前言
最近公司需要将几张统计表格导出到excel,由于公司现有导出excel功能是前后端配合的导出,觉得麻烦,所以想找一个纯前端导出的工具,最后找到了js-xlsx,评价还是挺高的,但是中文文档没找到,百度也没有找到一个比较全面的教程,所以踩了很多坑,自己记录下,方便以后使用。
环境
由于我业务只用到将table标签内的内容导出到excel,所以只会写如何将一个table元素里的内容导出到excel。也可以通过json导出,貌似还会更简单些。
安装
GitHub地址
npm安装
npm install xlsx
安装后dist文件夹下有一个文件xlsx.full.min.js,就是它了,引入到项目中
第一个例子
先上代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<table id="table1" border="1" cellspacing="0" cellpadding="0" >
<thead>
<tr>
<td>序号</td>
<td>姓名</td>
<td>年龄</td>
<td>兴趣</td>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>张三</td>
<td>18</td>
<td>打游戏</td>
</tr>
<tr>
<td>2</td>
<td>李四</td>
<td>88</td>
<td>看电影</td>
</tr>
<tr>
<td>3</td>
<td>王五</td>
<td>81</td>
<td>睡觉</td>
</tr>
</tbody>
</table>
<button id="btn" onclick="btn_export()">导出</button>
</body>
<script src="js/xlsx.full.min.js"></script>
<script src="js/export.js"></script>
<script>
function btn_export() {
var table1 = document.querySelector("#table1");
var sheet = XLSX.utils.table_to_sheet(table1);//将一个table对象转换成一个sheet对象
openDownloadDialog(sheet2blob(sheet),'下载.xlsx');
}
</script>
</html>
运行效果

导出结果:
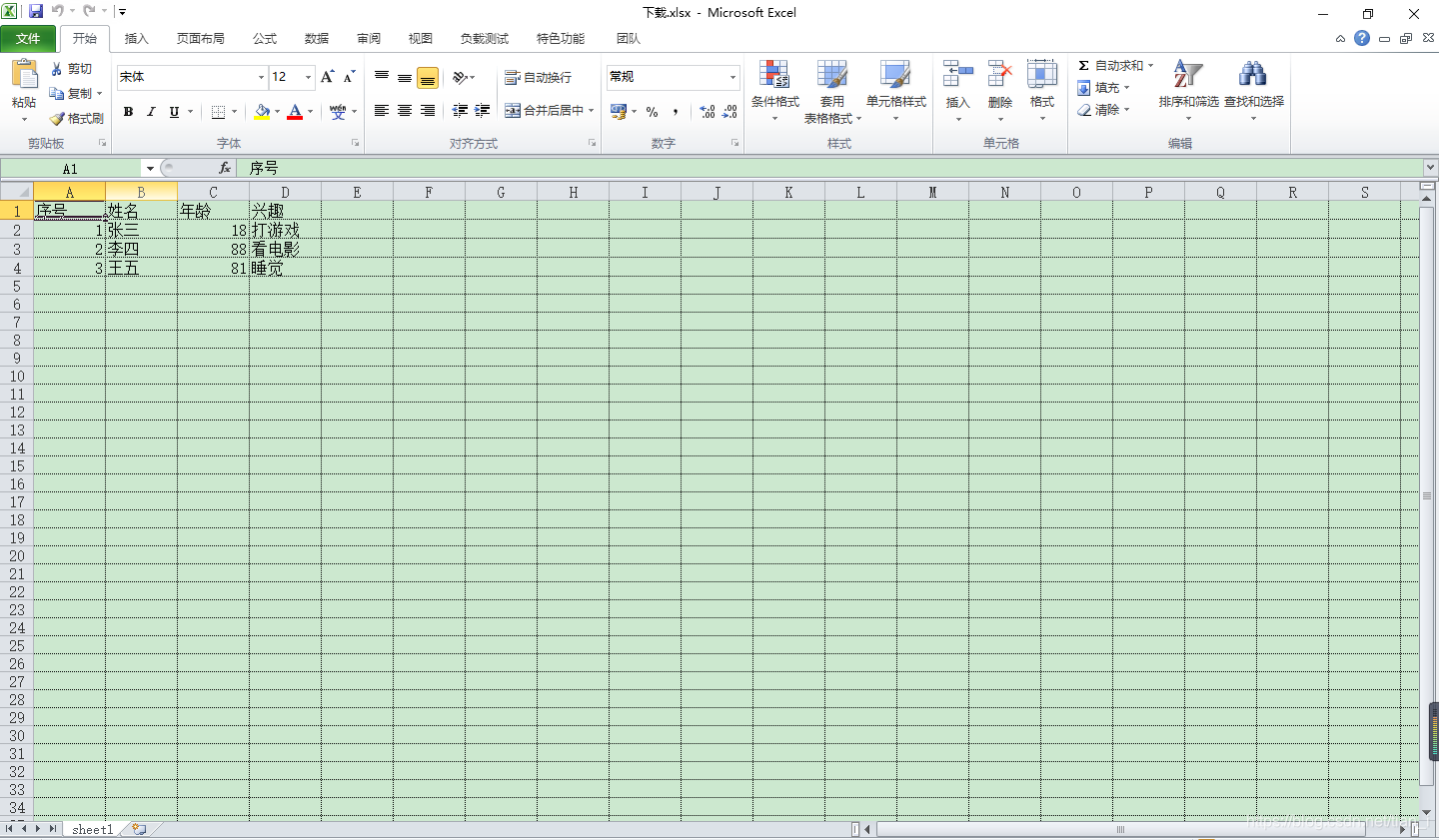
你可能注意到了,我这里引入了一个export.js文件,这个export.js文件里面只有2个方法,就是上面代码用到的openDownloadDialog(sheet2blob(sheet),‘下载.xlsx’);
这是export.js的代码:
// 将一个sheet转成最终的excel文件的blob对象,然后利用URL.createObjectURL下载
function sheet2blob(sheet, sheetName) {
sheetName = sheetName || 'sheet1';
var workbook = {
SheetNames: [sheetName],
Sheets: {}
};
workbook.Sheets[sheetName] = sheet; // 生成excel的配置项
var wopts = {
bookType: 'xlsx', // 要生成的文件类型
bookSST: false, // 是否生成Shared String Table,官方解释是,如果开启生成速度会下降,但在低版本IOS设备上有更好的兼容性
type: 'binary'
};
var wbout = XLSX.write(workbook, wopts);
var blob = new Blob([s2ab(wbout)], {
type: "application/octet-stream"
}); // 字符串转ArrayBuffer
function s2ab(s) {
var buf = new ArrayBuffer(s.length);
var view = new Uint8Array(buf);
for (var i = 0; i != s.length; ++i) view[i] = s.charCodeAt(i) & 0xFF;
return buf;
}
return blob;
}
function openDownloadDialog(url, saveName) {
