目录
7.Horizontal Pod Autoscaler TODO
1.Master
Kubernetes⾥的Master指的是集群控制节点,在每个Kubernetes集群⾥都需要有⼀个Master来负责整个集群的管理和控制,基本上 Kubernetes的所有控制命令都发给它,它负责具体的执⾏过程,我们后 ⾯执⾏的所有命令基本都是在Master上运⾏的。Master通常会占据⼀个独⽴的服务器(⾼可⽤部署建议⽤3台服务器),整个集群的“⾸脑”,如果它宕机或者不可⽤,那么对集群内容器应⽤的管理都将失效。
1.1在Master上运⾏着以下关键进程
Kubernetes API Server(kube-apiserver):提供了HTTP Rest接⼝的关键服务进程,是Kubernetes⾥所有
资源的增、删、改、查等操作的唯⼀⼊⼝,也是集群控制的⼊⼝进程。
Kubernetes Controller Manager(kube-controller-manager): Kubernetes⾥所有资源对象的⾃动化控
制中⼼,可以将其理解为资源对象的“⼤总管”。
Kubernetes Scheduler(kube-scheduler):负责资源调度(Pod调度)的进程,相当于公交公司的“调度
室”。
另外,在Master上通常还需要部署etcd服务,因为Kubernetes⾥的所有资源对象的数据都被保存在etcd中。
2.什么是Node?
与Master⼀样,Node可以是⼀台物理主机,也可以是⼀台虚拟机。Node是Kubernetes集群中的⼯作负载节
点,每个 Node都会被Master分配⼀些⼯作负载(Docker容器),当某个Node宕机时,其上的⼯作负载会被
Master⾃动转移到其他节点上。
1.2在每个Node上都运⾏着以下关键进程
Kubelet: 负责Pod对应的容器创建,启停等任务,同时与Master密切协作,实现集群管理的基本功能。
kube-proxy: 实现Kubernetes Service的通信与负载均衡机制的重要组件。
Docker Engine (Docker): Docker引擎,负责本机的容器创建和管理⼯作。
kubectl get nodes3.什么是 Pod ?
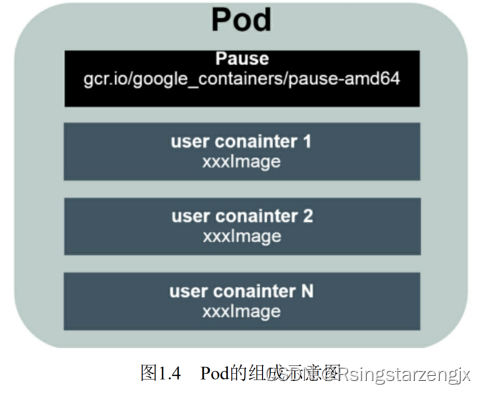
Pod是Kubernetes最重要的基本概念
每个Pod都有⼀个特殊的被称为“根容器”的Pause容器。Pause容器对应的镜像属于Kubernetes平台的⼀部分,除了Pause容器, 每个Pod还包含⼀个或多个紧密相关的⽤户业务容器。

4. 什么是Label ?
⼀个Label是⼀个key=value的键值对,其中key与
value由⽤户⾃⼰指定。Label可以被附加到各种资源对象上,例如Node、Pod、Service、RC等,⼀个资源对象可以定义任意数量的Label,同⼀个Label也可以被添加到任意数量的资源对象上。Label通常在资源对象定义时确定,也可以在对象创建后动态添加或者删除。
我们可以通过给指定的资源对象捆绑⼀个或多个不同的Label来实现多维度的资源分组管理功能,以便灵活、⽅便地进⾏资源分配、调度、配置、部署等管理⼯作。例如,部署不同版本的应⽤到不同的环境中;监控和分析应⽤(⽇志记录、监控、告警)等。⼀些常⽤的Label示例如下。
版本标签:"release":"stable"、"release":"canary"。
环境标签:"environment":"dev"、"environment":"qa"、"environment":"production"。
架构标签:"tier":"frontend"、"tier":"backend"、"tier":"middleware"。
分区标签:"partition":"customerA"、"partition":"customerB"。
质量管控标签:"track":"daily"、"track":"weekly"。
可以通过多个Label Selector表达式的组合实现复杂的条件选择,多个表达式之间⽤“,”进⾏分隔即可,⼏个条件
之间是“AND”的关系,即同时满⾜多个条件,⽐如下⾯的例⼦:
name=redis-slave,env!=production
name notin (php-frontend),env!=production以myweb Pod为例,Label被定义在其metadata中:
apiVersion: v1
kind: Pod
metadata:
name: web
labels:
app: web管理对象RC和Service则通过Selector字段设置需要关联Pod的 Label:
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 1
selector:
app: myweb
template:
......
