版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/m0_37294838/article/details/91407028
在第一节的常规性能调优中我们讲解了并行度的调节策略,但是,并行度的设置对于Spark SQL是不生效的,用户设置的并行度只对于Spark SQL以外的所有Spark的stage生效。
Spark SQL的并行度不允许用户自己指定,Spark SQL自己会默认根据hive表对应的HDFS文件的split个数自动设置Spark SQL所在的那个stage的并行度,用户自己通spark.default.parallelism参数指定的并行度,只会在没Spark SQL的stage中生效。
由于Spark SQL所在stage的并行度无法手动设置,如果数据量较大,并且此stage中后续的transformation操作有着复杂的业务逻辑,而Spark SQL自动设置的task数量很少,这就意味着每个task要处理为数不少的数据量,然后还要执行非常复杂的处理逻辑,这就可能表现为第一个有Spark SQL的stage速度很慢,而后续的没有Spark SQL的stage运行速度非常快。
为了解决Spark SQL无法设置并行度和task数量的问题,我们可以使用repartition算子。
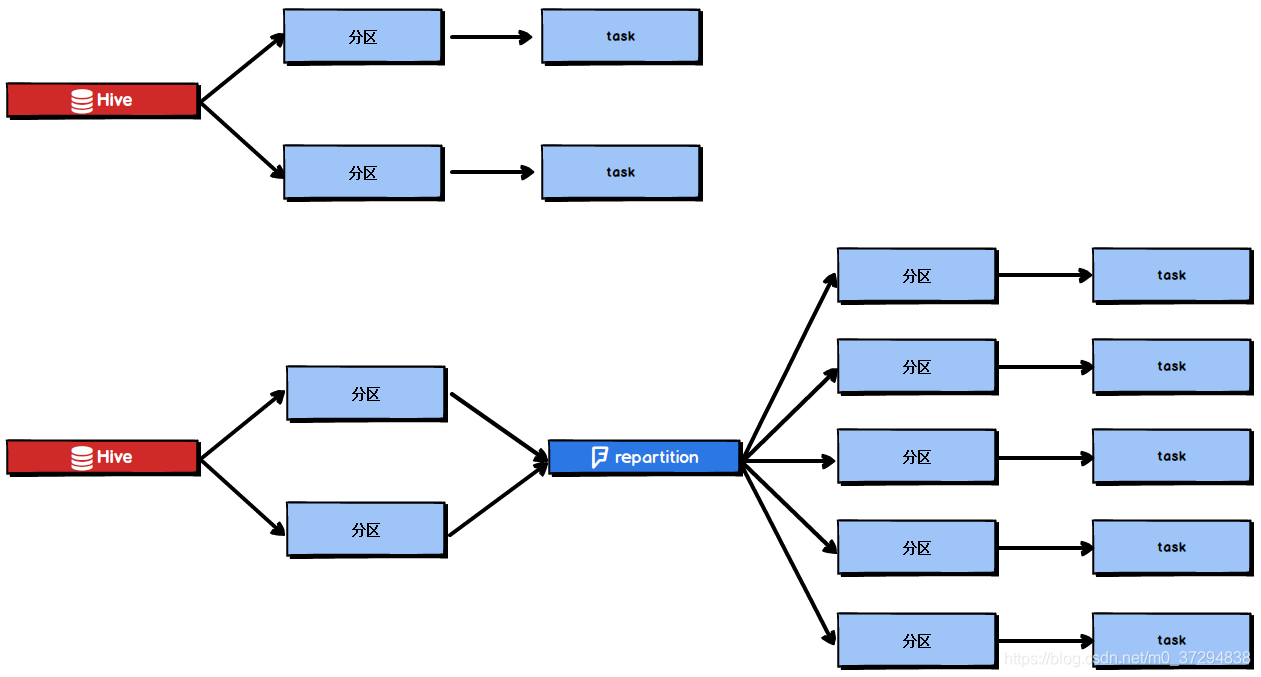
Spark SQL这一步的并行度和task数量肯定是没有办法去改变了,但是,对于Spark SQL查询出来的RDD,立即使用repartition算子,去重新进行分区,这样可以重新分区为多个partition,从repartition之后的RDD操作,由于不再设计Spark SQL,因此stage的并行度就会等于你手动设置的值,这样就避免了Spark SQL所在的stage只能用少量的task去处理大量数据并执行复杂的算法逻辑。使用repartition算子的前后对比