if (typeof url == 'object' && url instanceof Blob) {
url = URL.createObjectURL(url); // 创建blob地址
}
var aLink = document.createElement('a');
aLink.href = url;
aLink.download = saveName || ''; // HTML5新增的属性,指定保存文件名,可以不要后缀,注意,file:///模式下不会生效
var event;
if (window.MouseEvent) event = new MouseEvent('click');
else {
event = document.createEvent('MouseEvents');
event.initMouseEvent('click', true, false, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null);
}
aLink.dispatchEvent(event);
}
PS: 这2个方法是网上当的,原文地址。作者写的挺好,也是从这里找到了头绪。
如果你的table标签内有合并单元格的操作,XLSX.utils.table_to_sheet(*)也能够读取出来,并且你打印出来的结果也能够显示出来,效果图:
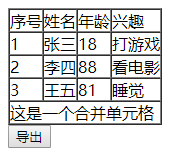
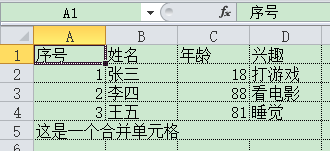
可以看到,excel中的表格也已经合并了。
但是实际的情况,客户觉得这行字没有居中,他就会向你唠叨,为啥不居中,所以我们现在解决文字不居中的问题。
设置样式(居中,文字大小颜色,背景色…)
PS:这是我踩坑最多的地方…
这里就不绕圈子了,设置样式的话,上面的xlsx.full.min.js是无法生效的,
必须安装xlsx-style
安装xlsx-style
好像只有npm安装,github我没找到地址
npm install xlsx-style
同样,安装目录下dist文件夹下有一个xlsx.full.min.js,嗯?名字一模一样?怎么用?好吧,无从下手,只好硬着头皮引入了,注意,我将xlsx-style的js文件放在下方:

还有btn_export()方法要变一下,加一下样式。
具体的单元格样式说明可以看下这篇文章 xlsx-style单元格样式参考表
function btn_export() {
var table1 = document.querySelector("#table1");
var sheet = XLSX.utils.table_to_sheet(table1);
//这个就是修改格式的代码
sheet["A5"].s = {
font: { sz: 13, bold: true, },
alignment: {
horizontal: "center", vertical: "center", wrap_text: true
}
};
openDownloadDialog(sheet2blob(sheet),'下载.xlsx');
}
改完之后,点击运行,果不其然,报错了:

原因是什么呢,原因是2个js文件暴露出来的变量都叫‘XLSX’,但是xlsx-style这个js文件里没有XLSX.utils这个方法,而且xlsx-style这个js文件是后引入的,就把前面的XLSX给覆盖了,所以报错。
XLSX.utils里面有很多可用的方法,但是按照这种方式无法进行调用:
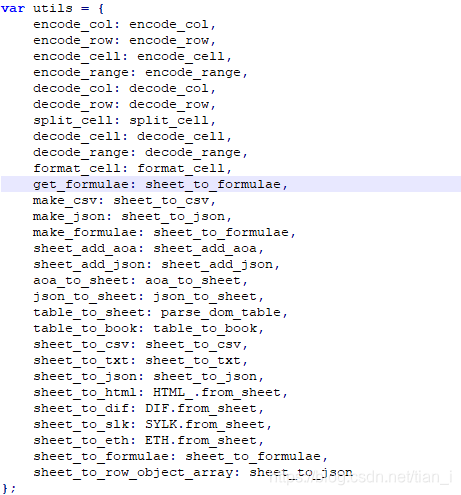
你可能想到把2个js文件调换一下位置,但是结果是xlsx暴露的变量覆盖了xlsx-style暴露的变量。你的样式还是改变不了。
注意
如果你的导出功能 是传入json格式或其他格式而没有用到XLSX.utils的话,你只需使用xlsx-style的js,下面的内容可以忽略,下面的内容是讲如何使xlsx和xlsx-style的js一起工作的。
由于这2个js都是加密之后的内容,无法解读,不能在这2个js上找到什么有用的东西。好在在xlsx dist文件夹下找到了xlsx.extendscript.js,看这个文件就像个工具类,由于我上面用到了table_to_sheet方法,在xlsx.extendscript上面的搜索了一下,果然发现了这个方法,二话不说,将xlsx的js引用删除,引入xlsx.extendscript:

运行。结果你应该已经猜到了,样式并没有发生改变。什么原因呢,xlsx.extendscript.js暴露出来的变量仍然是’XLSX’,下面的变量还是覆盖了上面的变量。