apiVersion: v1
kind: Service
metadata:
name: myweb
spec:
selector:
app: myweb
ports:
- port: 8080其他管理对象如Deployment、ReplicaSet、DaemonSet和Job则可以在Selector中使⽤基于集合的筛选条件定义
例如:
selector:
matchLables:
app: web
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
- {key: environmetn, operator: NotIn, value: [dev]}matchLabels⽤于定义⼀组Label,与直接写在Selector中的作⽤相同;matchExpressions⽤于定义⼀组基于集合的筛选条件,可⽤的条件 运算符包括In、NotIn、Exists和DoesNotExist。
如果同时设置了matchLabels和matchExpressions,则两组条件为AND关系,即需要同时满⾜所有条件才能完成Selector的筛选。
Label Selector在Kubernetes中的重要使⽤场景如下
kube-controller进程通过在资源对象RC上定义的Label Selector来筛选要监控的Pod副本数量,使Pod副本数
量始终符合预期设定的全⾃动控制流程。
kube-proxy进程通过Service的Label Selector来选择对应的Pod, ⾃动建⽴每个Service到对应Pod的请求转
发路由表,从⽽实现Service的智能负载均衡机制。
通过对某些Node定义特定的Label,并且在Pod定义⽂件中使⽤NodeSelector这种标签调度策略,kube-scheduler进程可以实现Pod定向调度的特性。
5.Replication Controller
RC是Kubernetes系统中的核⼼概念之⼀,简单来说,它其实定义了⼀个期望的场景,即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包括如下⼏个部分。
Pod期待的副本数量
⽤于筛选⽬标Pod的Label Selector
当Pod的副本数量⼩于预期数量时,⽤于创建新Pod的Pod模板(template)
下⾯是⼀个完整的RC定义的例⼦,即确保拥有tier=frontend标签的这个Pod(运⾏Tomcat容器)在整个
Kubernetes集群中始终只有⼀个副本:
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
spec:
replicas: 1
selector:
tier: frontend
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat
imagePullPolicy: IfNotPresent
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 806.Deployment
Deployment相对于RC的⼀个最⼤升级是我们可以随时知道当前Pod“部署”的进度。实际上由于⼀个Pod的创建、调度、绑定节点及在⽬标Node上启动对应的容器这⼀完整过程需要⼀定的时间,所以我们期待系统启动N个Pod副本的⽬标状态,实际上是⼀个连续变化的“部署过程”导致的最终状态。
6.1Deployment的典型场景:
创建一个Deployment对象来生成对应的Repplicat Set 并完成Pod副本的创建
检查Deployment 的状态来看部署是否完成(Pod 副本数量是否达到预期的值)
更新Deployment以创建新的Pod(⽐如镜像升级)
如果当前Deployment不稳定,则回滚到⼀个早先的Deployment版本
