略
场景假设:在一个游戏当中,可以向前后左右四个方向移动,想要知道往哪个方向走收益最大
1、蒙特卡洛方法
蒙特卡洛方法是一个暴力、直观的方法,策略就是对所有可能的结果求平均,当我们选择向“前”走了以后,再做一个action,根据这个式子,直到episode结束,求出收益的和,就是向前走这个动作的采样。我们再不断的在这个状态采样,然后求平均,等到采样非常非常多的时候,统计值就会非常的接近期望值了。
2、动态规划法
当我们要确定向前走这个动作的收益的时候,就把它所有的子问题全部都计算完成,然后取最大值,就是其收益,好处就是效率高,但缺点就是需要子结构的问题时有向无环图。
3、Temporal Difference(时间差分)
简称TD,是蒙特卡洛方法的简化,也是实际应用中最多的一种算法。当计算向前走这个动作的收益的时候,是当前状态的reward值加上转移到后继状态的期望值,我们观测前面的状态,剩下的价值不真正的去计算,用神经网络去估算,这就是TD(0)算法。
三、用神经网络对状态进行估算
神经网络具体怎么工作,就像一个黑盒子,输入是一个状态,输出的是这个状态的价值。
没有训练数据?
这个算法最牛的地方在于,整个系统在运作过程中,通过现有的策略,产生了一些数据,获得的这些数据在计算回报值Reward的时候,会有所修正,我们把修正的值和状态,作为神经网络的输入,再进行训练,最后的结果显示,这样做是可以收敛的。
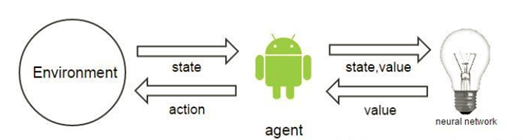
神经网络的运用包括训练和预测两部分,训练的时候输入的是状态和这个状态的value值,预测时候输入时状态,输出的是估算的value值。
4、算法的整个流程
我们采用TD(0)作为状态的计算,神经网络作为状态价值的估算的这套算法,叫做Q-Learning算法,如果我们采用epsilon-greedy方法,主要流程如下:

epsilon-greedy方法取决于任务,选择每个动作的概率是一样的,soft-max Action Selection方法给予了不同动作不同的概率,给greedy action最大的概率,其他的动作根据其value大小,按概率进行选择。最不合适的行为概率最小。
算法评价:
Evaluative-feedback:得到的reward值会反映出这个行为有多好,不会告诉是正确的还是错误的。
Instructive-feedback:执行的结果会告诉这个行为是正确的还是错误的
像flyppy bird让小鸟自行的进行游戏,训练过程当中,撞到柱子就获得-1的回报值,否则获得0回报,经过若干次的训练,就会训练出一只技能高超的小鸟,它知道在什么情况下躲避柱子。
又像设计一款国际象棋的软件,不能使用监督学习的方法,通过增强学习,不断的摸索和试错行为,在每个状态下选择最有可能获胜的棋步,在棋类游戏中获得了广泛的应用。
增强学习,更接近于生物学习的本质,就像在训练一个更高级的智能机器人,通过神经网络的训练,让它有自学习的能力,有自己的思考。最终达到的效果就是,人们给它设定一个目标,让它自主的去实现,感觉像是将人工智能实现从智商到情商的跨越,如果再加上博弈机器学习思想,实现由个体智能到社会智能的飞跃。