导航
想写这篇博客的由衷是做完几个项目,有时对于图的画法和模型融合算法原理理解还很肤浅,特此加深一下印象。
内容概览
- 图
pandas、matplotlib、seaborn
饼图
直方图 - 融合方法
bagging
boosting
stacking
图
pandas、matplotlib、seaborn关系
matplotlib是python里面最著名的绘图系统,也即最牛逼的绘图系统,seaborn也是封装了matplotlib而成,类似于pandas封装了numpy一样,由此可以想到seaborn的易用性要比matplotlib好,语言都是越高级封装越彻底的越好用。
pandas的plot方式是一种简写方式,内部调用了plt.figure() add_subplot()等方法。
seaborn各种画图文档:http://seaborn.pydata.org/examples/index.html
饼图
饼形图只找到了pandas、matplotlib实现没有找到seaborn实现,相对其他图形饼形图还是不常用一些。
survived_value_counts = train_data['Survived'].value_counts()
# # Series.plot 画图
survived_value_counts.plot.pie(labeldistance = 1.1,autopct = '%1.2f%%',
shadow = False,startangle = 90,pctdistance = 0.6)
# matplotlib画图
labels = '0','1'
# 升序排序方便和labels对应
sizes = survived_value_counts.sort_index(ascending=True)
explode = (0,0.1) #1表示将存货的概率凸现出来
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.2f%%',shadow=False,startangle=90)
plt.show()
模型融合
集成学习通过构建并结合多个学习器来完成学习任务,如果集成学习器中只包含同类型的个体学习器,成为“同质”集成,个体可成为基学习器,反之为异质集成,个体成为组件学习器。
根据个体学习器生成方式,将集成学习方法大致分为两类:
个体学习器之间存在强依赖关系 在基于前面模型的训练结果(误差)生成新的模型,所以 必须串行的序列化方法(boosting)
不存在强依赖关系,可同时对样本随机采样,并行生成个体学习器的方法(bagging)
模型融合一般为多个弱分类器融合,多个强分类器融合有时也能达到好的效果,提高泛化能力,但经常会减慢计算速度,好坏也不一定,一般是好坏一样 结果不同的模型融合,所以常为多个弱分类器融合为强分类器
Bagging
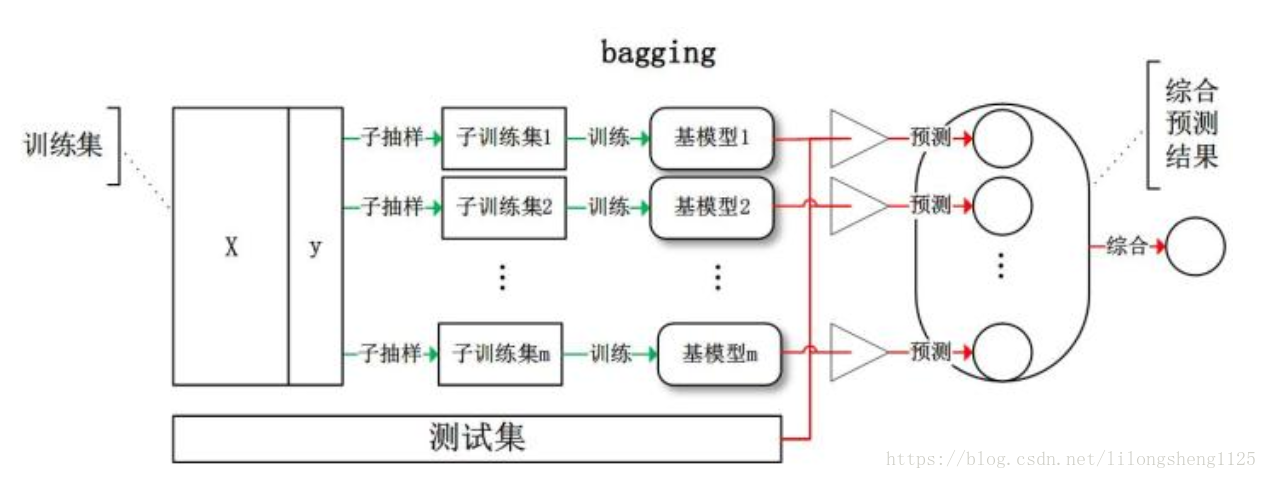
目的:对样本、对特征属性分别随机选取,产生多个独立模型,然后综合多个模型取值,旨在减少方差(variance)(投票法:绝对投票法(过半)、相对投票法、加权投票法)
为什么重采样样本?
