文章目录
- 一.安装CentOS7的linux系统
- 二.hadoop安装前准备
- 三.hadoop安装和相关文件配置
- (一)安装Hadoop
- (二)修改配置文件
- 1.hadoop-env.sh运行环境的文件修改
- 2.core-site.xml配置文件修改(机器ip为192.168.56.101)
- 3.hdfs-site.xml配置文件的修改
- 4.新建mapred-site.xml文件写入如下内容:
- 5.yarn-site.xml配置文件修改
- 6.slaves配置: `vi slaves`
- 7.hadoop环境变量配置
- (三)格式化HDFS:`hadoop namenode -format`
- (四)启动和关闭的命令:
- 四.验证是否成功(先启动hdfs,yarn,历史服务)
- 五.解决命令执行后报如下警告:
- 六.集群搭建
- (一)复制虚拟机(复制前删除主机器hdfs临时文件目录,然后关闭主机器),如下:
- (二)启动副本机器,修改静态ip
- (三)启动所有集群机器,配置免登录
- (四)修改主机器的配置文件
- (五)修改副本机器的配置文件
- 七.附安装视频,提取码: xaw6
一.安装CentOS7的linux系统
- 具体安装见如下链接:
linux系统安装
二.hadoop安装前准备
- 1.所需文件见如下链接,链接:提取码: 6uxv
hadoop相关安装包 - 2.安装jdk见如下链接
linux系统下jdk安装 - 3.配置免登录:
ssh-keygen -t rsa -P ""cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys- 4.修改主机名:
hostnamectl set-hostname hadoop101 - 可用
hostname命令查看是否修改成功 - 5.修改主机列表:
vi /etc/hosts,添加主机ip地址和主机名,如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.101 hadoop101
三.hadoop安装和相关文件配置
(一)安装Hadoop
- 1.将hadoop的安装包拖进opt目录下
- 2.安装该文件:
tar -zxvf hadoop-2.6.0-cdh5.14.2.tar.gz - 3.删除安装包:
rm -rf hadoop-2.6.0-cdh5.14.2.tar.gz
(二)修改配置文件
- 进入安装目录下hadoop目录:
cd /opt/hadoop-2.6.0-cdh5.14.2/etc/hadoop
1.hadoop-env.sh运行环境的文件修改
- 打开文件:
vi hadoop-env.sh,然后按25gg跳到jdk环境配置修改为自己的Java目录:
export JAVA_HOME=/opt/jdk1.8.0_221
2.core-site.xml配置文件修改(机器ip为192.168.56.101)
- 打开文件:
vi core-site.xml,在configuration标签内插入如下内容:
<!-- 默认节点(写自己主机的ip)端口,端口默认为9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.101:9000</value>
</property>
<!-- hdfs的临时文件的目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.0-cdh5.14.2/hdfsTmp</value>
</property>
<!-- 其他机器的root用户可访问 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- 其他root组下的用户都可以访问 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
3.hdfs-site.xml配置文件的修改
- 打开文件:
vi hdfs-site.xml,在configuration标签内插入如下内容:
<!-- 设置数据块应该被复制的份数(和集群机器数量相等) -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- namenode备用节点 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop101:50090</value>
</property>
4.新建mapred-site.xml文件写入如下内容:
- 新建文件写入如下内容:
vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- mapreduce的工作模式:yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapreduce的工作地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.56.101:10020</value>
</property>
<!-- web页面访问历史服务端口的配置 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.56.101:19888</value>
</property>
</configuration>
5.yarn-site.xml配置文件修改
- 打开文件:
vi yarn-site.xml,在configuration标签内插入如下内容:
<!-- reducer获取数据方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址,值为主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop101</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
6.slaves配置: vi slaves
- 将内容改为自己的主机名:
hadoop101
7.hadoop环境变量配置
- 输入:
vi /etc/profile,在Java环境配置下插入如下内容:
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.14.2
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
- 输入:
source /etc/profile,使其生效
(三)格式化HDFS:hadoop namenode -format
(四)启动和关闭的命令:
start-all.sh:启动hdfs和yarnstart-dfs.sh:启动hdfsstart-yarn.sh:启动yarnstop-all.sh:关闭hdfs和yarnstop-dfs.sh:关闭hdfsstop-yarn.sh:关闭yarnmr-jobhistory-daemon.sh start historyserver:启动历史服务mr-jobhistory-daemon.sh stop historyserver:关闭历史服务
四.验证是否成功(先启动hdfs,yarn,历史服务)
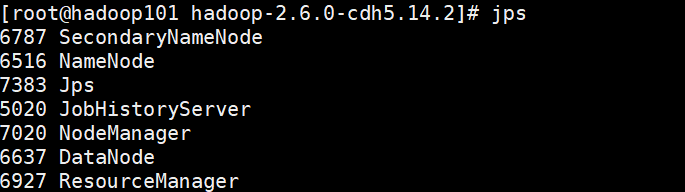
- 方式1:
jps命令若出现除jps进程的以下六个进程说明启动成功
- 方式2:进入网页测试
- 1).输入:http://192.168.56.101:50070,若能出现如下页面即成功启动了hdfs

