"每一个commit都是程序员的心酸,哦不,心路历程的最好展示。" -- by 我自己
最近写好了一组文章,来这里,当然一如我以前一样,主要是宣传。但是,最近发现gitbook老是挂掉,除了宣传,我觉得,在这里全部贴一遍,这样就算是gitbook那边不稳定,至少这里还能看到。不过说实话,如果有兴趣的话,我还是推荐去gitbook那边看,因为博客园的结构,貌似不适合这种系列型的文章。
目前所有完结版本都已经可以在https://rogerzhu.gitbooks.io/python-commit-by-commit/content/ 看到,因为博客园一天只能贴一篇首页的文章,所以我可能需要一点时间把所有的都贴完。当然,你可以去gitbook上看已经完结的。而代码,我放在了https://github.com/rogerzhu/relwarcDJ ,里面有我完整的commit记录。有兴趣的话可以尽情star。 而且我觉得这里扯淡和准备篇的文字我就不贴了,有兴趣可以从上面的gitbook地址看到。
废话少说,搬运工作开始:
Commit1
"F12才是爬虫开发的最好的朋友" -- by 我自己
既然叫commit by commit,那就要按照自己给自己定下的规矩来写。在把代码clone到本地之后,你可以用git reset --hard 6fda96eae来退回到代码的第一个版本。别担心回不去后面的版本,这commit都在github都能看到,即使你不知道一些奇技淫巧的git命令也没啥,大胆干。
首先,我觉得我应该说这个commit我想干嘛,第一个commit,我是想作为熟悉的门槛,所以这个commit最开始我的本意是想获得京东图书编程语言第一页上面的书名,链接。
对于这个commit,当你输入如下命令开始运行时:

你应该能看到如下的结果:
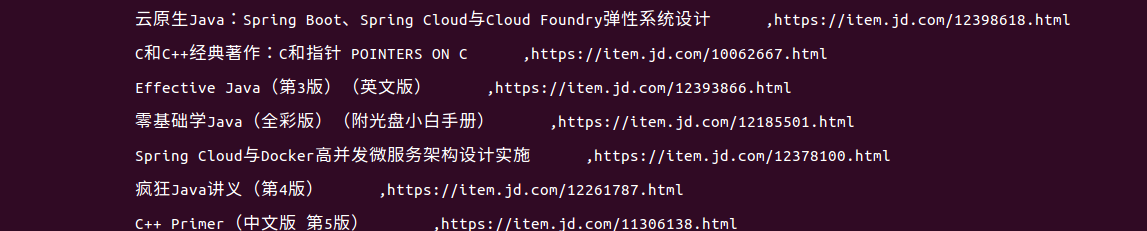
前面已经扯了两篇了,那么从这篇开始步入技术的正轨了,其实从骨子里我是很讨厌那种教程里敲半个小时代码,最后发现就是一个输出了一个星号组成的图案。我觉得,入门级别的代码得用不超过10分钟的时间干出一点你能看得到,有成就感的正事才能吸引大部分的注意力。可惜啊,C++在这方面确实很难做到,而python在这方面绝对是擅长。所以,第一个commit虽然我的comment是ugly commit,但是绝对能干活。
既然是入门级别的文章,那么就从最基本的部分开始,当你浏览一个网页的时候,实际上,你在浏览什么?实际上你在浏览的是服务器传回来的一系列文件,这一系列文件由浏览器解析,然后呈现给你。比如我想看看京东图书编程语言下面的所有图书,我只要用鼠标一点一点的点到我想要的地方就可以看到我需要的网页。
开心的是,主流浏览器都带有这种工具,而且获取这一组工具的方法都是只要简单的按下F12就可以了,我敢保证,当你按下这个键的时候,你有一种打开了新世界的感觉。比如我用的火狐,按下F12之后在最左边,你会看到这样一个图标:

点击一下这个图标再移到界面上,你会发现你可以以矩形的方式选择页面上的元素。根据人的本能,点击一下,你会发现图标下面的html会自动定义到选中的元素!这样,拿到什么信息,你只要负责选择就好了,浏览器自带的工具会自动帮你定位。比如,我想要的图书的名字和价格,我选中某一格的图书,就会看到这样的输出:

