前面几篇逻辑回归的例子有些是人造出来的,有些是比较正规的,但数据都比较完整,没有缺失的属性。虽然我们在很多数据上取到的非常好的效果,但总感觉好像不够味,不像实战。
所有的数据下载地址:https://gitee.com/tianyalei/machine_learning,按对应章节查找。
那么这里有个地方给带给你想要的实战——Kaggle数据分析建模的应用竞赛平台,企业或者研究者可以将问题背景、数据、期望指标等发布到Kaggle上,以竞赛的形式向大家征集解决方案。我们就可以下载分析数据,使用统计/机器学习/数据挖掘等知识,建立算法模型,得出结果并提交,排名top的可能会有奖金哦!
那么这里更多就是我们想要的实战了。
这里就拿里面最知名、参与者最多的泰坦尼克号问题来做示例。
泰坦尼克号是历史中著名的海难事件,大量游客在事故中丧生,也有部分游客获救。这个问题就是他提供了一批乘客的信息如姓名、年龄、性别、票价等等一些信息,和是否获救,然后让你建模分析,再去预测另一批乘客的获救与否。匹配率高的排名就靠前。数据可以在上面网页的data里找到。我提供的也有,分为train.csv和test.csv。
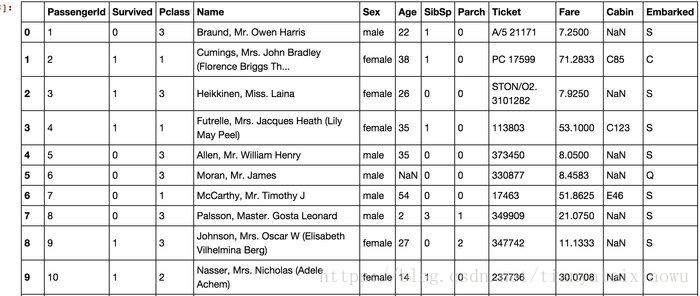
我们看到,总共有12列,其中Survived字段表示的是该乘客是否获救,其余都是乘客的个人信息,包括:
- PassengerId => 乘客ID
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
粗略观察一下数据,发现age里有不少缺失,Cabin(舱号)大量缺失,其他属性个别缺失。
OK,要进入正题了,当我们拿到这样一份很符合实际、但对机器建模很不友好的数据时,该怎么下手。
1 认识数据
首先,也是很重要的一点,对数据本身的涵义认知是非常重要的,一定要基于数据本身的特性进行初步分析。
根据常理,和Jack、Rose给我们上演过的电影,我们初步知道,早期是妇女儿童优先、最早的营救过程应该是比较有序的,妇女儿童会在一开始得到不小的救援力度。然后一些头等舱高等舱的人获救的也会多一些,毕竟身份地位金钱还是有它的价值的。轮船自身的工作人员获救概率比较低,年纪比较大的人获救率也低一些,本身他们的生存能力也比不上年轻人。低等舱的非儿童人员应该概率也低。