暂停Deployment以便于⼀次性修改多个PodTemplateSpec的配置项,之后再恢复Deployment,进⾏新的发布扩展Deployment以应对⾼负载
查看Deployment的状态,以此作为发布是否成功的指标
清理不再需要的旧版本ReplicaSets
创建⼀个名为tomcat-deployment.yaml的Deployment
描述⽂件,内容如下:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 1
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080对上述输出中涉及的数量解释如下
$ kubectl get deploymentsDESIRED:Pod副本数量的期望值,即在Deployment⾥定义的Replica
CURRENT:当前Replica的值,实际上是Deployment创建的Replica Set⾥的Replica值,这个值不断增加,直
到达到DESIRED为⽌,表明整个部署过程完成
UP-TO-DATE:最新版本的Pod的副本数量,⽤于指示在滚动升级的过程中,有多少个Pod副本已经成功升级
AVAILABLE:当前集群中可⽤的Pod副本数量,即集群中当前存活的Pod数量
运⾏下述命令查看对应的Replica Set,我们看到它的命名与Deployment的名称有关系
kubectl get rs7.Horizontal Pod Autoscaler TODO
Horizontal Pod Autoscaling(Pod横向⾃动扩容,HPA)
HPA与之前的RC、Deployment⼀样,也属于⼀种Kubernetes资源对象。通过追踪分析指定RC控制的所有⽬标
Pod的负载变化情况,来确定是否需要有针对性地调整⽬标Pod的副本数量,这是HPA的实现原理。 当前,HPA有
以下两种⽅式作为Pod负载的度量指标。
CPUUtilizationPercentage
应⽤程序⾃定义的度量指标,⽐如服务在每秒内的相应请求数(TPS或QPS)
CPUUtilizationPercentage是⼀个算术平均值,即⽬标Pod所有副本⾃身的CPU利⽤率的平均值。⼀个Pod⾃
身的CPU利⽤率是该Pod当前CPU的使⽤量除以它的Pod Request的值,⽐如定义⼀个Pod的Pod Request为0.4,
⽽当前Pod的CPU使⽤量为0.2,则它的CPU使⽤率为50%,这样就可以算出⼀个RC控制的所有Pod副本的CPU利⽤
率的算术平均值了。如果某⼀时刻CPUUtilizationPercentage的值超过80%,则意味着当前Pod副本数量很可能不
⾜以⽀撑接下来更多的请求,需要进⾏动态扩容,⽽在请求⾼峰时段过去后,Pod的CPU利⽤率⼜会降下来,此时
对应的Pod副本数应该⾃动减少到⼀个合理的⽔平。如果⽬标Pod没有定义Pod Request的值,则⽆法使⽤
CPUUtilizationPercentage实现Pod横向⾃动扩容。除了使⽤CPUUtilizationPercentage,Kubernetes从1.2版本
开始也在 尝试⽀持应⽤程序⾃定义的度量指标
下⾯是HPA定义的⼀个具体例⼦:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 90根据上⾯的定义,我们可以知道这个HPA控制的⽬标对象为⼀个名为php-apache的Deployment⾥的Pod副
本,当这些Pod副本的 CPUUtilizationPercentage的值超过90%时会触发⾃动动态扩容⾏为,在扩容或缩容时必须
满⾜的⼀个约束条件是Pod的副本数为1~10
除了可以通过直接定义YAML⽂件并且调⽤kubectrl create的命令来创建⼀个HPA资源对象的⽅式,还可以通
过下⾯的简单命令⾏直接创建等价的HPA对象:
$ kubectl autoscale deployment php-apache --cpu-percent=90 --min=1 --max=108.StatefulSet
