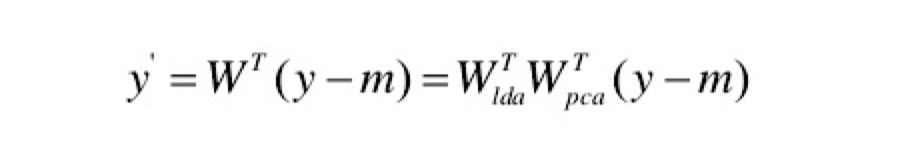第三次作业
参数初始化为什么不能全为零
在实现深度神经网络时,运用反向传播算法对网络进行训练,对每层的W和b进行更新,初始化的时候一般采用高斯分布进行初始化,为什么全部初始化为0呢?
-
参数不能全部相等,随机初始化使网络失去对称性,否则每次参数更新时,计算出的每层输出和返回的Error都相等;
-
Pitfall: all zero initialization. Lets start with what we should not do. Note that we do not know what the final value of every weight should be in the trained network, but with proper data normalization it is reasonable to assume that approximately half of the weights will be positive and half of them will be negative. A reasonable-sounding idea then might be to set all the initial weights to zero, which we expect to be the “best guess” in expectation. This turns out to be a mistake, because if every neuron in the network computes the same output, then they will also all compute the same gradients during backpropagation and undergo the exact same parameter updates. In other words, there is no source of asymmetry between neurons if their weights are initialized to be the same.;
-
模型退化问题: 在前向传播(forward propageate)时,每一层的输出都将是一样的。这将导致,在反向传播的时候,每一层的dW都一样,进而使得每一层的W一样。如果一个layer中的参数完全一样,那么就相当于在该layer中它们表述的特征是相同的,即使在这个layer有多个节点,这跟在这个layer中只用一个节点没有差别。如果每一个layer中的参数都是一样的,这个极端就使得模型退化为线性的了
PCA,LDA 特征提取和降维方法
其中一个问题是,课上说结合PCA,LDA然后进行rankSVM的方法,为什么要同时用两种降维的方法呢?
- 小样本问题: 线性判别分析法寻找的是有效分类的方向。而当样本维数远大于样本个数(即小样本问题)时,LDA便束手无策。
- 两个限制:
- 存在秩限制,即对C类问题最多只能提取C-1个最油鉴别矢量。
- 面对人脸识别等高维小样本问题时,类内离散度矩阵奇异,无法通过最优化规则函数求得最优鉴别矢量集。
- 结合使用方法:Fisherface