python 爬虫 入门 commit by commit -- commit2
"每一个commit都是程序员的心酸,哦不,心路历程的最好展示。" -- by 我自己
最近写好了一组文章,来这里,当然一如我以前一样,主要是宣传。但是,最近发现gitbook老是挂掉,除了宣传,我觉得,在这里全部贴一遍,这样就算是gitbook那边不稳定,至少这里还能看到。不过说实话,如果有兴趣的话,我还是推荐去gitbook那边看,因为博客园的结构,貌似不适合这种系列型的文章。
目前所有完结版本都已经可以在https://rogerzhu.gitbooks.io/python-commit-by-commit/content/ 看到,因为博客园一天只能贴一篇首页的文章,所以我可能需要一点时间把所有的都贴完。当然,你可以去gitbook上看已经完结的。而代码,我放在了https://github.com/rogerzhu/relwarcDJ ,里面有我完整的commit记录。有兴趣的话可以尽情star。 而且我觉得这里扯淡和准备篇的文字我就不贴了,有兴趣可以从上面的gitbook地址看到。
废话少说,搬运工作开始:
“程序员是最不会伪装但是又是最会伪装的群体”--by 我自己
在运行了第一个commit的程序我估计也就三分钟之内,你会觉得索然无味。图书的标题和链接到底有什么用呢?当然,我也有同样的疑问,所以,我决定在第二个commit中爬取这个首页我觉得我最关心的信息,那就是钱——图书的价格。
对于这个commit,当你输入如下命令开始运行时:

你应该能看到如下的结果:

有了第一个commit中的三板斧,我感觉我已经信心与感觉并存,动力与技术齐飞了。于是我熟练的使用了选取工具,选到了价格的方框。火狐的工具给我显示了,价格是在class名为p-price的div之内的。照葫芦画瓢一般的,使用BeautifulSoup的find,直接找到每个li中的这个div,熟练的保存好文件,开始用python运行。现实狠狠的给我了一个耳光,无论我怎么输出,这个价格都是拿不到的。
为什么?我对着屏幕思考了3分钟,毕竟如果思考再长的时间的话那只能说明我的拖延症犯了。我重新回到我需要的页面上,刷新了下页面,会看到价格信息会比其他的信息后出来,我又试了几次,这不是偶然,每次都不是同时出来的。这个时候凭借着我对web编程的一点粗浅的了解,我已经知道了,至少价格这个信息不是和html信息一起返回的。用在任何软件语言里都有的概念,这里一点存在有回调——callback。其实我在初学c++的时候对于这个概念不是很理解,但是如果你是第一次听到这个概念,在这里就特别形象,在某一件事情做完之后,又回头调用了一个什么接口或者文件等等来取得结果。
到了这一步,就需要一点大胆猜测小心求证的哲学了,当然,还有得知道一点webapi的基本概念。其实简单的说,就是调用一个url来获得返回的结果,这个url中可以使用&传入参数,而结果是一个文件的方式传到客户端。而继续前面所说的赠人玫瑰,手有余香的逻辑,你要爬取的这个网站的程序员们也要考虑维护问题,加上业界对于某些反复会出现的东西一定会有一套约定俗成的模式。说了这么多,到底想表达什么?既然我说webapi一般都是以文件的方式返回结果,那么怎么看到这些从服务器返回的文件呢?很完美的事,这件事,又可以使用F12来解决。
当你按下F12的时候会有很多tab,其中有一个叫network,这个下面会记录客户端与服务器端交互的所有内容。
既然是所有,那么确实有点多,而且在大多数情况下,他会在不停的滚动,让人很难操作。