在Kubernetes系统中,Pod的管理对象RC、Deployment、DaemonSet和Job都⾯向⽆状态的服务。但现实中
有很多服务是有状态的,特别是⼀些复杂的中间件集群,例如MySQL集群、MongoDB集群、kafka集群、
ZooKeeper集群等,这些应⽤集群有4个共同点
每个节点都有固定的身份ID,通过这个ID,集群中的成员可以相互发现并通信
集群的规模是⽐较固定的,集群规模不能随意变动
集群中的每个节点都是有状态的,通常会持久化数据到永久存储中
如果磁盘损坏,则集群⾥的某个节点⽆法正常运⾏,集群功能受损
StatefulSet特性
StatefulSet⾥的每个Pod都有稳定、唯⼀的⽹络标识,可以⽤来发现集群内的其他成员。假设StatefulSet的名
称为kafka,那么第1个Pod叫kafka-0,第2个叫kafka-1,以此类推
StatefulSet控制的Pod副本的启停顺序是受控的,操作第n个Pod时,前n-1个Pod已经是运⾏且准备好的状态
StatefulSet⾥的Pod采⽤稳定的持久化存储卷,通过PV或PVC来实现,删除Pod时默认不会删除与StatefulSet
相关的存储卷(为了保证数据的安全)
StatefulSet除了要与PV卷捆绑使⽤以存储Pod的状态数据,还要与Headless Service配合使⽤,即在每个StatefulSet定义中都要声明它属于 哪个Headless Service。Headless Service与普通Service的关键区别在于, 它没有Cluster IP,如果解析Headless Service的DNS域名,则返回的是该 Service对应的全部Pod的Endpoint列表。
StatefulSet在Headless Service的 基础上⼜为StatefulSet控制的每个Pod实例都创建了⼀个DNS域名,这个 域名的
格式为:
$(podname).$(headless service name)
⽐如⼀个3节点的Kafka的StatefulSet集群对应的Headless Service的名称为kafka,StatefulSet的名称为kafka,则
StatefulSet⾥的3个Pod的DNS 名称分别为kafka-0.kafka、kafka-1.kafka、kafka-3.kafka,这些DNS名称可以直接
在集群的配置⽂件中固定下来
9.Service
Service服务也是Kubernetes⾥的核⼼资源对象之⼀,Kubernetes⾥的每个Service其实就是我们经常提起的微服务架构中的⼀个微服务,之前讲解Pod、RC等资源对象其实都是为讲解Kubernetes Service做铺垫的

Service 定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口访问其背后的一组由Pod 副本组成的集群实例,Service 与其后端Pod 副本集群之间则是通过label Selector 来实现无缝对接的。RC 的作用实际上是保证Service 的服务能力和服务质量始终符合预期标准。
9.1 外部系统访问Service的问题
Kubernetes⾥ 的3种IP
Node IP:Node的IP地址
Pod IP:Pod的IP地址
Cluster IP:Service的IP地址
Node IP是Kubernetes集群中每个节点的物理⽹卡的IP地址, 是⼀个真实存在的物理⽹络,所有属于这个⽹络的服务器都能通过这个⽹络直接通信,不管其中是否有部分节点不属于这个Kubernetes集群。 这也表明在Kubernetes集群之外的节点访问Kubernetes集群之内的某个节点或者TCP/IP服务时,都必须通过Node IP通信。
Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0 ⽹桥的IP地址段进⾏分配的,通常是⼀个虚拟的⼆层⽹络,前⾯说过, Kubernetes要求位于不同Node上的Pod都能够彼此直接通信,所以 Kubernetes⾥⼀个Pod⾥的容器访问另外⼀个Pod⾥的容器时,就是通过 Pod IP所在的虚拟⼆层⽹络进⾏通信的,⽽真实的TCP/IP流量是通过 Node IP所在的物理⽹卡流出的。
Service的Cluster IP,它也是⼀种虚拟的IP,但更像⼀个“伪造”的IP⽹络,原因有以下⼏点
Cluster IP仅仅作⽤于Kubernetes Service这个对象,并由 Kubernetes管理和分配IP地址(来源于Cluster IP地址池)Cluster IP⽆法被Ping,因为没有⼀个“实体⽹络对象”来响应
Cluster IP只能结合Service Port组成⼀个具体的通信端⼝,单独 的Cluster IP不具备TCP/IP通信的基础,并且它们属于Kubernetes集群这 样⼀个封闭的空间,集群外的节点如果要访问这个通信端⼝,则需要做 ⼀些额外的⼯作在Kubernetes集群内,Node IP⽹、Pod IP⽹与Cluster IP⽹之间的通信,采⽤的是Kubernetes⾃⼰设计的⼀种编程⽅式的特殊路由规 则,与我们熟知的IP路由有很⼤的不同。
根据上⾯的分析和总结,我们基本明⽩了:Service的Cluster IP属于 Kubernetes集群内部的地址,⽆法在集
群外部直接使⽤这个地址。那么 ⽭盾来了:实际上在我们开发的业务系统中肯定多少有⼀部分服务是要提供给
Kubernetes集群外部的应⽤或者⽤户来使⽤的,典型的例⼦就是 Web端的服务模块,⽐如上⾯的tomcat-service,那么⽤户怎么访问它?采⽤NodePort是解决上述问题的最直接、有效的常⻅做法。以 tomcat-service为例,在Service的定义⾥做如
下扩展即可(⻅代码中的粗 体部分):

其中,nodePort:31002这个属性表明⼿动指定tomcat-service的NodePort为31002,否则Kubernetes会⾃动分配⼀个可⽤的端⼝。接下来 在浏览器⾥访问http://:31002/,就可以看到Tomcat的欢迎界⾯了NodePort的实现⽅式是在Kubernetes集群⾥的每个Node上都为需要外部访问的Service开启⼀个对应的TCP监听端⼝,外部系统只要⽤任意⼀个Node的IP地址+具体的NodePort端⼝号即可访问此服务,在任意Node上运⾏netstat命令,就可以看到有NodePort端⼝被监听:

但NodePort还没有完全解决外部访问Service的所有问题,⽐如负载均衡问题。假如在我们的集群中有10个Node,则此时最好有⼀个负载均衡器,外部的请求只需访问此负载均衡器的IP地址,由负载均衡器负责转发流量到后⾯某个Node的NodePort上,如图1.15所示

图1.15中的Load balancer组件独⽴于Kubernetes集群之外,通常是⼀个硬件的负载均衡器,或者是以软件⽅式实现的,例如HAProxy或者 Nginx。对于每个Service,我们通常需要配置⼀个对应的Load balancer实例来转发流量到后端的Node上,这的确增加了⼯作量及出错的概率。于是Kubernetes提供了⾃动化的解决⽅案,如果我们的集群运⾏在⾕歌的公有云GCE上,那么只要把Service的type=NodePort改为 type=LoadBalancer,Kubernetes会⾃动创建⼀个对应的Load balancer实例并返回它的IP地址供外部客户端使⽤。其他公有云提供商只要实现了⽀持此特性的驱动,则也可以达到上述⽬的。此外,裸机上的类似机制 (Bare Metal Service Load Balancers)也在被开发.
10.Job
批处理任务Job,与RC,Deployment 、ReplicaSet、DaemonSet 类似,Job 也控制一组Pod容器。从这个角度来看,Job 也是特殊的Pod 副本自动控制,同时Job 控制Pod副本与RC 等控制器的工作机制有一下区别:
