在使用Flink广播变量遇到的坑
如下代码中需要特别注意:
(1)需要手动导入org.apache.flink.api.scala._
(2)需要手动导入scala.collection.JavaConverters._
【如果不手动导入该包,导致asScala使用隐式转换失败】
package testbrocast
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.configuration.Configuration
import scala.collection.JavaConverters._ //asScala需要使用隐式转换
/**
* @description: ${description}
* @author: fangchangtan
* @create: 2018-11-23 19:31
**/
object BroadCastTest {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataset1 = env.fromElements("11", "22", "33")
val dataset2 = env.fromElements("aa", "bb", "cc")
dataset1.map(new RichMapFunction[String, (String, String)] {
private var dataset2: Traversable[String] = null
override def open(parameters: Configuration) {
//import scala.collection.JavaConverters._ //asScala需要使用隐式转换,切记!!
dataset2 = getRuntimeContext.getBroadcastVariable[String]("broadCast").asScala
}
def map(t: String): (String, String) = {
var result = ""
for (broadVariable <- dataset2) {
result = result + broadVariable + " "
}
(t, result)
}
}).withBroadcastSet(dataset2, "broadCast").print()
}
}
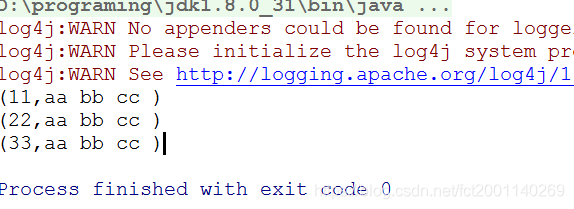
最终输出结果:
Broadcast 广播变量:可以理解为是一个公共的共享变量,我们可以把一个dataset 或者不变的缓存对象(例如map list集合对象等)数据集广播出去,然后不同的任务在节点上都能够获取到,并在每个节点上只会存在一份,而不是在每个并发线程中存在。如果不使用broadcast,则在每个节点中的每个任务中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。
因此在广播小数据量的dataset 和或者不大的不可变缓存对象的时候,特别适合使用Broadcast 广播变量