目录
大厂UBER背书过的M3存储解决方案共有4个组件:
M3组件
M3 coordinator
协调上游系统和M3DB之间的读写操作,长期存储和其他监控系统的多DC(数据库集群)设置
M3DB
M3DB是一个分布式时间序列数据库,提供可扩展存储和时间序列的反向索引。
M3 query
包含分布式查询引擎,用于查询实时和历史指标,支持多种语言。
支持低延迟实时查询和可能需要更长时间执行的查询,聚合更大的数据集,用于分析用例
M3 Aggregator
专用度量聚合器。
基于存储在etcd中的动态规则提供基于流的下采样。
它使用领导者选举和聚合窗口跟踪,利用etcd来管理状态,从而可靠地为地采样标准发送至少一次聚合到长期存储。
最关心的就是其中的M3DB。
M3DB特性:
1. 分布式存储,单个节点使用一个WAL日志,并独立保存每个shard的时间窗
2. 基于ETCD的集群管理
3. 内置同步赋值,可配置的耐用性和读一致性(1个,多数,所有,等等)
4. M3TSZ float64压缩算法,根据Gorilla TSZ启发而来。可配置成无损或有损耗
5. 时间精度可配置,从秒到纳秒
6. 可配置的无序写入,目前限制于blocksize的大小。
M3DB限制:
M3DB目前支持基于ID的精确查找。它不支持标记/辅助索引。
这个特性正在开发中,M3DB的未来版本将支持内置的反向索引。
M3DB不支持更新/删除。所有写入M3DB的数据都是不可变的。
M3DB不支持任意写入时间。这通常用于监视工作负载,但对于传统的OLTP和OLAP工作负载可能是有问题的。M3DB的未来版本将更好地支持任意时间戳的写入。
M3DB不支持用双精度浮点以外的值编写数据池。M3DB的未来版本将支持存储任意值。
M3DB不支持存储具有不确定保留期的数据,M3DB中的每个名称空间都需要有一个保留策略,该策略指定该名称空间中的数据将保留多长时间。虽然这个值没有上限
M3DB不支持后台数据修复或CasDANRA样式的读取修复。M3DB的未来版本将支持数据作为正在进行的后台进程的自动修复。
分布式机制
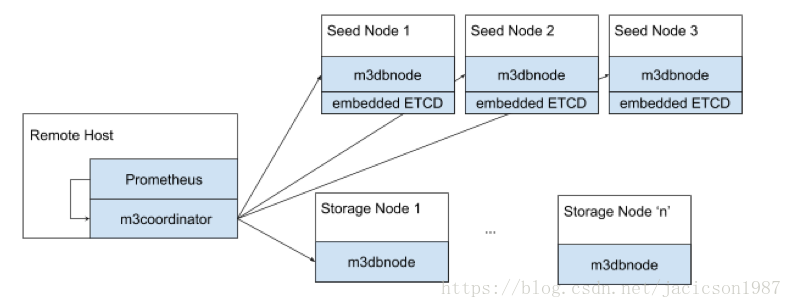
m3coordinator
协调集群所有集群的读写,轻量级进程,不存储任何数据。它一般在Prometheus旁边一起运行,Prometheus的指令都通过m3coordinator下发到集群中的主机。
storage node
m3dbnode进程是各节点数据库主进程,存储数据,提供读写
Seed Node
种子节点本身也是储存节点。除此以外,还要运行嵌入式ETCD服务。推断拓扑、配置
存储引擎
1.压缩算法
主要压缩算法M3TSZ, 是Gorilla paper算法的变体,根据UBER的数据特征,每个points压缩后达到1.45bytes大小,压缩率很高。
2. 内存架构布局
架构图
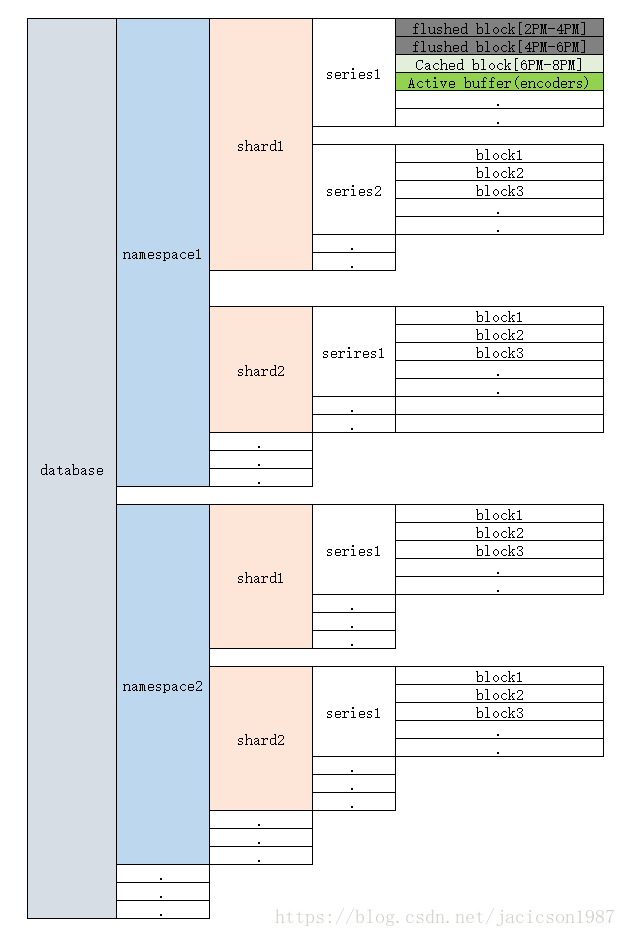
架构说明:
1. 每个M3DB进程只有一个database
2. 每个database有多个namespace, 每个namespace有独立的名字和配置(根据数据保留和块代销)
namespace相当于普通数据库中的表。
3. 一个namespace包含多个shard, shards按照series ID的哈希值来分配数据。
4. 一个shard包含多个series