如果想要得到泛华能力强的集成,个体学习器应该尽可能的相互独立,对训练集重采用可以得到不同的训练集,是从原始数据集(放回重复采样)选择S次后得到S个新数据集,将某个学习算法分别作用于每个数据集就得到了S个分类器,在对新数据分类时,选择这S个分类器投票结果最多的类别当做最后类别,每次重新采样避免了数据不均的影响因此可以降低整体的方差。
训练过程如下图,数据集为D(x|y) , 进行m次随机子抽样得到m个大小为n’的数据子集,分别在上面训练成m个基学习器,再根据投票、加权等方式得出最终结果。
熟悉了训练流程看下训练代码,下面是随机森林训练模型,传入训练集数据和标签,返回网格搜索对象。
# 基于bagging的随机森林融合
def RFClassifier(titanic_train_data_X,titanic_train_data_Y):
print(titanic_train_data_X.shape)
# randomforest random_state随机器对象 一般不变
rf_est = RandomForestClassifier(random_state=0)
# 网格搜索调优参数
rf_param_grid = {'n_estimators':[50,100,200],'min_samples_split':[5,6,7],'max_depth':[10,15,20]}
rf_grid = model_selection.GridSearchCV(rf_est,rf_param_grid,n_jobs=25,cv=10,verbose=1)
rf_grid.fit(titanic_train_data_X,titanic_train_data_Y)
print('Best RF Params:' + str(rf_grid.best_params_))
print('Best RF Score:' + str(rf_grid.best_score_))
print('RF Train Score:' + str(rf_grid.score(titanic_train_data_X,titanic_train_data_Y)))
return rf_grid
# 随机森林融合
rf_grid = RFClassifier(titanic_train_data_X,titanic_train_data_Y)
y_rf_test_pred = rf_grid.predict_proba(titanic_test_data_X)
print(y_rf_test_pred)
random forest(RF)决策树+bagging随机森林是bagging的一个扩展,RF在以决策树为基学习器构建bagging集成基础上,引入随机的属性选择,即对于基决策树进行划分时,随机从节点属性集中选取一个包含k个属性的子集,再从子集中选择最优属性划分,k控制了随机程度。
Boosting
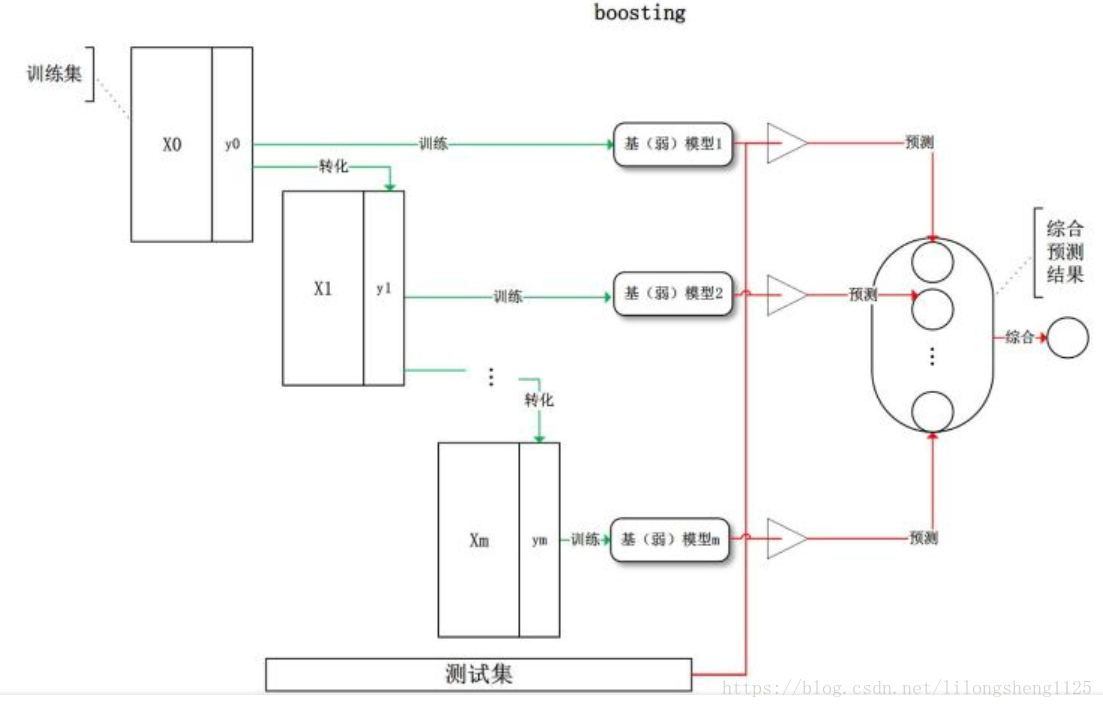
原理:个体学习器存在强依赖关系,在基于前面模型的训练结果(误差)生成新的模型,拟合前一个模型的误差,旨在减少偏差(bias)。
训练过程 ,X0是原始数据集得来,第一个弱分类器训练该训练集 结果出来后,对分错的样本进行统计错误率或偏差,统计出来后提升这些样本的权重值,得到X1训练集,第二个弱分类器拿X1训练集来训练,如此类推直到第m个分类器,最后再综合各个分类器结果出来最终预测结果,如下图:
模型预测代码如下:
# 基于boosting的随机森林融合
def AdaBClassifier(titanic_train_data_X,titanic_train_data_Y):
print(titanic_train_data_X.shape)
# #AdaBoost
ada_est = AdaBoostClassifier()
ada_param_grid = {'n_estimators':[500],'learning_rate':[0.01,0.1]}
