一、SparkSQL发展历程
SparkSQL的前身是Shark, Shark是伯克利实验室Spark生态环境的组件之一,它修改了下图Hive所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升
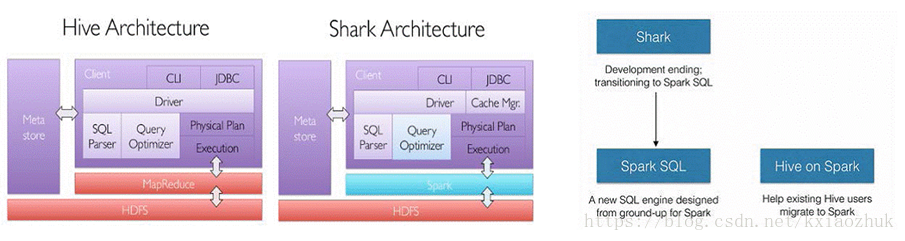
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和Hive on Spark
二、SparkSQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。
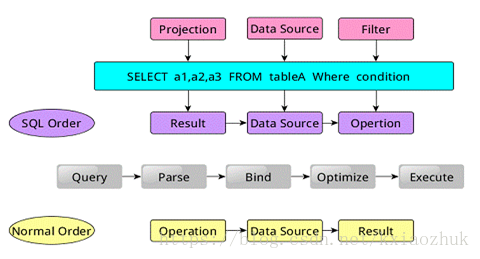
SparkSQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在SparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。
三、SparkSQL
Spark1.2前, schemaRDDs由行对象组成,行对象拥有一个模式来描述行中每一列的数据类型
Spark1.3后,采用DataFrame,将数据保存为行构成的集合,行对应列有相应的列名,支持的数据格式有:RDD,JSON,Hive,Mysql,HDFS,JDBS,parquest等等
通过registerTempTable注册成临时表,然后通过SQL语句进行操作
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器(SQL-92语法);hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法