我们将数据先导入到weka里看看基本统计。注意先把name中的逗号和单引号 双引号全干掉,不然导入不进来。导入后,主要是看看数据的基本情况,验证一下之前的猜测。由于导入的数据属性默认的格式不对,我们用filter转换成对应的格式,如Survived是Norminal。简单处理后,来观察数据分布:
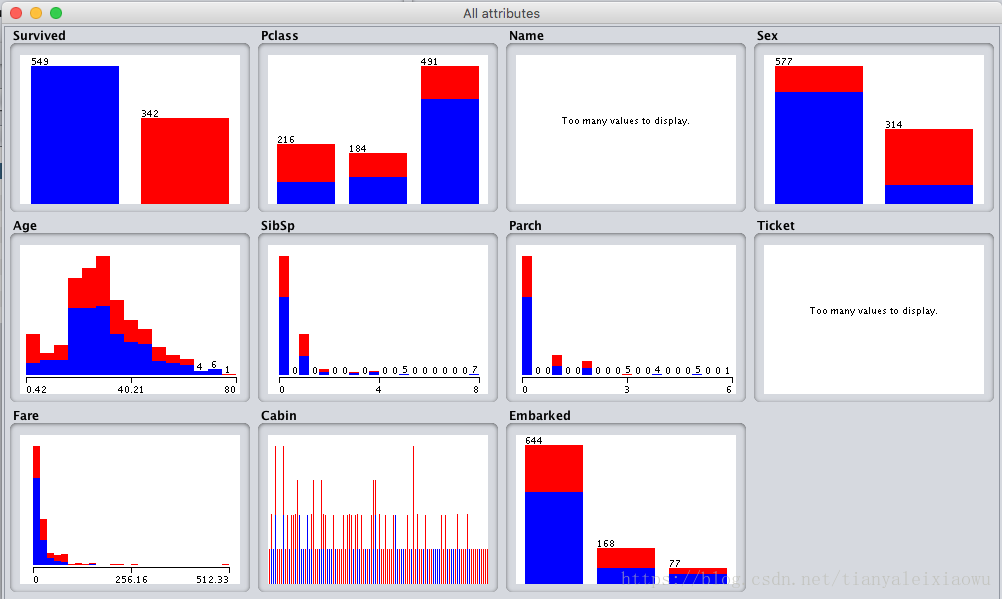
红的是获救的,蓝色未获救。1等舱获奖率大半,2等不到1半,3等大概20%。女性获奖率很高,男性很低。年龄特别小的概率很高,其他的比较差。SliSp在1-2时生还概率高,其他稍差。Parch在1,2,3时概率高。fare票价基本也是越高的生还率越高。Embarked港口中间的概率最高,其他稍差。
可以看到,高等舱、女性或者年龄特别小的小孩生存概率很高。其他的就得看情况了。
总共342个获救,其他未获救。
2 修补数据
由于age缺少了一部分,还有一些别的列也有部分缺少,所以我们先对他们填充一下。
age的填充原则是这样的,我们从乘客名字中,看Mr、Miss、Master、Mrs、Dr,我们分别统计这些称号的平均年龄,然后将包含这些称号的缺失值填充为平均值。
其他有缺失的值也用这种方法。
Cabin船舱号这个缺失太多,按理说已经不能做为特征了。但这个想想也应该非常重要,毕竟船舱的位置对生还影响还是挺大的。譬如如果是底层锅炉区,基本就全部歇菜了。我们初步看了看,大概有ABCDE等开头的,这些应该都是乘客,缺失的应该有一些是工作人员,譬如烧锅炉的。我们可以考虑使用2种方式,一是将有Cabin的置为1,缺失的为0,而是细分为ABCDE等和缺失,极端情况下,可以删掉该列。
3 转换数据
我们把PassengerId字段干掉,这个肯定没用。把Name也干掉,我们已经通过它算出来了年龄了,它存在的价值就没了。
当然,这是基于正常的通用思维,因为名字对获救率实在是没关系,但是这里比较特殊,属于特定案例。据统计,这批数据中,名字长的比短的获救率要高,而且呈线性关系,这个……
4 尝试不同算法
完成上面的处理后,我们完成了初步的数据清洗,得到文件train1.arff,然后开始进行训练。
毫无疑问,我们先选择逻辑回归作为baseline,因为我们已经知道某些属性和结果是有线性关系的。
进行10次Cross验证
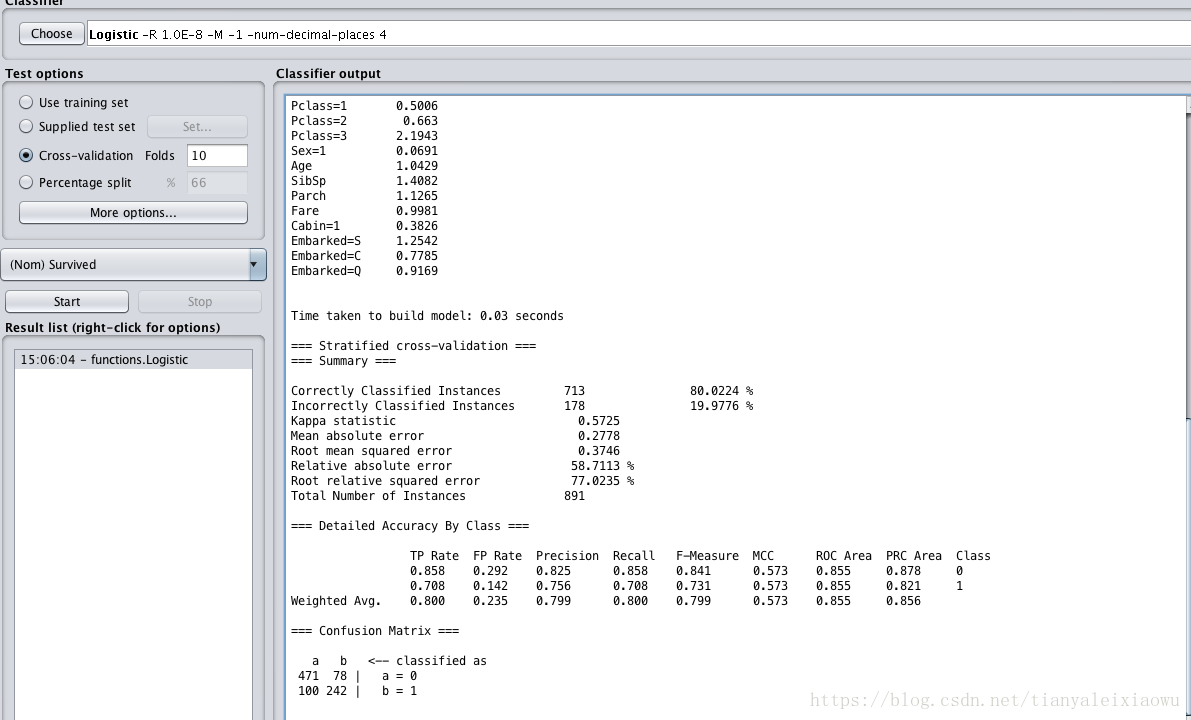