这个时候只要你稍微网上看一点,就会发现,这些工具一定都会带有搜索功能的,毕竟,任何没有搜索功能的列表都是耍流氓。那么这个时候就到了大胆发挥猜想的时候了,按照我前面的说的,写程序的人为了维护一定会有某种比较共通的模式,既然价格是靠回调取出来的,那么不妨试试callback作为关键词?或者这个是价格,用price作为关键词?我选择用callback,没啥原因,只是因为我脑海里第一反应是想用这个。于是我得到如下的结果,但是很明显,一个网站上不可能只有一个callback。
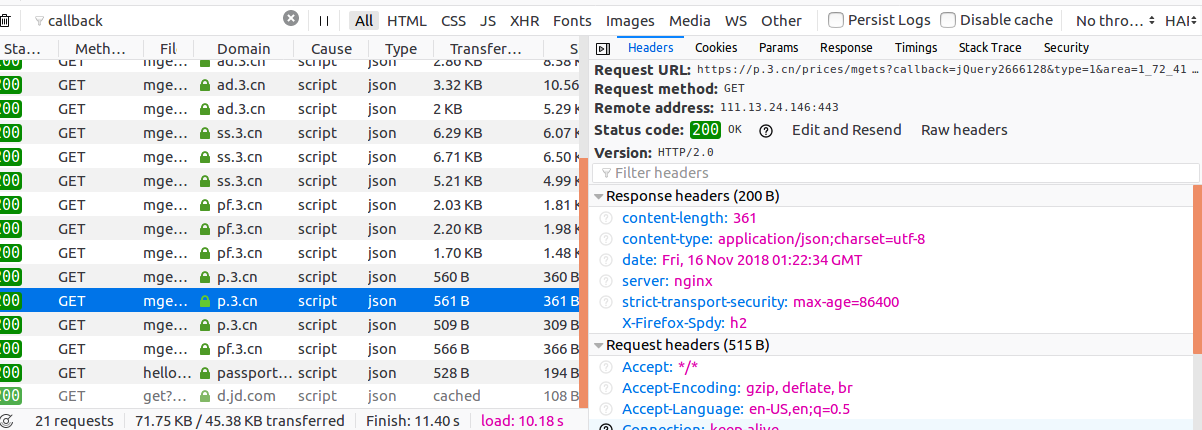
但是这已经少多了,最差的结果一个一个暴力寻找,找什么呢?找返回值,也就是右边有的response的tab,找什么返回值?因为每个callback当然都有返回值。当然找价格的数字了,既然你都能看到价格是多少钱,那么response中含有这个价格当然就是你需要的webapi的地址啦。而很明显,所有的callback返回的都是json字符串,如果你实在没有听过json,也没有关系,最简单的你可以把他理解成是一个带有格式的文本,这个文本的格式就是以逗号隔开的key,value字符串。于是我就这样暴力寻找,还真知道一个respons里面带有p:正确价格的字符串。这个时候可以再回头自己验证一下,怎么验证?我的方法就是看看这个请求的url,验证的方法还是本着良心程序员一定会把接口设计的另外一个程序员一看就懂的模式,吹的大一点,代码即文档。如果你看下这个请求的url,很明显,有个关键词告诉你,啊!这就是你要找的,那就是price,你可以在request URL中看到。你还可以再大胆的进一步,在这条记录上右键,所有的F12工具都有copy url的功能,拷贝下这个地址,放在浏览器上,回车,你会发现,你可以看到一条返回的json字符串。

仔细看看这些分会的字符串,虽然都是缩写,但是大概都能猜到是什么意思,比如p后面是价格,id后面是标识,至于op和m的意思,我猜是什么会员价和原价?不过没关系,这里面已经有了我们想要的信息了。那么想拿到价格的方法也很简单了,按照前面了的路子,只要访问这个网址然后拿到输出传给BeautifulSoup对象,就能完成解析了。但是,我们目前的想法是以一个书目,也就是一个list为一个Item,这个json字符串似乎一次性传回了很多个条目的价格。当然,可以通过字符串处理然后选取合适的容器来取出每个图书Item的价格。但这和我们的程序设计逻辑不搭,这东西就和写文章一样,行文逻辑不一致,会让读的人感到非常困难。放到代码上就是难以维护,那么,有什么办法可以一条一条的取出价格就好了。
这个时候,不妨回头看看获取到这个json返回值的url,因为webapi,参数就在url上,真正的谜底就在谜面上。你想想,我们想获取一个条目的价格,那么如果你写程序,一定是把这个条目的标识传进去,然后获取到价格。而我们现在使用的这个url有点长。

但仔细一看,很多都不知道是什么意思,职业的敏感让我把眼光放在skuIds这个参数上面,再看看传回来的参数,很明显,每一条单独的json条目都对应了这个传进去的一个Id。这个时候大胆尝试的念头又在我心中泛起,试试看只传进去一个参数。在浏览器中输入这条修改后的地址。