好在这个xlsx.extendscript.js不是压缩版本,可以对内容进行修改,就把暴露出来的变量修改为’XLSX2’吧。这样我们只有在使用utils工具的时候才用到xlsx.extendscript.js,其余都用的是xlsx-style这个js,这样总该可以了吧 。
修改完之后别忘了将XSLX.utils.table_to_sheet()改成XLSX2.utils.table_to_sheet()。
(不建议修改源码,由于工作需要不修改源码无法使用才做的修改)
function btn_export() {
var table1 = document.querySelector("#table1");
var sheet = XLSX2.utils.table_to_sheet(table1);
sheet["A5"].s = {
font: {
sz: 13,
bold: true,
color: {
rgb: "FFFFAA00"
}
},
alignment: {
horizontal: "center",
vertical: "center",
wrap_text: true
}
};
openDownloadDialog(sheet2blob(sheet), '下载.xlsx');
}
运行:
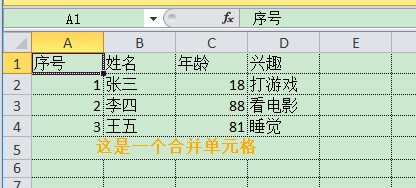
可以看到,你所做的样式更改已经生效了。
客户需求增加:我想要前面几行空出来,并且写上打印公司名。
观察xlsx.extendscript.js源码,发现table_to_sheet,也就是parse_dom_table,并没有设置起始行的参数,下面给出parse_dom_table的代码:
function parse_dom_table(table, _opts) {
var opts = _opts || {};
if(DENSE != null) opts.dense = DENSE;
var ws = opts.dense ? ([]) : ({});
var rows = table.getElementsByTagName('tr');
var sheetRows = opts.sheetRows || 10000000;
var range = {s:{r:0,c:0},e:{r:0,c:0}};
var merges = [], midx = 0;
var rowinfo = [];
var _R = 0, R = 0, _C, C, RS, CS;
for(; _R < rows.length && R < sheetRows; ++_R) {
var row = rows[_R];
if (is_dom_element_hidden(row)) {
if (opts.display) continue;
rowinfo[R] = {hidden: true};
}
var elts = (row.children);
for(_C = C = 0; _C < elts.length; ++_C) {
var elt = elts[_C];
if (opts.display && is_dom_element_hidden(elt)) continue;
var v = htmldecode(elt.innerHTML);
for(midx = 0; midx < merges.length; ++midx) {
var m = merges[midx];
if(m.s.c == C && m.s.r <= R && R <= m.e.r) { C = m.e.c+1; midx = -1; }
}
/* TODO: figure out how to extract nonstandard mso- style */
CS = +elt.getAttribute("colspan") || 1;
if((RS = +elt.getAttribute("rowspan"))>0 || CS>1) merges.push({s:{r:R,c:C},e:{r:R + (RS||1) - 1, c:C + CS - 1}});
var o = {t:'s', v:v};
var _t = elt.getAttribute("t") || "";
if(v != null) {
if(v.length == 0) o.t = _t || 'z';
else if(opts.raw || v.trim().length == 0 || _t == "s"){}
else if(v === 'TRUE') o = {t:'b', v:true};