ada_grid = model_selection.GridSearchCV(ada_est,ada_param_grid,n_jobs=25,cv=10,verbose=1)
ada_grid.fit(titanic_train_data_X,titanic_train_data_Y)
print('Best Ada Params:' + str(ada_grid.best_params_))
print('Best Ada Score:' + str(ada_grid.best_score_))
print('Ada Train Score:' + str(ada_grid.score(titanic_train_data_X,titanic_train_data_Y)))
return ada_grid
# 基于boosting的GradientBoosting
def GBClassifier(titanic_train_data_X,titanic_train_data_Y):
print(titanic_train_data_X.shape)
# GradientBoosting
gb_est = GradientBoostingClassifier(random_state=0)
gb_param_grid = {'n_estimators':[500],'learning_rate':[0.01,0.1],'max_depth':[20]}
gb_grid = model_selection.GridSearchCV(gb_est,gb_param_grid,n_jobs=25,cv=10,verbose=1)
gb_grid.fit(titanic_train_data_X,titanic_train_data_Y)
print('Best GB Params:' + str(gb_grid.best_params_))
print('Best GB Score:' + str(gb_grid.best_score_))
print('GB Train Score:' + str(gb_grid.score(titanic_train_data_X,titanic_train_data_Y)))
return gb_grid
# Adaboost融合
ada_grid = AdaBClassifier(titanic_train_data_X,titanic_train_data_Y)
y_ada_test_pred = ada_grid.predict_proba(titanic_test_data_X)
print(y_ada_test_pred)
# GBClassifier融合
gb_grid = GBClassifier(titanic_train_data_X,titanic_train_data_Y)
y_gb_test_pred = gb_grid.predict_proba(titanic_test_data_X)
print(y_gb_test_pred)
后面我们将重点分析adaboost、xgboost等原理。
Stacking
Stacking也是数据结构的一种,称为栈,它是一种有先后顺序的结构,在这里同样有先后顺序,数融合模型时表示一种分层模型集成框架。两层模型应用最多,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,也就是有几个基模型就会有几个特征列作为第二层的输入特征,训练过程如下图:

随笔思考
如何实现拼写纠错呢
当我们在浏览器中输入一个汉字或者单词后,如果输错了之后就会弹出来最相近正确的单词,这一过程如何实现呢。
首先我们有一个大的词典作为我们的语料库,语料库如何保存下来是一部分,保存在DB或者存为字典,单词去语料库中查找可以确定是输入错了还是对了,确定对错后既然就需要查找和这个输入单词最相近的单词,这一过程可以利用编辑距离来度量,
有几个问题需要思考一下:
如何度量各个单词上下文之间的关系?
编辑距离如何通过动态规划来求解?