大数据是什么?对于“大数据”(Big data)研究机构Gartner给出了这样的定义。“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和多样化的信息资产。
而麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
随着云时代的来临,大数据也吸引了越来越多的关注,数据也就越发体现出其价值及其重要性,那么我们如何去获取这些数据呢?一个个复制粘贴,那工程量也太过浩大了,是否有什么软件能够帮助我们采集这些数据,并且能够直接使用的呢。
为了满足用户这一需求,后羿工程师团队经过不断的探索和研发,终于开发出一款基于人工智能技术的网络爬虫软件,只需要输入网址就能够自动识别网页数据,无需配置即可完成数据采集,是业内首家支持三种操作系统(包括Windows、Mac和Linux)的采集软件。同时这是一款真正免费的数据采集软件,对采集结果导出没有任何限制,没有编程基础的小白用户也可轻松实现数据采集要求。
那么这款爬虫工具要怎么使用呢,我们以同花顺圈子的评论数据为例,为大家演示如何使用这款软件。
首先复制所要采集的网址,打开软件输入网址新建智能采集模式。
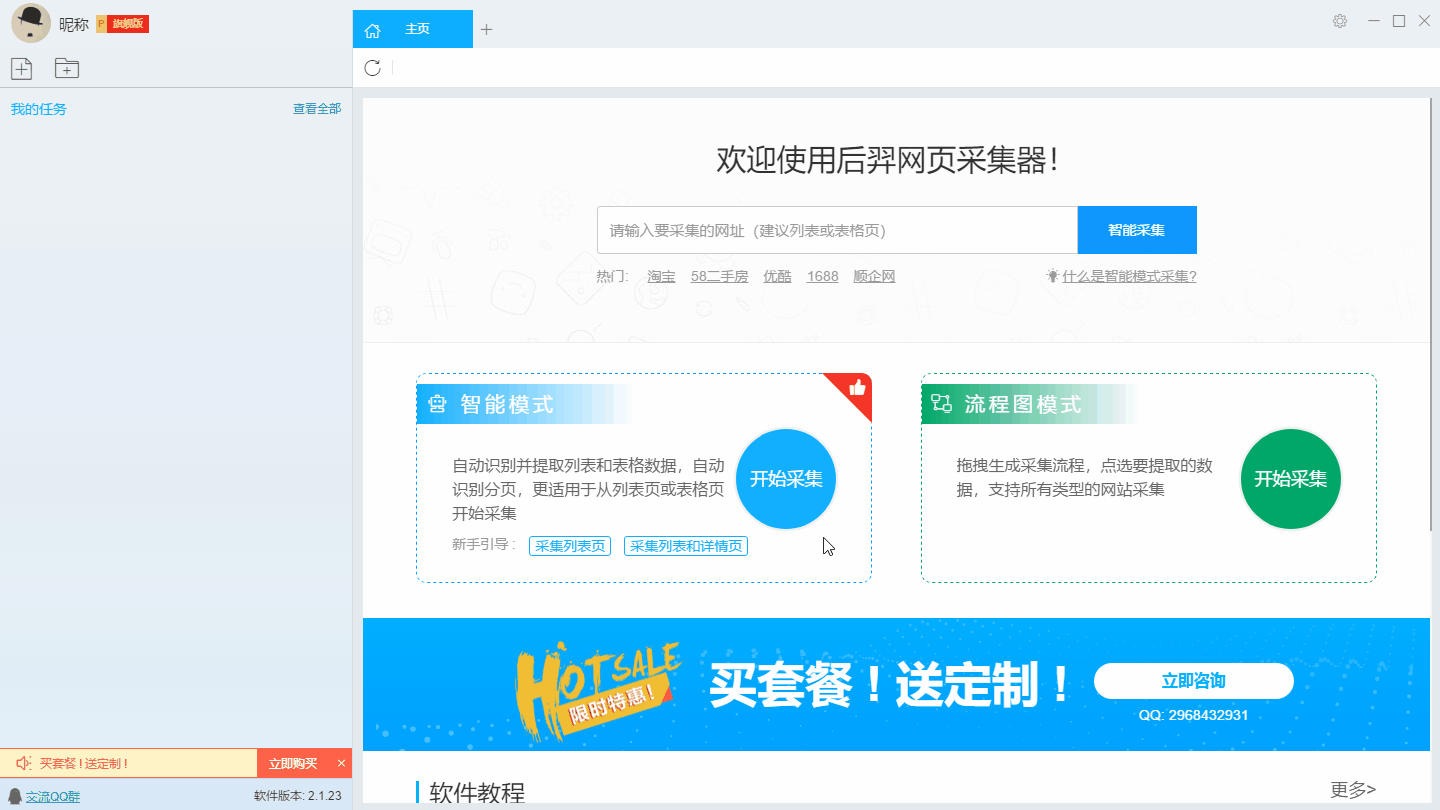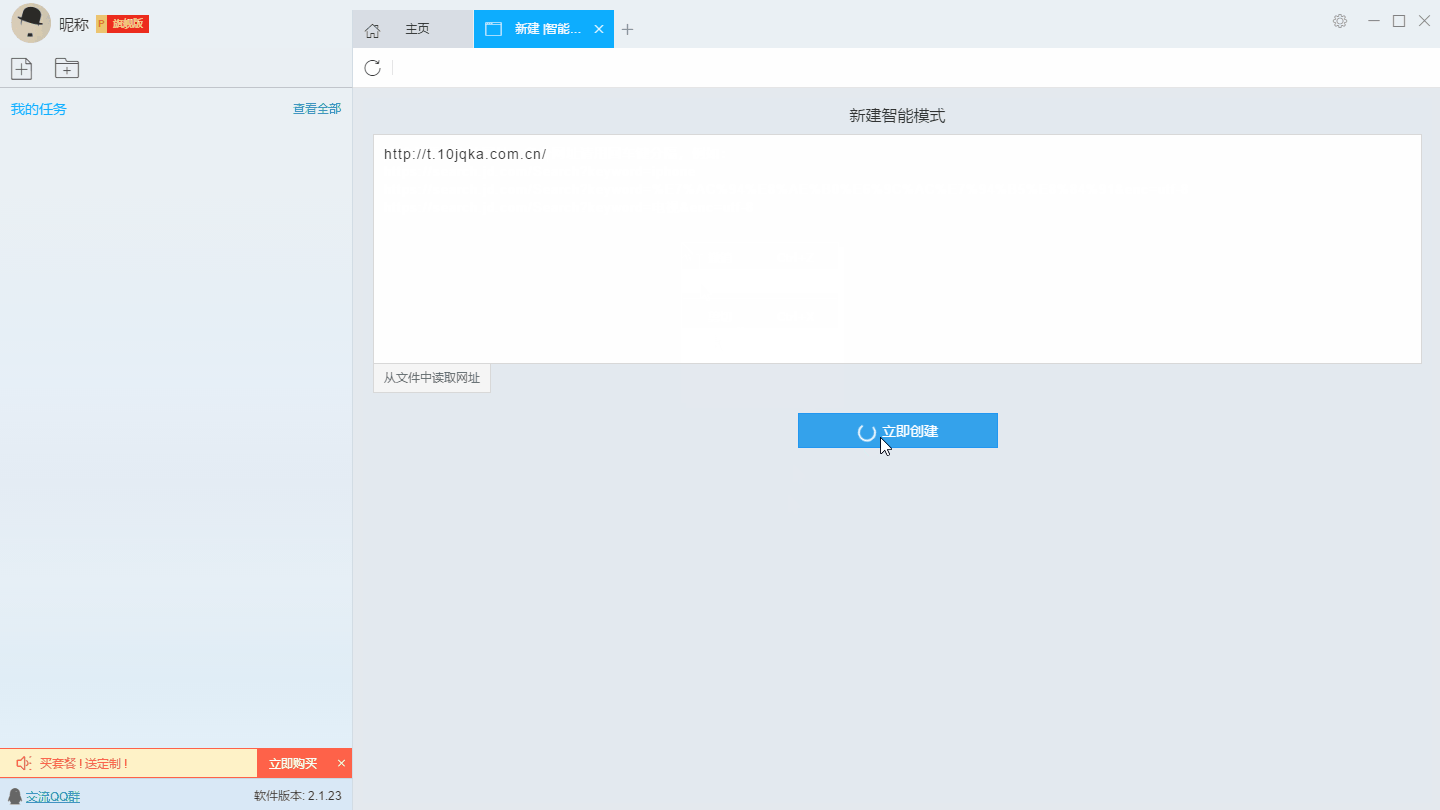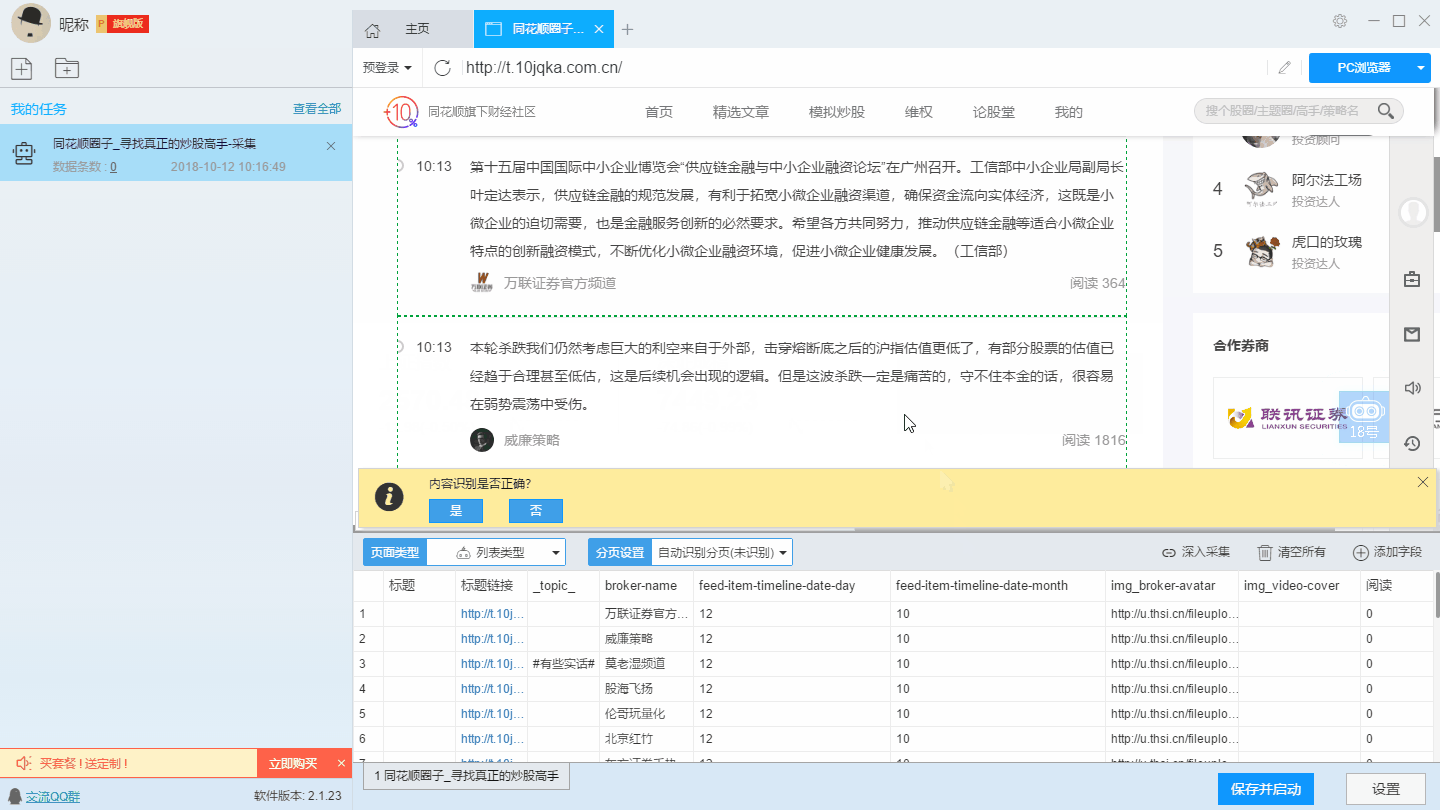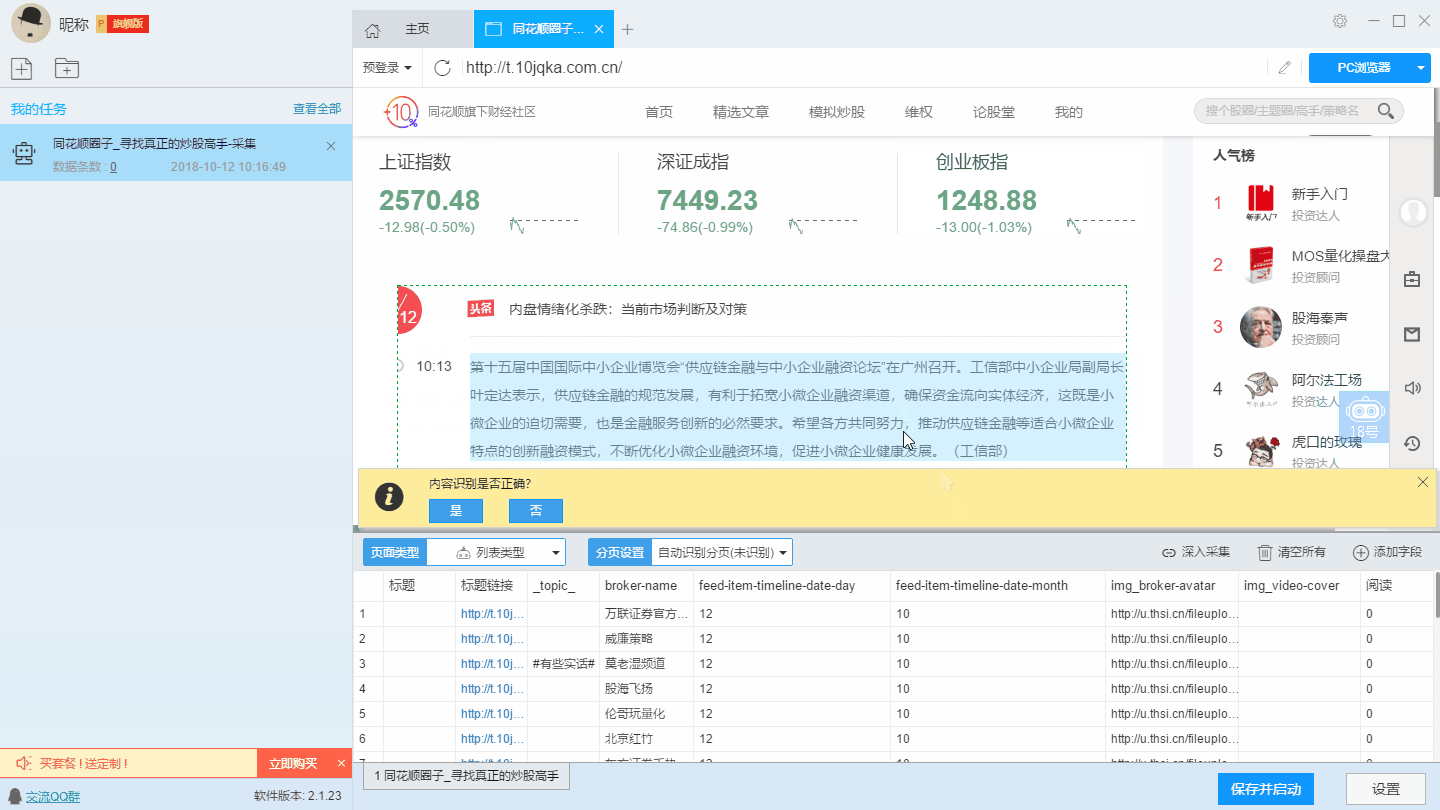