else if(v === 'FALSE') o = {t:'b', v:false};
else if(!isNaN(fuzzynum(v))) o = {t:'n', v:fuzzynum(v)};
else if(!isNaN(fuzzydate(v).getDate())) {
o = ({t:'d', v:parseDate(v)});
if(!opts.cellDates) o = ({t:'n', v:datenum(o.v)});
o.z = opts.dateNF || SSF._table[14];
}
}
if(opts.dense) { if(!ws[R]) ws[R] = []; ws[R][C] = o; }
else ws[encode_cell({c:C, r:R})] = o;
if(range.e.c < C) range.e.c = C;
C += CS;
}
++R;
}
if(merges.length) ws['!merges'] = merges;
if(rowinfo.length) ws['!rows'] = rowinfo;
range.e.r = R - 1;
ws['!ref'] = encode_range(range);
if(R >= sheetRows) ws['!fullref'] = encode_range((range.e.r = rows.length-_R+R-1,range)); // We can count the real number of rows to parse but we don't to improve the performance
return ws;
}
那自己加一个吧
可以看到,里面的R变量 这是控制起始行的关键所在,好吧,我们再做一下修改:
var _R = 0, R = _opts.rowIndex || 0, _C, C, RS, CS;
这里我们给_opts增加一个属性rowIndex,在调用table_to_sheet方法的时候传入这个属性。下面是变更后的代码:
function btn_export() {
var table1 = document.querySelector("#table1");
var opt = {
rowIndex: 4
}; //开头空4行
var sheet = XLSX2.utils.table_to_sheet(table1, opt);
sheet["A1"] = {
t: "s",
v: '三鹿集团有限公司'
}; //给A1单元格赋值
sheet["A1"].s = {
font: {
name: '宋体',
sz: 24,
bold: true,
underline: true,
color: {
rgb: "FFFFAA00"
}
},
alignment: { horizontal: "center", vertical: "center", wrap_text: true },
fill: {
bgColor: { rgb: 'ffff00' }
}
};
//["!merges"]这个属性是专门用来进行单元格合并的
sheet["!merges"].push({//如果不为空push 为空 = 赋值
//合并单元格 index都从0开始
s: { //s开始
c: 0, //开始列
r: 0 //开始行
},
e: { //e结束
c: 3, //结束列
r: 2 //结束行
}
});
sheet["A9"].s = { //样式
font: {
sz: 13,
bold: true,
color: {
rgb: "FFFFAA00"
}
},
alignment: {
horizontal: "center",
vertical: "center",
wrap_text: true
}
};
openDownloadDialog(sheet2blob(sheet), '下载.xlsx');
}
运行结果:
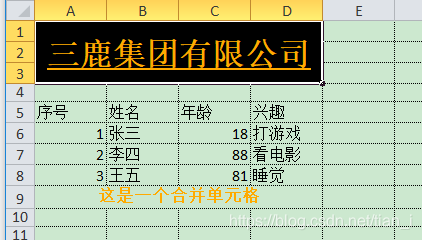
可以看到,你所做的更改生效了。
客户又提新需求了,要加上2个字段,身份证号和手机号。
这还不简单?加上2个字段不就好了。2分钟搞定,导出:
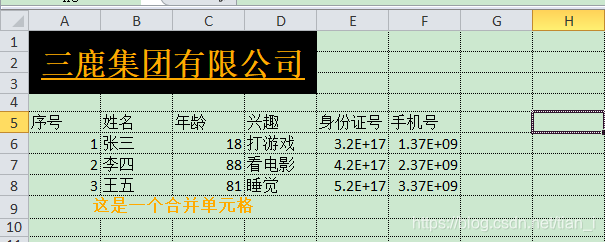
???
身份证号怎么变成了科学计数法,什么鬼(后来发现百分比也会直接给你换算成0~1的小数,统计没法搞)
怎么回事?还是parse_dom_table的杰作!
注意这一行:
else if(!isNaN(fuzzynum(v))) o = {t:'n', v:fuzzynum(v)};
