前言
先来一张美景图,欣赏一下大自然,顺便大家猜猜这是哪里?
有时候真感叹大自然的雄伟壮阔,自然形成了无数的山和风景不需要任何点缀,有时候在想为什么亲近自然界我们会有亲近的感觉,可能那是我们的来源,我们人类在经过了无数代的繁衍生息,发展到了现在的文明,这些都是前辈们智慧的结晶,就比如我们每天看的电视、电脑,它们把彩色的世界呈现在我们眼前,提高了我们的生活品味和视觉享受,那么你是否想过它是怎么形成的吗?下面就让我们来说说它的原理。

三原色原理
百度百科
人眼对(Red Green Blue)红、绿、蓝最为敏感,人的眼睛像一个三色接收器的体系,大多数的颜色可以通过红、绿、蓝三色按照不同的比例合成产生。同样,绝大多数单色光也可以分解成红、绿、蓝三种色光,这是色度学的最基本的原理,也称三原色原理。
说道这里难免会有些好奇、有些疑问了,为什么是三原色?为什么不是四原色、五元色呢?
通过搜集相关资料又发现了牛顿这个耳熟能详的人物,惊讶于这又和他有关系,他这一生为人类得做了多少贡献,牛顿通过三菱镜首先发明了自然光可以分解为不同颜色的七彩色光,伟人的思想往往是与众不同的,他们往往不会止步不前,继续思考 他在想既然自然光可以分解,那么七彩色光是不是也可以被分解或者合成呢?
顺着这个思路他又经过了无数个昼夜不停的实验和计算,(至于怎么实验的感兴趣的可以自己搜索)终于真理又让他发明了,在七彩色光中只有红、绿、蓝三种颜色不能够再继续分解,不能分解也就是原子的 这点和事务的特性一样,所以称其为三原色,其它的光可以通过这三种光来组合叠加和相减算出来。
三原色我们达成的共识是这样的:
(1)自然界的任何光色都可以由3种光色按不同的比例混合而成。
(2)三原色之间是相互独立的,任何一种光色都不能由其余的两种光色来组成。
(3)混合色的饱和度由3种光色的比例来决定。混合色的亮度为3种光色的亮度之和。
三原色在应用于实际生活中时既可以相加,也可以相减,采用相加的方式成为RGB颜色模型和CMY模式(品红、青色、淡黄),也是用的最多的一种,相减为CMYK模型,他们分别用于绘图和印刷领域。
三原色之所以可以代表最基础的色彩,还有另外一个原理即正交,任何事物如果想研究他们 让他们正交是最好的组织方式,因为他们互不影响,如通笛卡尔坐标系一样,在坐标系中可以表示任何点一样,三原色犹如三个坐标系,由三个颜色坐标系可以表示出来很多种颜色,即三原色代表了世界这么多颜色,反过来也可以看做是这么多色彩的抽象,从而又论证了科学、科研是一个不段抽象、不断总结升华的过程,所以 学会总结 抽象非常重要。
软件或屏幕显示图片的时候是利用电子光照射屏幕上的发光材料产生的色彩,多个色彩相加,而印刷是墨的反光相减,可以说三原色的应用大大提高了我们认识世界和观察世界的途径,而不是活在非黑即白的世界里面。
通过三原色可以组合出来自然界的各种各样的色彩,每种颜色值可以通过数值来表示大小强弱等,以目前计算机中8位来保存颜色值,每种颜色值的范围是0-255个值来表示,根据组合原理三种色组合起来有255255255种色彩,对于我们肉眼的分辨能力已经够用了。
显示器为什么有颜色?