(1)Job所控制的Pod副本是短暂运⾏的,可以将其视为⼀组 Docker容器,其中的每个Docker容器都仅仅运
⾏⼀次。当Job控制的所有Pod副本都运⾏结束时,对应的Job也就结束了。Job在实现⽅式上与 RC等副本控制器不
同,Job⽣成的Pod副本是不能⾃动重启的,对应Pod 副本的RestartPoliy都被设置为Never。因此,当对应的Pod副本都执⾏完 成时,相应的Job也就完成了控制使命,即Job⽣成的Pod在Kubernetes中 是短暂存在的。Kubernetes在1.5版本之后⼜提供了类似crontab的定时任 务——CronJob,解决了某些批处理任务需要定时反复执⾏的问题。
(2)Job所控制的Pod副本的⼯作模式能够多实例并⾏计算,以TensorFlow框架为例,可以将⼀个机器学习的计算任务分布到10台机器上,在每台机器上都运⾏⼀个worker执⾏计算任务,这很适合通过Job⽣成10个Pod副本同时启动运算。
11.Volume存储卷
Volume(存储卷)是Pod中能够被多个容器访问的共享⽬录。 Kubernetes的Volume概念、⽤途和⽬的与Docker的Volume⽐较类似,但 两者不能等价。⾸先,Kubernetes中的Volume被定义在Pod上,然后被 ⼀个Pod⾥的多个容器挂载到具体的⽂件⽬录下;其次,Kubernetes中的 Volume与Pod的⽣命周期相同,但与容器的⽣命周期不相关,当容器终 ⽌或者重启时,Volume中的数据也不会丢失。最后,Kubernetes⽀持多种类型的Volume,例如GlusterFS、Ceph等先进的分布式⽂件系统。
在Pod上声明 ⼀个Volume,然后在容器⾥引⽤该Volume并挂载(Mount)到容器⾥的 某个⽬录上。举例来说,我们要给之前的Tomcat Pod增加⼀个名为 datavol的Volume,并且挂载到容器的/mydata-data⽬录上,则只要对Pod 的定义⽂件做如下修正即可(注意代码中的粗体部分):

12. Persistent Volume
之前提到的Volume是被定义在Pod上的,属于计算资源的⼀部分, ⽽实际上,⽹络存储是相对独⽴于计算资源⽽存在的⼀种实体资源。⽐ 如在使⽤虚拟机的情况下,我们通常会先定义⼀个⽹络存储,然后从中 划出⼀个“⽹盘”并挂接到虚拟机上。Persistent Volume(PV)和与之相 关联的Persistent Volume Claim(PVC)也起到了类似的作⽤。
PV可以被理解成Kubernetes集群中的某个⽹络存储对应的⼀块存储,它与Volume类似,但有以下区别。
PV只能是⽹络存储,不属于任何Node,但可以在每个Node上访问。
PV并不是被定义在Pod上的,⽽是独⽴于Pod之外定义的。
PV⽬前⽀持的类型包括:gcePersistentDisk、 AWSElasticBlockStore、AzureFile、AzureDisk、FC(FibreChannel)、
Flocker、NFS、iSCSI、RBD(Rados Block Device)、CephFS、 Cinder、GlusterFS、VsphereVolume、Quobyte Volumes、VMware Photon、Portworx Volumes、ScaleIO Volumes和HostPath(仅供单机测试)
下⾯给出了NFS类型的PV的⼀个YAML定义⽂件,声明了需要5Gi 的存储空间:
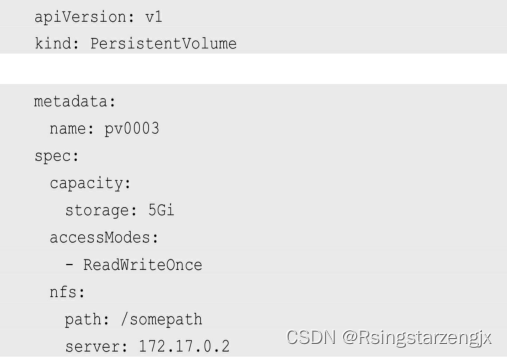
⽐较重要的是PV的accessModes属性,⽬前有以下类型。
◎ ReadWriteOnce:读写权限,并且只能被单个Node挂载。
◎ ReadOnlyMany:只读权限,允许被多个Node挂载。
◎ ReadWriteMany:读写权限,允许被多个Node挂载。