可以看到在训练集上匹配率在80%,在未获救上表现的比较好有85%,在已获救上只有70%的正确率。
OK,我们用同样的数据清洗,把测试集也处理一下,看看最基本的逻辑回归在测试集的表现。

官方下载的test.csv里是没有Survived信息的,我为了方便用weka来导入,给survival也填了值,但是没有价值,所有这个test集的结果没有意义。
我们导出训练结果,按照kaggle要求的格式导入,并查看自己的结果排名。
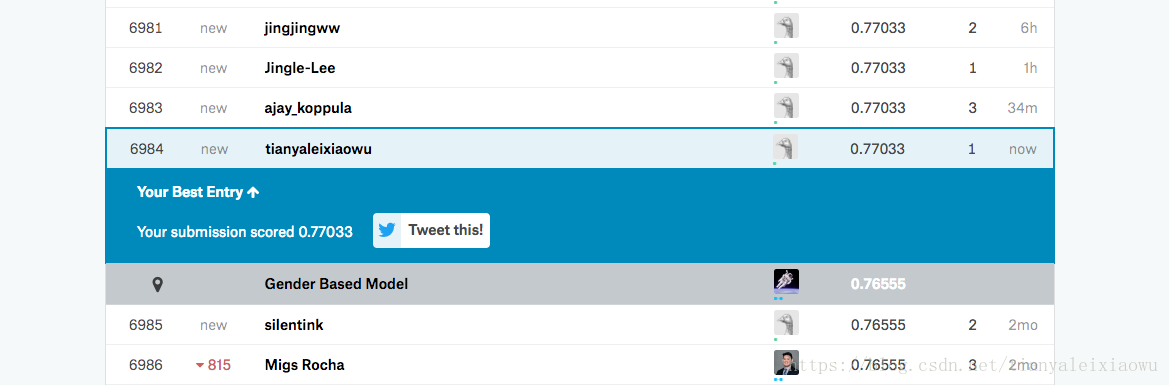
https://www.kaggle.com/c/titanic/leaderboard。可以看到排名在6984,成功率0.77。
这个结果就是我们的baseline了,最低要求。
然后我们开始进行优化。
我们在前面的只是简单的对缺失值进行了补全,并没有进行融合。由于这里面的各个属性我们都知道他们的含义,所以主要的工作应该在于特征的放大、组合。
至于该怎么个组合法,网上有太多的案例,你会惊奇于各路大神的脑洞。当然,特征工程才是机器学习的核心,很多时候花在特征工程的工作量占比超过80%,而后的算法选择、调参倒相对轻松一些。合适的特征才能真正暴露出数据的特性,不然再好的算法也无能无力。
我大概列几个对属性的处理:
1 我们假设一二三等舱各自内部的票价也与逃生方式相关,从而分出高价一等舱、低价一等舱……这样的分类。
2 Parch and SibSp这两组数据都能显著影响到Survived,但是影响方式不完全相同,所以将这两项合并成FamilySize组的同时保留这两项。
3 将Ticket中的字母与数字分开,分为Ticket_Letter和Ticket_Number两项。
…………
还有各种组合形式可以尝试,构建新的属性,来提高预测的准确率。也可以尝试一下别的算法,如线性回归结合决策树,随机森林等。很多时候做模型融合也能提高准确率。
根据总结的经验,泰坦尼克号这个数据,最高可以模拟到81-83左右的正确率。再高的就是过拟合了,已经不是通用的模型处理了。至于kaggle上那些100%的,90%以上的,不具备太大的参考性。毕竟这个名单最终的幸存情况是有公布的,对着名单做个100%当然可以。
参考:
https://blog.csdn.net/Koala_Tree/article/details/78725881
https://zhuanlan.zhihu.com/p/30538352