啊!你会发现就返回了一条skuIds的记录!再试试把Id改为其他的,发现也能行!并且每次都能得到正确的结果!所以说,勇敢尝试是成功的第一步。这个时候就可以使用这个URL了。但是这个URL中还有很多不知道干啥的参数,作为一个强迫症患者,试试看全部删除这些不需要的参数,就留下一个SkuIds试试。如果你真的试过,会发现不行。会给你返回一个error "pdos_captcha"。这看起来是步子迈大了,扯着蛋了。但是不多打一个字的惰性促使着我想看看能不能少一点,于是先从第一个callback=JQueryxxx的加起。
你会惊奇的发现,成了!但是你如果你多试几次,你可能会发现,你会失败!为什么?这就是在网络爬虫中的一个重要问题。如果一个网站的任意url可以被人任意的访问,那么势必会造成很多问题,不然验证码有不会被发明出来了。当你不能访问的时候,大多数时候因为对方网站的某种反爬虫机制已经将你的某种标识标记为机器人,然后给你返回一个错误的或者是无法获取的信息。
(好奇心重的人在这里可能会问,这个JQuery后面的数字是干啥的?我怎么知道这个数字从哪来?每一个书调用的callback=JQueryxxx的数字都不一样吗?那我要在哪里搞到这个数字?绝对的好问题,但是,如果你是那种手贱的人,你会发现这个数字任意改成啥都能得到结果,我改成了1,一样可以有结果。如果你对这个技术有兴趣的话,可以看这里。)
但是我们是真机器人啊!我们要做的是爬虫啊!所以如何在爬虫程序中把自己伪装成类人类上网就很重要。办法很多,其实总结出来,我个人感觉就记住两个关键词就行了,伪装和暂停。
先说伪装,怎么把机器人伪装成人呢?人是通过浏览器上网的,大多数现代人类肯定是这样上网的,你要用curl命令,这也算是一股清流了。那么回到F12上来,使用F12你是可以看到request的,而在request中间,你可以看到每个http都是有头部,这个头部里面包含了很多信息,比如使用了什么版本的浏览器,有的网站会要求在头部有某些特定的字段或者特定的信息,服务器端只有验证了这些信息才会返回正确的信息。如果你有一点了解http协议的话,其实只要我们能按照这里的格式构造出一个和浏览器访问一摸一样的http请求头,那么就可以模拟浏览器去访问页面,那服务器端是不可能分得清是人还是机器人的。
那么python如何做到这一点?作为一个对爬虫十分友好的语言,做到这一步也很简单,只要你把构造好的头部作为参数传进相应的函数,就可以完美的做到这一点。至于这些浏览器的头部信息怎样构造?搜索呀!这种模板网上一大堆,整个过程一如代码10-15行所示:

伪装成浏览器一般只是爬虫程序伪装的一部分,另外一部分是使用不同的代理IP。因为计算机程序访问一个网站资源的速率远远大于人类,这一点很明显很容易被服务器端所识别。而同一IP孜孜不倦的访问某一个网址,除非你是某网站的超级粉丝,不然一般正常人不会有这样的行为。而解决这个的办法,是随机选取一些IP,然后伪装成这些IP去访问网站。原理和伪装成浏览器头部差不多,说实话并不复杂。而我在我的爬虫程序中并没有用代理IP,原因很简单,就像我在前言里说的,我这并不是一个完全的商业化爬虫。当然,这就造成了你使用这个爬虫的时候有可能会导致返回错误,但是我可以说一个我用的方法,简单快速而又方便,用你的手机当热点,然后运行这些爬虫,一般都不会因为IP问题而封杀。你要问我为啥知道这样做,这就多亏了我做过网络编程方面的经验了。你可以把这个当做练习,当然也是因为我懒,实话,不过如果有幸我的这组文章能被广泛阅读而又有人要求看看如何使用代理IP的话,我会加上的。
剩下的就是我说的另外一个类别的招数了,因为人类的反应速度有限,你不可能在毫秒级别的不停的点击网页链接,所以一些超级简单的sleep同样也可以让你唬住服务器。怎么样让服务器觉得你不是机器人的方法说句不负责任的话,主要还是靠灵活运用,这里面颇有一种与人斗,其乐无穷的感觉。
基本上这个commit里面的理论扯淡部分就完了,那么接下来自然就是动手干代码了。
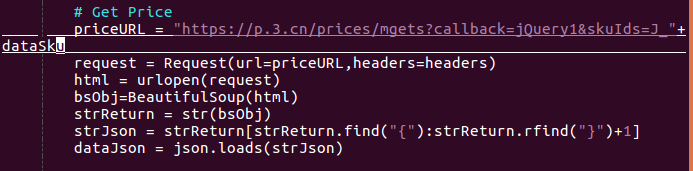
我写软件的设计,如果随意思考也能叫设计的话,逻辑就是一定要符合人的自然思维。而在貌似在第一个commit之内,我们缺少一个图书类目的唯一标示,而在前面价格的json字符串中,又明显有ID样的表示,所以,自然而然的我就想在我爬到的数据形成的结构中来这么一个玩意儿。在price中,可以看到这个id叫dataSku,虽然不知道这个缩写是什么意思,但是并不妨碍我去寻找这么一个东西。在返回的HTML中,有很多地方可以取到这个Id,比如,在第一个commit里取得的项目连接中就有。但是我一直本着别的程序员也得使自己的程序保持一致性的原则,我还是选取了一个叫p-o-btn focus J_focus这样的class名的一个超链接元素。这个超链接元素中有个key就叫data-sku,看起来抗迭代性最强。也就是代码第27,28行所示。

而接下来的代码就是我获取价格的逻辑了,从33行到40行,python的另一个完美之处就是其字典数据结构对json字符串完美对接,在去除掉不需要的字符之后,直接就可以得到完美的json字符串,通过key直接就能取得value。
再接着后面,我选择把爬到的数据结构都放到一个字典里面,但是这样做其实是有利有弊的。在我这种程序中,其实没啥比较好优势,甚至对于交互性上,是不方便的。但是如果你对爬到的数据还有比较多的后续处理,先将其存储到一个结构中是比较好的做法。
到这里,这个commit真的是没啥好讲的了。让我继续扯淡下一个commit吧。