智能识别出来之后,我们可以对采集结果进行字段设置,每一类数据对应一个采集字段,我们可以右击字段进行相关设置,包括修改字段名称、增减字段、处理数据等。

由于同花顺的短评是实时加载的,页面上没有“下一页”的翻页按钮,智能模式无法直接识别出下一页,因此我们需要手动设置翻页。

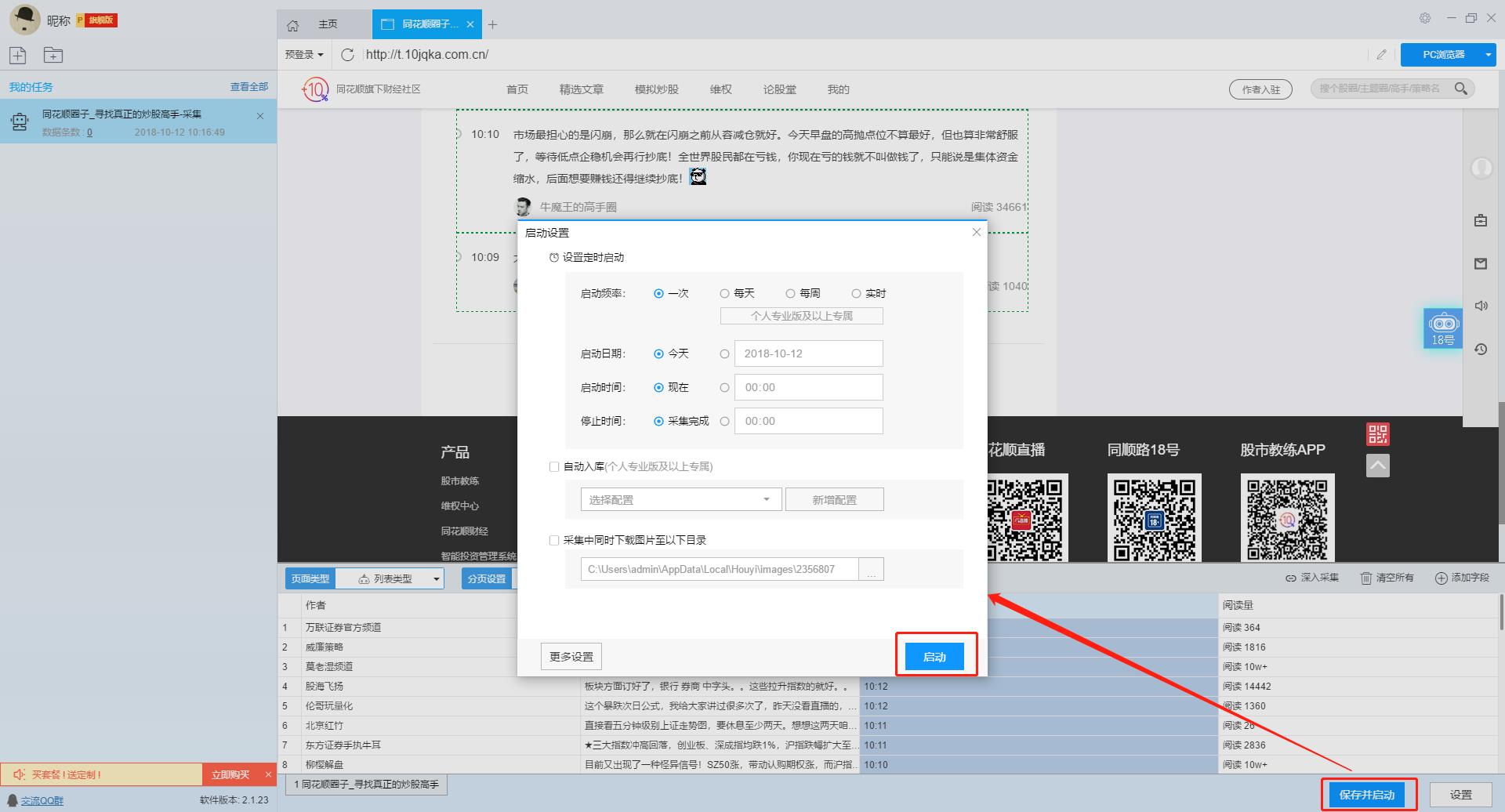