意思是只要从td的text里读取到的值,只要转换之后是一个number,(不管你是string类型),都会给你来一个fuzzynum(v),转换成一个number类型。
做下修改,结果:
function parse_dom_table(table, _opts) {
var opts = _opts || {};
if(DENSE != null) opts.dense = DENSE;
var ws = opts.dense ? ([]) : ({});
var rows = table.getElementsByTagName('tr');
var sheetRows = opts.sheetRows || 10000000;
var range = {s:{r:0,c:0},e:{r:0,c:0}};
var merges = [], midx = 0;
var rowinfo = [];
var _R = 0, R = _opts.rowIndex || 0, _C, C, RS, CS;
for(; _R < rows.length && R < sheetRows; ++_R) {
var row = rows[_R];
if (is_dom_element_hidden(row)) {
if (opts.display) continue;
rowinfo[R] = {hidden: true};
}
var elts = (row.children);
for(_C = C = 0; _C < elts.length; ++_C) {
var elt = elts[_C];
if (opts.display && is_dom_element_hidden(elt)) continue;
var v = htmldecode(elt.innerHTML);
for(midx = 0; midx < merges.length; ++midx) {
var m = merges[midx];
if(m.s.c == C && m.s.r <= R && R <= m.e.r) { C = m.e.c+1; midx = -1; }
}
/* TODO: figure out how to extract nonstandard mso- style */
CS = +elt.getAttribute("colspan") || 1;
if((RS = +elt.getAttribute("rowspan"))>0 || CS>1) merges.push({s:{r:R,c:C},e:{r:R + (RS||1) - 1, c:C + CS - 1}});
var o = {t:'s', v:v};
var _t = elt.getAttribute("t") || "";
if(v != null) {
if(v.length == 0) o.t = _t || 'z';
else if(opts.raw || v.trim().length == 0 || _t == "s"){}
else if(v === 'TRUE') o = {t:'b', v:true};
else if(v === 'FALSE') o = {t:'b', v:false};
//else if(!isNaN(fuzzynum(v))) o = {t:'n', v:fuzzynum(v)};
else if(!isNaN(fuzzynum(v))) o = {t:'s', v:v};//不自动格式化number类型
else if(!isNaN(fuzzydate(v).getDate())) {
o = ({t:'d', v:parseDate(v)});
if(!opts.cellDates) o = ({t:'n', v:datenum(o.v)});
o.z = opts.dateNF || SSF._table[14];
}
}
if(opts.dense) { if(!ws[R]) ws[R] = []; ws[R][C] = o; }
else ws[encode_cell({c:C, r:R})] = o;
if(range.e.c < C) range.e.c = C;
C += CS;
}
++R;
}
if(merges.length) ws['!merges'] = merges;
if(rowinfo.length) ws['!rows'] = rowinfo;
range.e.r = R - 1;
ws['!ref'] = encode_range(range);