那么我就用上面说的小箭头选取到我决定的方块,可以得到标识这每一方块的元素是<li>。而在这个HTML中,有无数的li,我们怎么能定位到我们需要的这个li呢?这里,让我不得不想起一个谚语,叫赠人玫瑰手有余香。在前端程序员在开发他们的网页时,他们需要对元素进行标识,这样他们才能在代码中方便的写出想要的逻辑。而这个行为,给爬虫程序员们提供了便利,你可以用他们归类的标识来定位你需要的元素,当然,我这里说的是在代码里。而beautifulsoup这个包可以非常的方便的让你完成这件事情,你可以选择用id,class等等来找到你需要的元素。而在这里,如果你按照我说的使用箭头工具的话,会很容易的看到在这个网页中gl-item这样的class来标识每一个列表块。那么剩下的就是按照已经发现的,翻译成为程序语言了。
在第一个commit里面,代码一共22行,我都忍不住用截图的方式展示一下以便于说明。
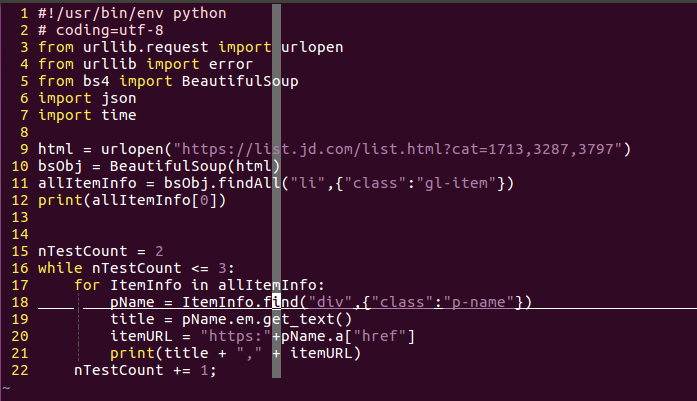
这个代码前7行都是shebang,coding的设置和import包。这里你不知道shebang也一点也不影响你对于这一系列问斩的阅读理解。所以说,正文从第九行看起就行了。
首先python提供了非常方便的方法获取网页的源码,我以前最开始的时候使用C++写过爬虫,怎么形容呢?如果python爬虫的给力程度是他娘的意大利炮,那么c++就是纯物理攻击了。你只需要使用urllib中的request.urlopen就能直接获取到网页源码。而需要的参数仅仅是网页的url。一如第九行所示。
当有了源码之后,按照前面介绍的逻辑,就是寻找对应的元素了,而这个时候就是BeautifulSoup包上场的时候了,把得到的源码字符串作为参数传给BeautifulSoup库,你就会得到一个强大的方便解析的BeautifulSoup对象。而在BeautifulSoup中,使用findAll你就可以找到全部的带有某种标识的某种元素。比如说,在我们要爬取的页面上,有很多的书,而我们又知道每个书所存在的块是以gl-item的class来标识的列表,那么只要对findAll传入元素名称和标识规则就行了。而BeautifulSoup还提供一个find函数,用来找到第一个符合标识的对象。
既然已经得到需要的一大块了,剩下的就是在这一大块中找到自己想要的信息,比如我想要的书名和链接地址。其实这后面的过程就是前面描述的过程的重复。大致就是找到页面->按下F12->使用选择工具->找到对应的元素块。但是程序员嘛,都很懒,能少动几下鼠标是几下,所以,如果一个块中元素规模不大的并且基本都相像的情况下,我会使用这样的一种办法:把一大块的html片段输出到一个文件里。如果你觉得我说的有点绕了,那么其实我想表达的就是第12行语句的意思,虽然我这里用的是print,但是你可以使用重定向的功能将这个输出到一个文件中,也就是"> item.txt"类似的语句。而如果你查看这个commit的目录结构,你就会看到这么一个文件。如果好奇心仍驱使你打开它,那么你就可以看到一个li中的所有内容。这样就省去了前面那四个步骤的烦恼,而且你可以反复查看,而不用反复的打开浏览器。

当然,这是在我下面的循环还没有写出来的时候先输出的。
谈到这个while循环,在这里你可以完全忽略,或者说你可能会揣测这到底有什么深意。其实没啥深意,就是为了后面用的,而且还是比较后面的commit中才会用到。我只是有点懒,懒得删除。实际上,这个程序的第15,16以及22行完全可以删除,对于最后的结果完全没有任何影响。
而这里的for循环是肯定必要的。python的语法,按照其cookbook上说,已经非常接近自然语言了,从有的方面看真的是这样的,比如说第17行,表示是依次取出allItem中的所有元素,对于每一个元素就是一个li块,剩下的只要从这些li块中再继续寻找需要的信息就可以了。比如,书的标题实在class为p-name的div元素之中。而在这个页面上,真正的标题文字是放在强调标签<em>之中。这都不能难住强大的BeautifulSoup库,其对象可以像访问结构中成员一般一层一层的找到需要的元素。如果想要获得某个标签中的文字,只需要使用get_text函数就可以获得。用代码说话的话就是18,19行。
而有的时候我们不是要获取某个标签中的元素,而是要获取某个标签中的属性怎么办?BeautifulSoup用近乎完全符合自然思维的方式实现了这一点。比如超链接,一般都是在<a>标签中href属性之中,那么href就是a这个成员(字典)的一个关键词,通过这个关键词,你就可以取得其中的值,一如你看到的href="xxx"一样,典型的key,value结构。也就是程序的第20行,通过这样的方式,就可以取得每个图书的链接。
剩下来,就是你怎么呈现这个数据的部分了,我这里就简单大方而又明了的输出,keep it simple,stupid。
这里,第一个commit就结束了,去掉不需要while循环,一共就19行代码,在环境配好的情况下,无脑敲完不需要5分钟,运行python myGAND.py,你就可以看到京东图书编程语言第一页的书名和链接打印在控制台或者文件中。说实话,如果是C++,你可能还在写各种字符串解析函数的过程中。