接着我们启动采集任务并开始抓取数据。
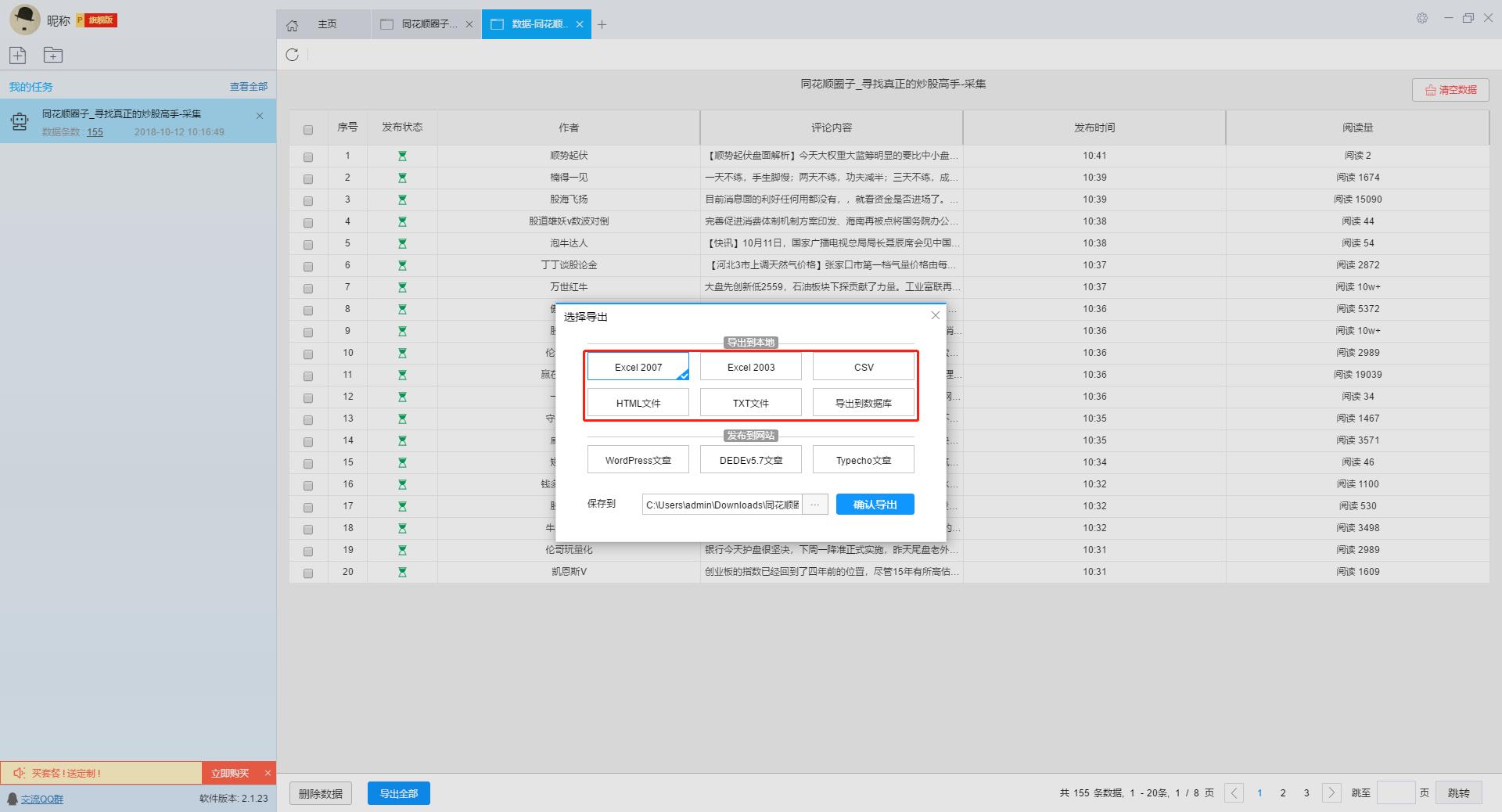
数据抓取完毕后,我们导出数据,软件支持多种导出方式,大家可以自由选择。
我们导出一个excel表格的数据,数据导出效果如下,大家可以直接使用这个数据,也可以在这个基础上对数据进行加工处理。