理解了三原色再来看这个问题会比较简单,在电子屏幕上有可以发光的三种材料荧光材料,在经过电子枪照射时会组合成不同颜色,电子枪的强弱即可以表示三种原色的色值大小,组合出来的颜色也就各不相同,有些特别相似的颜色也不是我们肉眼就能看出来的,即满足了在我们视力范围内的色彩。
图像识别-计算
一张图片在屏幕上面如果无限缩小会看到是由无数个点组成的,其实任何事物都是由无限到有限来组成,无数个点会组成一个平面,当点和点之间的间距足够小时我们的肉眼是分不出来的,我们看到的就是一个图像,当无限个图像从我们眼前闪过就会形成视频电影,他们都是一个道理,好比几何中的点组成线、线组成面、面组成立体空间,当分析到这一层次图像识别就显着处理简单了,只要让计算机计算组成图片的无数个点的特征就可以识别出来相似图片,当然这也依赖于强大的运算能力,因为像素高的大图是非常大的,如常见笔记本电脑像素,有1366*768个像素点,数量级别在百万级,况且以RGB模式来说有三个通道颜色 将会更大。
PC如何存储图片?
图片在计算机中是一个三维矩阵,让我们通过一个图片直观感受一下,如下图是训练集中第一个类型里面第一张图片
我们取该图中第一个通道矩阵,并打印出来如下:
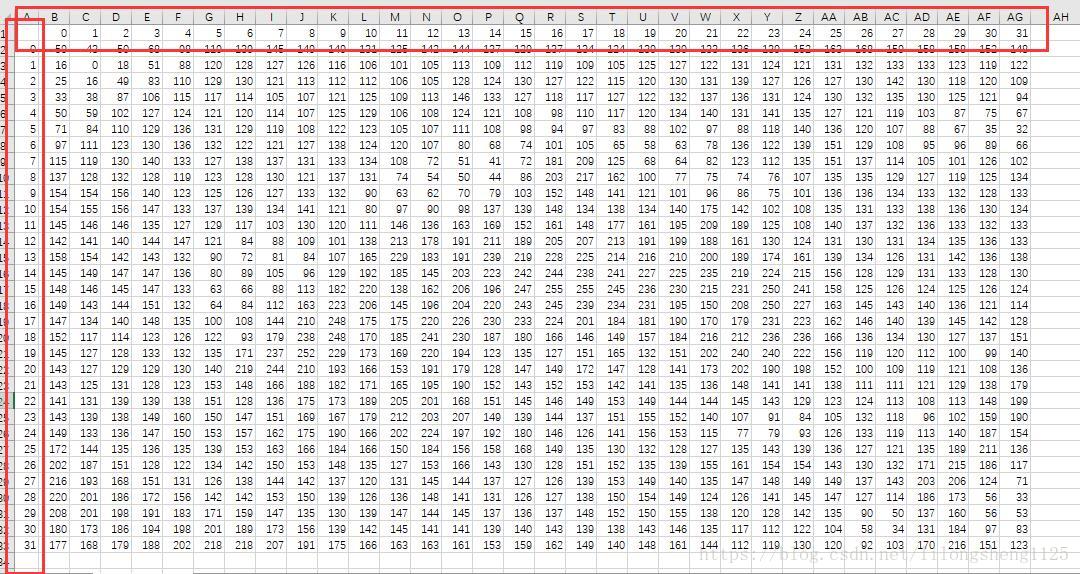
# 打印red 通道图片矩阵
img_df = pd.DataFrame(X_train[0][:,:,0])
img_df.to_csv('X_train0101.csv')
plt.imshow(X_train[0])
plt.show()
从图片可以看到每个像素点的值都在0-255之间,三个这样的颜色矩阵就可以组装出来一个彩色图片,矩阵越大像素点越多,会越清晰当然占用内存也就越大,在实际预测时有时会对矩阵进行变化,变为一个长的向量,方便计算距离,下面我们将这名变化来就是那距离。
knn图片识别
如下先上代码,思路是将三维的图片矩阵 转化为一个长的n*1的向量,然后计算测试集每个图片到训集每个图片的欧式距离,也就是两个向量的距离,区最近的来作为判别分类标准。
import os
import sys
import numpy as np
import cPickle as pickle
from scipy.misc import imsave
import matplotlib.pyplot as plt
# 加载cifar-10图片文件
def load_CIFAR_batch(filename):
with open(filename, 'rb') as f:
datadict=pickle.load(f)
# 查看字典变量的key值情况
print datadict.keys()
X=datadict['data']
Y=datadict['labels']
# 默认颜色通道为 3 32 32 形式,需要变为32 32 3的形式
X=X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float")
Y=np.array(Y)
return X, Y
# 多个文件时组装加载的数据
def load_CIFAR10(ROOT):
xs=[]
ys=[]
for b in range(1,6):
f=os.path.join(ROOT, "data_batch_%d" % (b, ))
X, Y=load_CIFAR_batch(f)
xs.append(X)
ys.append(Y)
X_train=np.concatenate(xs)
Y_train=np.concatenate(ys)
del X, Y
X_test, Y_test=load_CIFAR_batch(os.path.join(ROOT, "test_batch"))
return X_train, Y_train, X_test, Y_test