5. 一个series包含多个blocks对象,
block分类
1. fileset file, 已写入磁盘,密封(不可写)的一段已压缩的数据流的对象。
而且无法读取其中的单个数据点,如果想要读取单个数据点,必须整个解压block。内存中并没有cache这些数据流
2. In-memory cache, 未写入磁盘,已密封的数据,不可写入,一样需要解压整个block,与第一种block唯一的区别就是还未写入磁盘,内存中Cache
3. active buffer, 没有被密封的,已被压缩的数据流
持久存储:
commitlog
即WAL文件,无压缩写入数据,可以每次写,也可以批量写(快得多,但是恢复会丢失数据)
snapshot
根据配置的blocksize大小,到达阈值,所有active blocks被密封,刷到磁盘fileset files.
这些文件被高度压缩,还被附加的索引文件编入索引。
blocksize
blocksize参数的大小十分重要,要根据数据负载的特点来设定。这个值是时间,比如默认2小时。
如果太小,频繁刷磁盘,而且更小的数据被压缩,整体压缩率降低,占用磁盘更多。
灾难恢复
有两个途径,一是从commitlog来恢复,另一个是从peer端的同一个shard中获取(如果复制因子大于1)
存储策略
制定策略让某些数据尽可能缓存在内存中,用于应对可能会被经常访问的数据
写入
属性
一次写入必须包含namespace, seriesID(byte blob), timestamp, value四个属性。
简要流程
namespace==> shard ===> series ===> encoder ===>最后编码进压缩流active buffer
同时这次写入会加入到commitlog queue(立即写入或者等待批量写入)
写入只涉及到commiltlog 和 active buffer, 并不会马上写入磁盘数据集
读取
属性
一次读取必须包含namespace, seriesID(byte blob), timestamp(start and end) 三个属性
流程
namespace ===> shard ===> serires
如果serires 不存在, 查询bloom fileter 确认是否在 磁盘文件中。
查找磁盘文件的流程略复杂
bloom filer ===> 二分查找索引摘要 找到index文件offset ===> 找到index entry,获得data file,offset ===> 读取数据流
对于查询涵盖多个block,会合并成一个数据流返回给客户端。
但是M3DB返回给客户端的是完整的几个blocks,已压缩的。靠客户端自己解压分解。
官方文档提示:因为高压缩,这个流量问题不大。
举例,一次查询涵盖 block1的后半部分,block2完整,block3前半部分, 那么M3DB会把block1,2,3都完整的返回给客户端。
后台进程
Ticking
1. 合并 给定series block启动组合的编码器
(因为无序导致新的malloc编码器,在刷入磁盘之前要排序,合并编码器)
2. 删除内存中已经flush到disk或者期满的Blocks
3. 文件系统中清楚过期数据
Flush
按照blocksize设置的时间,定期将active buffer变成密封的block,再写入磁盘,同时释放内存资源。
这里应该还要按照缓存策略决定是否释放内存资源。