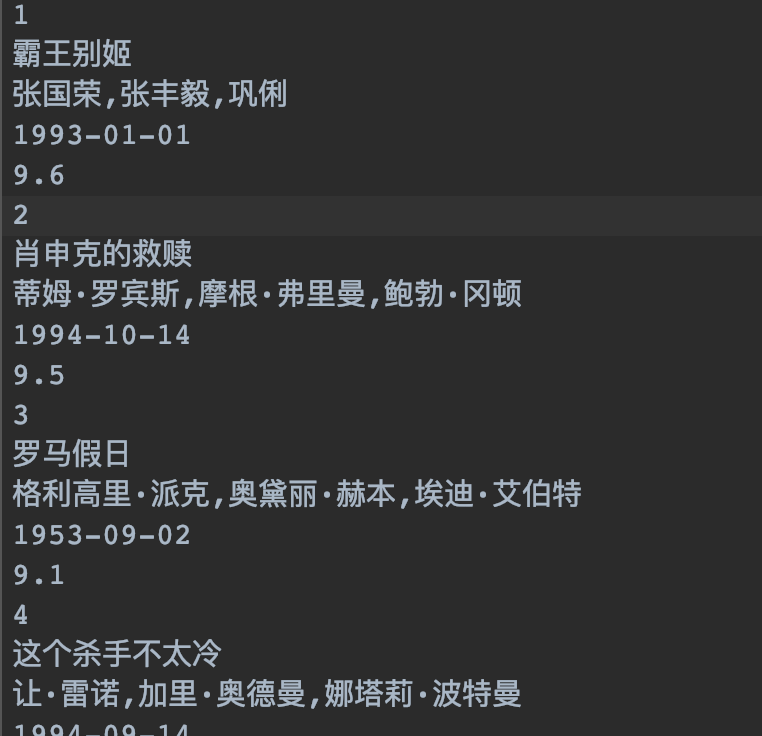
TXT
from pyquery import PyQuery import re import json import requests def get_html(url): headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'} try: r = requests.get(url, headers=headers) r.raise_for_status() return r.text except: print('status_code is not 200') return None def parse_time(str): txt = re.search('\d{4}(-\d{2}-\d{2})*', str) return txt.group() def parse_html(html, f): doc = PyQuery(html) dd_nodes = doc('dl.board-wrapper') ranks = dd_nodes('.board-index').items() names = dd_nodes('.name').items() actors = dd_nodes('.star').items() times = dd_nodes('.releasetime').items() integers = dd_nodes('.integer').items() fractions = dd_nodes('.fraction').items() for rank, name, actor, ts, integer, fraction in zip(ranks, names, actors, times, integers, fractions): str = '\n'.join([rank.text(), name.text(), actor.text().replace('主演:', ''), parse_time(ts.text()), integer.text() + fraction.text()]) if __name__ == '__main__': url = 'http://maoyan.com/board/4' with open('movie.txt', 'w') as f: for i in range(10): path = url + '?offset=' + str(i*10) print(path) html = get_html(path) if html: parse_html(html, f)
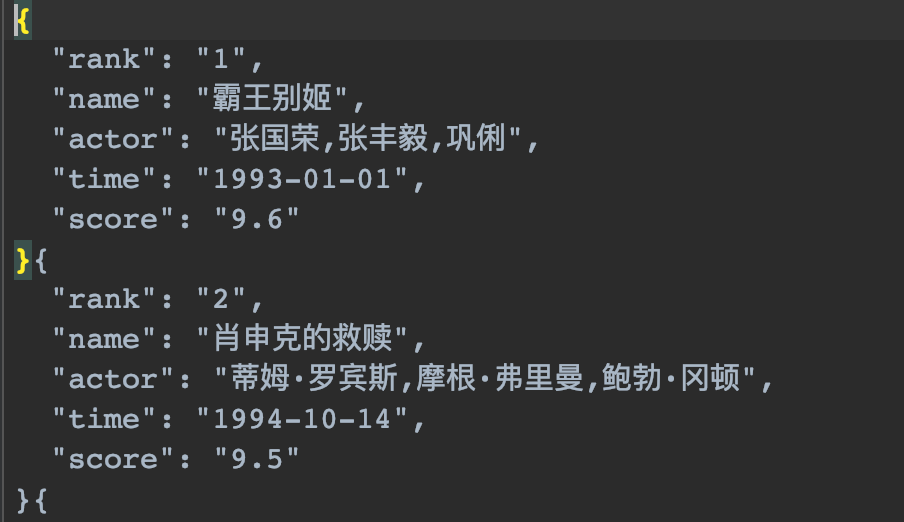
JSON
json.loads(str)把字符串转为JSON对象
json.dumps(JSON, indent=2, ensure_ascii=False)把JSON对象转换为字符串
indent=2设置格式,2代表缩进字符数
ensure_ascii=False解决乱码
from pyquery import PyQuery import re import json import requests def get_html(url): headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'} try: r = requests.get(url, headers=headers) r.raise_for_status() return r.text except: print('status_code is not 200') return None def parse_time(str): txt = re.search('\d{4}(-\d{2}-\d{2})*', str) return txt.group() def parse_html(html, f): doc = PyQuery(html) dd_nodes = doc('dl.board-wrapper') ranks = dd_nodes('.board-index').items() names = dd_nodes('.name').items() actors = dd_nodes('.star').items() times = dd_nodes('.releasetime').items() integers = dd_nodes('.integer').items() fractions = dd_nodes('.fraction').items() for rank, name, actor, ts, integer, fraction in zip(ranks, names, actors, times, integers, fractions): data = { 'rank': rank.text(), 'name': name.text(), 'actor': actor.text().replace('主演:', ''), 'time': parse_time(ts.text()), 'score': integer.text() + fraction.text() } f.write(json.dumps(data, indent=2, ensure_ascii=False)) if __name__ == '__main__': url = 'http://maoyan.com/board/4' with open('movie_json.txt', 'w') as f: for i in range(10): path = url + '?offset=' + str(i*10) print(path) html = get_html(path) if html: parse_html(html, f)