# 载入训练和测试数据集
X_train, Y_train, X_test, Y_test = load_CIFAR10('cifar-10-batches-py/')
# 把32*32*3的多维数组展平
Xtr_rows = X_train.reshape(X_train.shape[0], 32 * 32 * 3) # Xtr_rows : 50000 x 3072
Xtr_rows2000 = Xtr_rows[0:5000,:]
Y_train2000 = Y_train[0:5000]
# print type(Xtr_rows)
# print Y_train[0:2000]
Xte_rows = X_test.reshape(X_test.shape[0], 32 * 32 * 3) # Xte_rows : 10000 x 3072
Xte_rows2000 = Xte_rows[0:5000,:]
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
"""
这个地方的训练其实就是把所有的已有图片读取进来 -_-||
"""
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
"""
所谓的预测过程其实就是扫描所有训练集中的图片,计算距离,取最小的距离对应图片的类目
"""
num_test = X.shape[0]
# 要保证维度一致哦
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# 把训练集扫一遍 -_-||
for i in xrange(num_test):
# 计算l1距离,并找到最近的图片
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # 取最近图片的下标
Ypred[i] = self.ytr[min_index] # 记录下label
return Ypred
nn = NearestNeighbor() # 初始化一个最近邻对象
nn.train(Xtr_rows2000, Y_train2000) # 训练...其实就是读取训练集
print "开始训练"
Yte_predict = nn.predict(Xte_rows2000) # 预测
print Yte_predict
print "结束训练"
# 比对标准答案,计算准确率
print 'accuracy: %f' % ( np.mean(Yte_predict == Y_test) )
发现这个训练很耗时间,一时半会出不来结果参考网上结果为30%+,可见效果并不是特别好。
总结
这只是一个图像识别的思路,除此之外还有很多高校的识别方法,以后会探索更搞笑的算法,对于图像识别越快速、准确率、召回率越高,越是我们希望看到的。
题外思考
创造平等的机会 与 平等的结果 谁更好?
我们先举一个简单的例子,比如很厉害的清华大学要像全社会招生,由于社会各个地区教育资源、师资力量不平等造成了他们最终考试的水平也不平等,好的地方很可能分数比较高,造成大学招进来的人都是资源好的地方的学生,教育本来就欠缺的地方永远也没有进去好大学的资格,如何改变这种状况呢?
可以提高基础教育条件对于条件不好的地方加大投资力度,帮助教育落后的地方改改教育状况,即创造平等的参与机会,另一种做法是大学按地区名额来招生,每年给教育落后地区也分配一定名额,那么他们也可以进度好大学,如此也可能带来大学整体水平下降,各有利弊,我是觉得创造平等机会其实是更好的,有助于提高升大学的综合水平,为社会培养出来更多的精英。
法国高等教育分为了两类,一类是共同大学 另一类是精英大学,共同大学注重公平性属于普及综合教育、基础教育一类,精英大学是培养高端人才的,每年招收不如3%,历史上法国大部分科学家、高管都出自它的精英大学,比如巴黎综合工科学院 ,我们熟悉的泊松既出自这个学校,泊松的二项式定理,逻辑回归方程推导时即假设了样本是服从泊松分布的,大家也可以思考思考哪个更重要!