什么是 coreseek?
coreseek 是一款基于 sphinx 开源的搜索引擎,专门为用户提供免费的中文全文检索系统,coreseek 被称为带有中文分词的 sphinx,与 sphinx 不同的是 coreseek 增加了一个带有中文分司的词库
什么是分词技术?
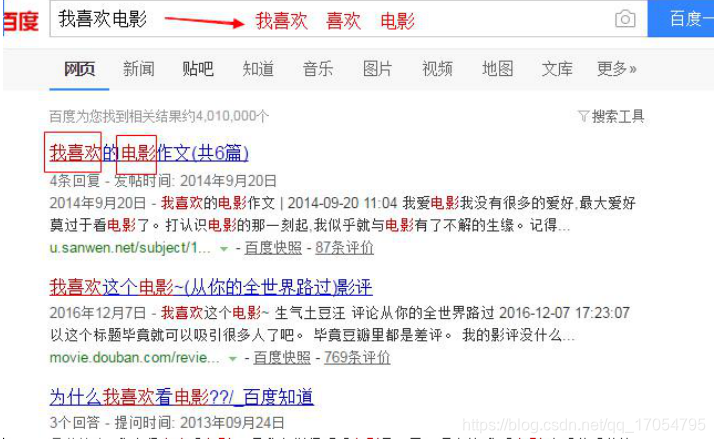 使用分词技术之后,可以查询更多更准确更丰富的内容。
使用分词技术之后,可以查询更多更准确更丰富的内容。
Sphinx 特性
1、处理速度快
2、处理量大
3、支持的算法
高速的建立索引(可达 10M/秒)
高性能的搜索(平均检索时间小于 0.1 秒)
可处理海量数据
提供了优秀的相关度算法
支持分布式搜索
提供摘要生成功能
可作为 MYSQL 存储引擎提供搜索服务
支持布尔、短语、词语相似度等多种检索模式
单个文档支持多个全文检索字段(最大不超过 32 个)
支持额外的属性信息
支持单一字节编码和 UTF-8 编码
原生支持 MYSQL、PostgreSQL 数据库
解压
解压之后:

Sphinx 原理
第一步:
① sphinx 和 MySQL 建立联系
② sphinx 会分析 MySQL 数据表中的字符串类型的字段,从字段中自动拆取关键词,再根据
关键词获取所有相关的数据 id。
③ 将关键词和 id,记录到 sphinx 自己的索引库中
以上操作是 sphinx 自动完成的
第二步:PHP 读取 spinx 中关键词对应的数据,再从 MySQL 中查询数据
④ 根据关键词从 sphinx 的索引库中取出对应 id 值
⑤ 根据 id 值,从 mysql 中取出数据
程序员手动编写程序完成的

配置 Sphinx
将 sphinx 程序复制到合适的位置:

创建 MySQL 的 Sphinx 文件

将配置文件复制到 sphinx 的根目录下,并改名为 sphinx.conf

配置数据源
配置数据源:指定从哪个表中获取关键词

配置分词索引
分词索引配置: 指定要建立分词表(源),指定索引库保存位置

配置服务

创建分词索引

创建分词索引:
在 cmd 中运行 indexer.exe 命令
格式: indexer.exe -c 配置文件路径 数据源名称
示例: indexer.exe -c C:/work/dev/sphinx/sphinx.conf movie

查看索引文件:

安装 sphinx 服务
使用 searchd.exe -h 帮助命令

将 sphinx 安装为系统服务:


点击“启动”来启动 sphinx 服务。
第一步完成。
使用 PHP 操作 Sphinx
根据关键词从 sphinx 服务器中获取对应的 id 值

Sphinx 是一个类,该类并不在 php 底层程序中,在 sphinx 的安装包的 api 目录中

将该文件复制到项目中:

具体代码编写:
第一步:加载 sphinxapi 类
第二步:实例化 spinx 对象
第三步:链接 sphinx
第四步:执行 query()方法
返回值中 matches 中的下标就是数据在数据库中的 id
访问结果:
Matches 下标中的内容就是匹配到的 id 值。
2) 根据 id 值,从 MySQL 服务器中获取对应的内容
将关键词高亮显示

参数 1:$docs 每次从 mysql 结果集中取出的数组 ,就是程序中的 $row
参数 2:索引文件的名称 $index=’movie’ 参数
3:关键词 $word = ‘香港’ 参数
4:配置项
‘before_match’ : 在输出关键词之前输出的代码
‘after_match’ : 在输出关键词之后输出的代码
整体代码:


