上一篇文章介绍了搜索引擎的核心原理——搜索引擎,从本篇开始我们动手实现搜索引擎。本篇主要介绍数据采集部分的内容,使用Scrapy爬虫框架爬取数据。以爬取新浪新闻为例,介绍如何爬取数据。
1 先让Scrapy跑起来——使用方法介绍(本节内容参考自Scrapy教程)
Scrapy是Python的一个web数据爬取框架,安装Scrapy也非常简单,可以通过pip安装,也可以在anaconda中通过可视化界面安装,不知道Anaconda是什么或者如何安装Anaconda,请移步这里。
安装好Scrapy之后,通过命令行进入到你想建立项目的文件夹下,输入
scrapy startproject [项目名],
项目建立成功之后再输入
cd [项目名]
进入到项目内部,在下图所示位置建立一个爬虫python文件(注意这个文件应该建立在spiders文件夹下)
news.py中的代码如下:
# -*- coding: utf-8 -*-
import scrapy
import os
import re
from news.items import NewsSinaItem
# 新浪新闻爬虫类
class NewsSinaSpider(scrapy.Spider):
name = 'sina_news'
allowed_domains = ['sina.com.cn']
start_urls = ['http://news.sina.com.cn/guide/']
def parse(self, response):
for each in response.xpath("//*[@id='tab01']/div[@data-sudaclick!='citynav']"):
#大类链接
parentUrl = each.xpath('./h3/a/@href').extract()[0]
parentTitle = each.xpath('./h3/a/text()').extract()[0]
parentPath = '../data/test_data/raw_data/' + parentTitle
if not os.path.exists(parentPath):
os.makedirs(parentPath)
#大类链接下的小类链接
for other in each.xpath("./ul/li/a"):
if other.xpath('./@href').extract()[0].startswith(parentUrl):
item = NewsSinaItem()
subUrl = other.xpath('./@href').extract()[0]
subTitle = other.xpath('./text()').extract()[0]
subPath = parentPath
item['parentUrl'] = parentUrl
item['parentTitle'] = parentTitle
item['subUrl'] = subUrl
item['subTitle'] = subTitle
item['subPath'] = subPath
# if not os.path.exists(subPath):
# os.makedirs(subPath)
yield scrapy.Request(url = item['subUrl'], meta = {'meta_1': item}, callback = self.second_parse)
def second_parse(self, response):
meta_1 = response.meta['meta_1']
items = []
for each in response.xpath('//a/@href'):
parentUrl2 = meta_1['parentUrl'][0:4] + "s" + meta_1['parentUrl'][4:-1]
if (each.extract().startswith(meta_1['parentUrl']) or each.extract().startswith(parentUrl2)) and each.extract().endswith('.shtml'):
item = NewsSinaItem()
item['parentUrl'] = meta_1['parentUrl']
item['parentTitle'] = meta_1['parentTitle']
item['subUrl'] = meta_1['subUrl']
item['subTitle'] = meta_1['subTitle']
item['subPath'] = meta_1['subPath']
item['sonUrl'] = each.extract()
items.append(item)
for each in items:
yield scrapy.Request(each['sonUrl'], meta = {'meta_2': each}, callback = self.detail_parse)
def detail_parse(self, response):
item = response.meta['meta_2']
if response.xpath('//*[@class="img_wrapper"]/img/@src'):
item['imgUrl'] = ''.join(response.xpath('//*[@class="img_wrapper"]/img/@src').extract()[0])
else:
item['imgUrl'] = ''
item['title'] = ''.join(response.xpath('//h1[@class="main-title"]/text()').extract()).strip()
item['content'] = ''.join(response.xpath('//div[@id="article"]/p/text() | //div[@id="artibody"]/p/text()').extract()).strip()
if item['content'] == '':
item['content'] = ''.join(response.xpath('//div[@id="article"]/div[1]/p/text() | //div[@id="artibody"]//div[1]/p/text()').extract()).strip()
if item['content'] == '':
item['content'] = item['title']
m1 = hashlib.md5()
m1.update(item['sonUrl'].encode('utf-8'))
item['md5'] = m1.hexdigest()
if item['title'] != '' and item['content'] != '':
yield item
另外在items.py中代码如下:

import scrapy
class NewsSinaItem(scrapy.Item):
md5 = scrapy.Field()
parentUrl = scrapy.Field()
parentTitle = scrapy.Field()
subUrl = scrapy.Field()
subTitle = scrapy.Field()
subPath = scrapy.Field()
sonUrl = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
imgUrl = scrapy.Field()
在pipelines中代码如下:

from scrapy.exporters import JsonLinesItemExporter
class NewsSinaPipeline(object):
def open_spider(self, spider):
print("---------- Start ----------")
def process_item(self, item, spider):
# 将数据写入到文件中
self.filename = item['sonUrl'][7:-6].replace('/','_') + '.txt'
self.file = open(item['subPath'] + '/' + self.filename, 'w')
data = item['title'] + '\n' + item['sonUrl'] + '\n' + item['subUrl'] + '\n' + item['imgUrl'] + '\n' + item['content']
self.file.write(data.encode("gbk", "ignore").decode("gbk", "ignore"))
self.file.close()
return item
def close_spider(self, spider):
print("---------- Close ----------")
另另另外,在settings.py中修改如下内容:

以上内容均修改完毕之后,就可以到项目根目录下输入:
scrapy crawl sina_news
开始爬取数据了,为了方便起见,可以在项目根目录下新建一个启动爬虫的文件start.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl sina_news".split())后面直接调用这个python文件即可启动爬虫:
python start.py
2 Scrapy的基本原理
如果在上一节你的爬虫已经跑了起来,恭喜您!
现在来简单说明一下Scrapy的基本工作原理,在前面的代码文件news.py中的几个知识点:

关于Scrapy详细的工作原理这里不详细说明,因为Scrapy只是我们获取数据的工具。
其基本的工作流程图如下图所示:
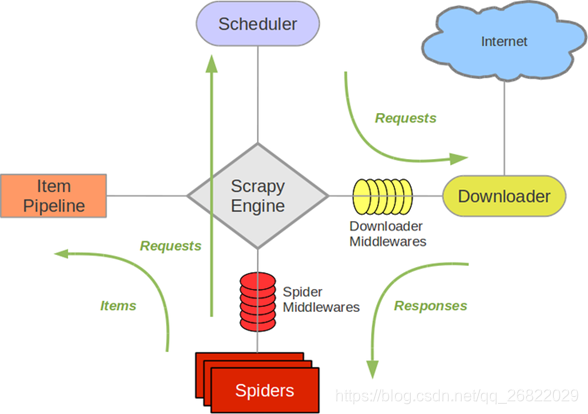
启动爬虫之后,首先Spiders将start_urls提交给Scheduler,Scheduler再依次将url一个一个提交给Downloader下载网页,下载下来的网页再返回给Sidpers(就是我们这里定义的爬虫)分析页面,Spiders将页面中过滤出的可用的url再提交给Scheduler,如果有调用yield item,则会将item数据提交给Item Pipeline处理(具体是存储到文件还是存储到数据库取决于用户自己如何实现,框架都已经由Scrapy搭建好了)。
好的本篇到这里圆满结束!