前言
本文为《Neural Network and Deep Learning》学习笔记(三),可以转载但请标明原文地址。
本人刚刚入门、笔记简陋不足、多有谬误,而原书精妙易懂、不长篇幅常有柳暗花明之处,故推荐阅读原书。
《Neural Network and Deep Learning》下载地址(中文版):Neural Network and Deep Learning(中文版)
注:这本书网上有很多免费版,随便搜一下就有了,不用非得花积分下载我上传的资料。
第三部分:实践篇(识别手写数字代码)
一、代码下载、环境准备、运行!
1、代码下载
本文所需代码及数据集下载地址:百度云地址 (另附原书中所有代码及数据下载地址:百度云地址)
本文所需下载资料文件名为NeuralNetworks,内容如下所示:

其中,mnist.pkl.gz为数据集文件(也就是50000张手写图片的训练集);
mnist_loader.py实现从数据集中加载并预处理数据(将图片重设大小之类的操作);
network.py实现了我们在准备篇中定义的神经网络及学习算法,并负责输出学习过程;
run.py先进行数据加载,再创建一个神经网络并向其传递参数,使这个神经网络开始学习。
2、环境准备
本人使用的是Anaconda3,IDE为自带的Spyder,所需python版本为2.7
首先我们需要新建一个环境,【打开Anaconda Navigator】—【选择左侧Environments】—【选择中间底部的Create】
环境名字Name随便起一个,假设我起的名字是py27(图中起名叫NN只是为了做演示),python版本选择2.7,然后点击Create。

之后我们需要下载所需包,在中间一列点击刚刚创建好的环境,在右侧选择Not Installed,分别搜索spyder和numpy点击下载,所需时间可能稍长,请耐心等待。


之后我们就可以拥有一个python版本为2.7的Spyder了,它的快捷方式应该是这样的,白框内的是我的环境名字py27:

3、运行!
双击打开这个Spyder,点击Projects——New Project——Existing directory,在Location中选择你下载的NeuralNetworks文件位置,点击选择文件夹——返回点击Create。

然后左侧会出现下载好的文件夹中的各文件:

双击mnist_loader.py文件,找到第44行,将选中部分改成自己的文件夹下载后放置的路径,然后点击左上角保存。

双击run.py文件,点击左上角运行。

然后,就可以静静等待右下角输出结果了。
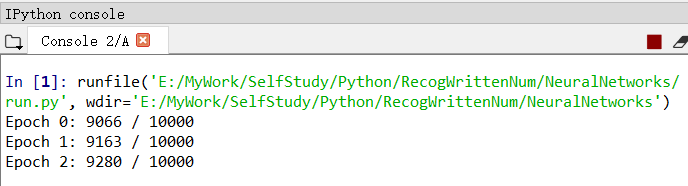
输出结果格式为:迭代期 0-29:正确测例个数/总测例个数。
上图可见,准确率达到了百分之九十以上,而且随着迭代期的增长而不断增加,当迭代期达到第30个时,准确率达到了百分之九十五以上。

