共享变量:累加器(accumlator)和广播变量(broadcast)
累加器:用来对信息进行聚合
广播变量:用来高效分发较大的对象
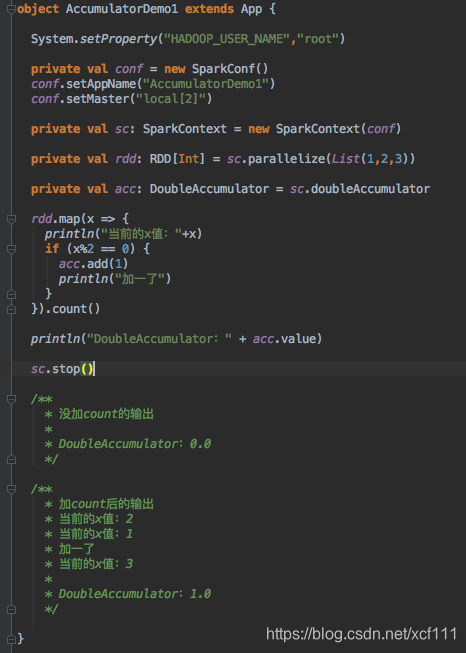
累加器(accumlator)
- 只有在运行行动操作(比如count)后才能看到正确的计数,因为行动操作前的转化操作(比如map)是惰性的,所以累加器只有在惰性的转化操作被行动操作强制出发时才会开始求值。
- 累加器的值只有在驱动程序中访问,工作节点上的任务不能访问累加器的值。
- 对于要在行动操作中使用的累加器,Spark只会把每个任务对各自累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,必须把它放在foreach()这样的行动操作中。
广播变量(broadcast)
- 通过对一个类型T的对象调用SparkContext.broadcast创建出一个Broadcast[T]对象。
任何可序列化的类型都可以这么实现 - 通过value属性访问该对象的值(JAVA中为value()方法)
- 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)
- 广播一个比较大的值时,就的选择既快又好的序列化格式是很重要的,如果序列化对象的时间很长或者传送话费的时间太久,这段时间很容易就成为性能的瓶颈。
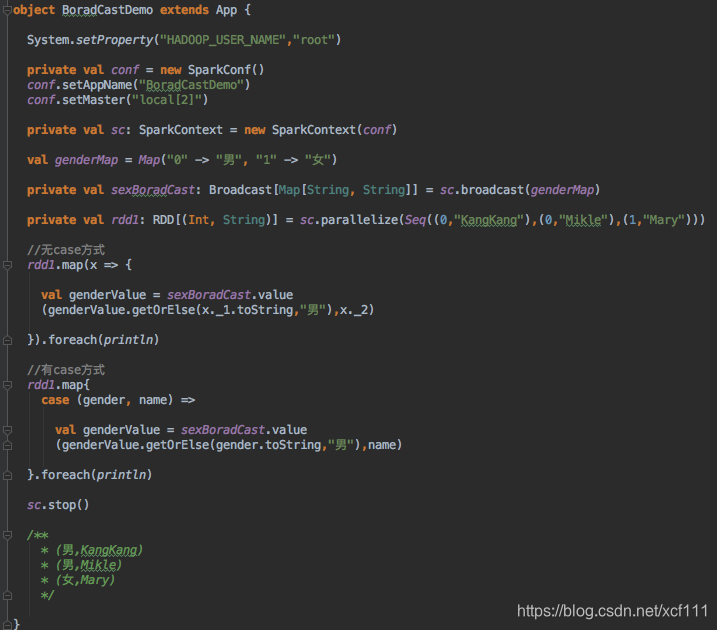
不使用广播变量的时候,genderMap会打包进每个task中去。
使用广播变量后,genderMap会发送到每个节点上的Excutor上去,该Excutor下面的task就可以共享这个变量了,一定程度上提升了性能。