参考资料:http://dockone.io/article/1723
https://blog.csdn.net/pangjiuzala/article/details/50838591
http://wiki.baidu.com/pages/viewpage.action?pageId=488923228
https://blog.csdn.net/do_what_you_can_do/article/details/53128480
https://blog.csdn.net/chenxun_2010/article/details/79218083
spark中的executor和task的关系:http://wenda.chinahadoop.cn/question/4465
一、spark架构
架构简介


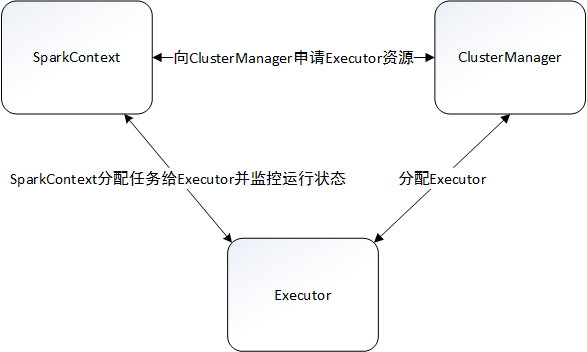
spark中executor和task 的关系:

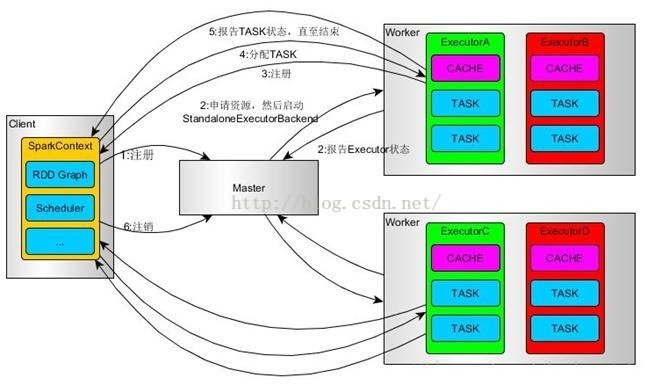
一、Standalone模式流程
1、使用SparkSubmit提交任务的时候(包括Eclipse或者其它开发工具使用new SparkConf()来运行任务的时候),Driver运行在Client;使用SparkShell提交的任务的时候,Driver是运行在Master上
2、使用SparkSubmit提交任务的时候,使用本地的Client类的main函数来创建sparkcontext并初始化它;
3、SparkContext连接到Master,注册并申请资源(内核和内存)。
4、Master根据SC提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动StandaloneExecutorBackend(executor)
5、executor向SC注册
6、SC将应用分配给executor,
7、SC解析应用,创建DAG图,提交给DAGScheduler进行分解成stage(当出发action操作的时候,就会产生job,每个job中包含一个或者多个stage,stage一般在获取外部数据或者shuffle之前产生)。然后stage(又称为Task Set)被发送到TaskScheduler。TaskScheduler负责将stage中的task分配到相应的worker上,并由executor来执行
8、executor创建Executor线程池,开始执行task,并向SC汇报
9、所有的task执行完成之后,SC向Master注销