运行成功之后,我们来看看代码吧。
二、代码解释:network.py
对于mnist_loader.py,因为不涉及到神经网络的架构,且逻辑简单,只是处理数据的过程,所以不做解释(其实是懒吧喂!)
对于run.py,也很简单,不做解释。
所以这部分中,只解释network.py中的代码,但如果看注释就ok的话,就完全可以不用看下面的内容了。
原文代码中注释是英文的,我删除了一些、翻译了一些、又增添了一些,有信仰的话可以直接阅读源代码。
下面我们分块介绍:
1、初始化一个network对象
# 构造一个三层神经网络
# 输入层、隐藏层、输出层
class Network(object):
# 初始化神经网络
def __init__(self, sizes):
# size包含各层神经元的数量
# net = Network([2, 3, 1])表示创建一个三层神经网络
# 第一层有2个神经元,第二层有3个,第三层有1个
# 第一层为输入层,故不设置偏置biases
# 偏置biases仅在后面的层中用于计算输出
self.num_layers = len(sizes)
self.sizes = sizes
# 偏置biases和权重weights被随机初始化
# 使用np.random.randn函数来生成均值为0,标准差为1的高斯分布
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in list(zip(sizes[:-1], sizes[1:]))]在初始化network对象时,我们应该输入一个向量sizes,代表各层神经元的数量。
例如在run.py中,我们输入的向量为[784, 30, 10]
故层数num_layers=sizes的维数,即3层;
接下来我们需要调用np.random.randn函数给我们的参数【权重weights】和【偏置biases】初始化一个随机量,好接下来进行迭代。
(np.random.randn函数会生成均值为0,标准差为1的高斯分布。)
randn(y,1)的意思是:初始化y*1的矩阵,其中y的取值从sizes[1]开始到sizes数组的末尾,在本题中也就是30和10.
之所以不从sizes[0]开始,是因为第0层为输入层,不需要设置偏置。
同理,randn(y,x)的意思是:初始化y*x的矩阵,其中x的取值从sizes[0]开始到sizes数组的倒数第二个,sizes[:-1]的意思就是把倒数第一层去掉,本题中也就是784和30,y的取值依旧是30和10.
为什么要把倒数第一层去掉呢?因为我们的神经网络是这样的:
第一层input layer→第二层的输入:此时需要权重(一个30*784的矩阵)来表示第一层784个神经元的不同重要性;
第二层的输出→第三层的输入:此时需要权重(一个10*30的矩阵)来表示第二层30个神经元的不同重要性;
第三层的输出output:结果。
倒数第一层就是输出层了,当然不需要权重了啊。
2、激活函数:S型函数
# 对于网络给定一个输入a,对其激活后返回对应的输出a
def feedforward(self, a):
# 激活函数
for b, w in list(zip(self.biases, self.weights)):
a = sigmoid(np.dot(w, a)+b)
return a
# 中间代码省略
def sigmoid(z):
# 激活函数:S函数
return 1.0/(1.0+np.exp(-z))激活函数的计算过程:输入a→计算w*a+b→计算sigmoid(w*a+b)→将计算结果作为输出
3、学习过程:SGD
# 学习算法
def SGD(self,
training_data, # 一个(x,y)元组列表,
# 表示训练输入及对应的期望输出
epochs, # 迭代期数量
mini_batch_size, # 采样时的小批量数据的大小
eta, # 学习速率
test_data=None): # 若选中该参数,则程序会在每个训练器后评估网络,
# 打印出部分进展,会拖慢执行速度
if test_data: n_test = len(list(test_data))
n = len(list(training_data))
# 代码工作流程:
# 在每个迭代期epochs,
for j in range(epochs):
# 首先随机的将训练数据打乱
random.shuffle(training_data)
# 然后将它分成多个适当大小的小批量数据mini_batch
# 每个mini_batch都是一个(x,y)元组列表
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
# 对于每一个mini_batch,我们应用一次梯度下降
for mini_batch in mini_batches:
# 该方法使用mini_batch中的训练数据,根据单次梯度下降的迭代
# 更新网络的权重和偏置
self.update_mini_batch(mini_batch, eta)
# 若test_data为真,输出每个迭代期Epoch:正确测试数/总测试数
if test_data:
print("Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test))
else:
print("Epoch {0} complete".format(j))SGD方法所需参数:训练集数据(输入与期望输出),迭代期数量,小批量数据大小,学习速率eta,测试集数据
SGD方法工作流程:
在每个迭代期中:
① 将训练数据trainging_data打乱,乱序
② 将训练数据分成k份小批量数据mini_batch,每份大小为传入的参数mini_batch_size
③ 对于每一个mini_batch,调用update_mini_batch方法,应用梯度下降,更新一次权重w和偏置b
④ 调用evaluate方法,用test_data测试集数据进行测试(也叫评估网络),打印网络准确率
⑤ 本迭代期结束,进入下一个迭代期,直到达到迭代期数量epochs停止
4、更新权重和偏置:update_mini_batch
# 该方法使用mini_batch中的训练数据,根据单次梯度下降的迭代更新网络的权重和偏置
# 具体方法:对mini_batch中的每一个训练样本计算梯度,然后更新权重和偏置
def update_mini_batch(self, mini_batch, eta):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
# 下面这行代码调用了反向传播算法,一种快速计算代价函数loss的梯度的方法
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in list(zip(nabla_b, delta_nabla_b))]
nabla_w = [nw+dnw for nw, dnw in list(zip(nabla_w, delta_nabla_w))]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in list(zip(self.weights, nabla_w))]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in list(zip(self.biases, nabla_b))]可以看到:核心代码为调用backprop方法,即反向传播算法,来快速计算代价函数(C)的梯度。
而可以看到,最后两行正是我们在准备篇最后推导出来的公式:
5、反向传播算法:backprop
我们将在下章下个系列的学习笔记中展示反向传播算法的工作,现在只需知道其返回与训练样本x相关代价的适当梯度,以便于我们更新权重和偏置就好。
三、尝试调参
在run.py中,我们传递了许多参数,比如隐藏层神经元为30个,还有许多超参数,比如迭代期为30次,小批量数据大小为10,学习速率为3.0,那么调整这些参数,对准确率有何影响呢?
注:权重w和偏置b的初始化也很重要,但本文用的是随机初始化,因此打印出的准确率可能每次差异略大。
1、将隐藏层神经元改到100
显而易见,运行时间变…长…了,但准确率提高了。
ps:如果你的准确率没有提高,不要怀疑我,更不要怀疑作者。拜随机初始化w和b所赐,每一次的运行结果都是玄学。

2、将学习速率分别改到0.001和100.0
令人伤心的是,学习速率过小、过大都会使准确率大幅度下降。
(凌晨一点了,原谅我懒得测试全部迭代期orz,领会精神就好,参数很重要!)


调参是一门玄学吗?
作者:调参是一门艺术。
我们需要启发式方法来选择好的超参数和好的结构,我们会在接下来的学习中讨论这些。
四、
【2018/11/20后记】
1、又肝到凌晨一点,终于把本书第1章的学习笔记整理完了……没想到一共写了3篇这么多orz,一开始就想写个提纲式的东西,没想到写着写着就动了情(呸),写着写着就投入感情了,就像每次凌晨为自己深爱的项目、亲自动手一点一点写报告、做各种测试分析……一样的真情实感。
2、接下来还有
第2章:反向传播算法如何工作;
第3章:改进神经网络的学习方法;
第4章:神经网络可以计算任何函数;
第5章:深度神经网络为何很难训练;
以及最后一章:深度学习。
然而最近真的要准备考试了,再不准备就要被挂科劝退了orz,所以,等有时间再更吧。
再次推荐阅读原书,真的对新手超级友好。
3、下周二考完试之前不再上CSDN了,qwq。考完试之后大概会把三个大作业的源码整理好发上来。