- 2)输入:http://192.168.56.101:8088,若能出现如下页面即成功启动了yarn

- 3)输入:http://192.168.56.101:19888,若能出现如下页面即成功启动了历史服务

五.解决命令执行后报如下警告:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
- 将native安装包解压安装到hadoop安装目录的lib目录和lib目录下的native目录即可
tar -xvf hadoop-native-64-2.6.0.tar -C $HADOOP_HOME/lib/native
tar -xvf hadoop-native-64-2.6.0.tar -C $HADOOP_HOME/lib
- 执行命令之前的效果:

- 执行命令之后的效果:

六.集群搭建
(一)复制虚拟机(复制前删除主机器hdfs临时文件目录,然后关闭主机器),如下:

(二)启动副本机器,修改静态ip
- 使用root用户登录
- 输入:
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3,将最后一行的ip地址修改(一般与主机器连号) - 输入:
systemctl restart network,重启网络 - 输入:
vi /etc/hostname,修改主机名 - 输入:
vi /etc/hosts,修改主机列表(主机器也要修改)然后重启reboot,为简单演示只配两台机器,如下

(三)启动所有集群机器,配置免登录
- 1.由于之前hadoop搭建配置过免登录,需要先删除文件,输入:
cd /root/.ssh/,删除私钥文件:rm -rf id_rsa,然后回到家目录:cd ~ - 2.生成私钥:
ssh-keygen -t rsa -P "",输入命令后直接回车 - 3.输入:
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys - 4.远程免登录配置:
ssh-copy-id -i .ssh/id_rsa.pub -p22 [email protected](有n个机器,就要配n-1次) - 5.验证免登录:
ssh [email protected]或ssh root@hadoop111,无需密码验证即当前机器对111机器免登录配置成功(有多少台机器都要验证)
(四)修改主机器的配置文件
- 1.进入hadoop安装目录下的etc目录下的hadoop目录:
cd /opt/hadoop-2.6.0-cdh5.14.2/etc/hadoop - 2.修改hdfs配置文件:
vi hdfs-site.xml,将dfs.replication属性的值改为集群的机器数目,将dfs.namenode.secondary.http-address属性的值改为一个副本机器的主机名,如下:

- 3.修改slaves文件:
vi slaves,将所有机器主机名添加进去,如下:
(五)修改副本机器的配置文件
-
1.进入hadoop安装目录下的etc目录下的hadoop目录:
cd /opt/hadoop-2.6.0-cdh5.14.2/etc/hadoop -
2.修改hdfs配置文件:
vi hdfs-site.xml,将dfs.replication属性的值改为集群的机器数目,将dfs.namenode.secondary.http-address属性的值改为主机器选择的副本机器的主机名,如下:
-
3.修改slaves文件:
vi slaves,将所有机器主机名添加进去,如下:
-
4.修改 :
vi mapred-site.xml,将地址改为当前主机的地址,如下

-
5.在主机器下格式化hadfs:
hadoop namenode -format -
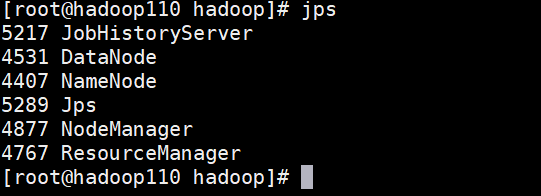
6.在主机器下运行:
start-all.sh和mr-jobhistory-daemon.sh start historyserver -
7.在主机器下输入:
jps,效果如下:
-
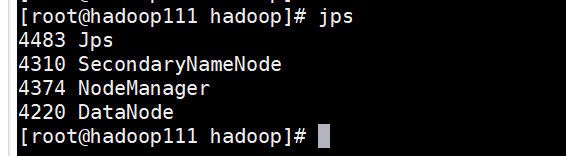
8.在副本器下输入:
jps,效果如下:
-
9.打开网页验证