如果某个Pod想申请某种类型的PV,则⾸先需要定义⼀个 PersistentVolumeClaim对象

然后,在Pod的Volume定义中引⽤上述PVC即可:

最后说说PV的状态。PV是有状态的对象,它的状态有以下⼏种。
◎ Available:空闲状态。
◎ Bound:已经绑定到某个PVC上。
◎ Released:对应的PVC已经被删除,但资源还没有被集群收 回。
◎ Failed:PV⾃动回收失败。
13.Namespace
Namespace(命名空间)是Kubernetes系统中的⾮常重要的概念,Namespace在很多情况下⽤于实现多租户的资源隔离。Namespace 通过将集群内部的资源对象“分配”到不同的Namespace中,形成逻辑上分组的不同项⽬、⼩组或⽤户组,便于不同的分组在共享使⽤整个集群的资源的同时还能被分别管理。
Kubernetes集群在启动后会创建⼀个名为default的Namespace,通过kubectl可以查看:

14.Annotation
Annotation(注解)与Label类似,也使⽤key/value键值对的形式进⾏定义。不同的是Label具有严格的命名规则,它定义的是Kubernetes对象的元数据(Metadata),并且⽤于Label Selector。Annotation则是⽤户 任意定义的附加信息,以便于外部⼯具查找。在很多时候,Kubernetes的模块⾃身会通过Annotation标记资源对象的⼀些特殊信息通常来说,⽤Annotation来记录的信息如下
build信息、release信息、Docker镜像信息等,例如时间戳、 release id号、PR号、镜像Hash值、DockerRegistry地址等⽇志库、监控库、分析库等资源库的地址信息程序调试⼯具信息,例如⼯具名称、版本号等团队的联系信息,例如电话号码、负责⼈名称、⽹址等。
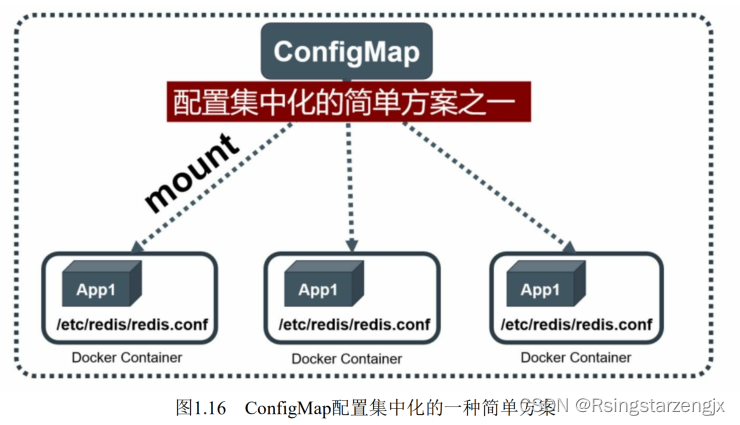
15.ConfigMap
为了能够准确和深刻理解Kubernetes ConfigMap的功能和价值,我们需要从Docker说起。我们知道,
Docker通过将程序、依赖库、数据及配置⽂件“打包固化”到⼀个不变的镜像⽂件中的做法,解决了应⽤的部署的难
题,但这同时带来了棘⼿的问题,即配置⽂件中的参数在运⾏期如何修改的问题。我们不可能在启动Docker容器后
再修改容器⾥的配置⽂件,然后⽤新的配置⽂件重启容器⾥的⽤户主进程。为了解决这个问题,Docker提供了两种⽅式:
在运⾏时通过容器的环境变量来传递参数
通过Docker Volume将容器外的配置⽂件映射到容器内
这两种⽅式都有其优势和缺点,在⼤多数情况下,后⼀种⽅式更合适我们的系统,因为⼤多数应⽤通常从⼀个或多个配置⽂件中读取参数。但这种⽅式也有明显的缺陷:我们必须在⽬标主机上先创建好对应的配置⽂件,然后才能映射到容器⾥。
k8s设计:
⾸先,把所有的配置项都当作key-value字符串,当然value可以来⾃ 某个⽂本⽂件,⽐如配置项
password=123456、user=root、 host=192.168.8.4⽤于表示连接FTP服务器的配置参数。这些配置项可以 作为Map表中的⼀个项,整个Map的数据可以被持久化存储在 Kubernetes的Etcd数据库中,然后提供API以⽅便Kubernetes相关组件或客户应⽤CRUD操作这些数据,上述专⻔⽤来保存配置参数的Map就是Kubernetes ConfigMap资源对象
Kubernetes提供了⼀种内建机制,将存储在etcd中的ConfigMap通过Volume映射的⽅式变成⽬标
Pod内的配置⽂件,不管⽬ 标Pod被调度到哪台服务器上,都会完成⾃动映射。进⼀步地,如果ConfigMap中的
key-value数据被修改,则映射到Pod中的“配置⽂件”也会随之⾃动更新。于是,Kubernetes ConfigMap就成了分
布式系统中最为简单(使⽤⽅法简单,但背后实现⽐较复杂)且对应⽤⽆侵⼊的配置中⼼