if(R >= sheetRows) ws['!fullref'] = encode_range((range.e.r = rows.length-_R+R-1,range)); // We can count the real number of rows to parse but we don't to improve the performance
return ws;
}
将转换的语句注释掉,重写这行代码,如果是number类型,不做任何修改,该是什么值还是什么值。
现在再重新运行,结果:
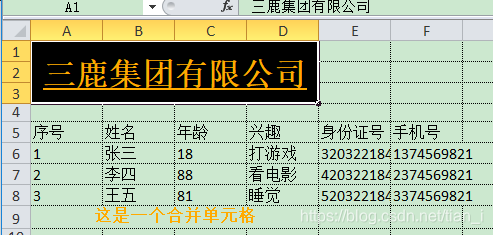 可以看到,数字能够正常显示了。但是这个单元格好像并不会自动展开,永远都这么大,xlsx-style 也提供了控制单元格宽度的方法:
可以看到,数字能够正常显示了。但是这个单元格好像并不会自动展开,永远都这么大,xlsx-style 也提供了控制单元格宽度的方法:
sheet["!cols"] = [{
wpx: 70
}, {
wpx: 70
}, {
wpx: 70
}, {
wpx: 70
}, {
wpx: 150
}, {
wpx: 120
}]; //单元格列宽
注意,设置单元格列宽要从第一行开始设置
结果:
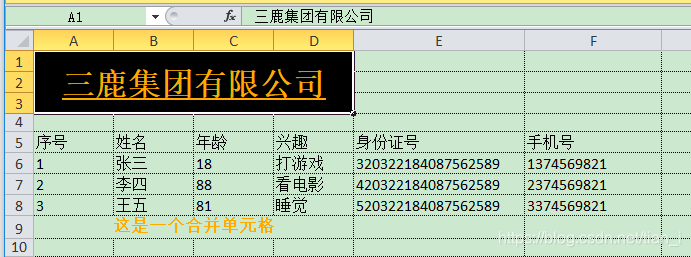
完整前端代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<table id="table1" border="1" cellspacing="0" cellpadding="0">
<thead>
<tr>
<td>序号</td>
<td>姓名</td>
<td>年龄</td>
<td>兴趣</td>
<td>身份证号</td>
<td>手机号</td>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>张三</td>
<td>18</td>
<td>打游戏</td>
<td>320322184087562589</td>
<td>1374569821</td>
</tr>
<tr>
<td>2</td>
<td>李四</td>
<td>88</td>
<td>看电影</td>
<td>420322184087562589</td>
<td>2374569821</td>
</tr>
<tr>
<td>3</td>
<td>王五</td>
<td>81</td>
<td>睡觉</td>
<td>520322184087562589</td>
<td>3374569821</td>
</tr>
<tr>
<td colspan="4">这是一个合并单元格</td>
</tr>
</tbody>
</table>
<button id="btn" onclick="btn_export()">导出</button>
</body>
<script src="js/xlsx.extendscript.js"></script>
<script src="js/xlsx-style/xlsx.full.min.js"></script>
<script src="js/export.js"></script>
<script>
function btn_export() {
var table1 = document.querySelector("#table1");
var opt = {
rowIndex: 4
}; //开头空4行
var sheet = XLSX2.utils.table_to_sheet(table1, opt);
sheet["A1"] = {
t: "s",
v: '三鹿集团有限公司'
}; //给A1单元格赋值
sheet["A1"].s = {
font: {
name: '宋体',
sz: 24,
bold: true,
underline: true,
color: {
rgb: "FFFFAA00"
}
},
alignment: {
horizontal: "center",
vertical: "center",
wrap_text: true
},
fill: {
bgColor: {
rgb: 'ffff00'
}
}
};
//["!merges"]这个属性是专门用来进行单元格合并的
sheet["!merges"].push({ //如果不为空push 为空 = 赋值
//合并单元格 index都从0开始
s: { //s开始
c: 0, //开始列
r: 0 //开始行
},
e: { //e结束
c: 3, //结束列
r: 2 //结束行
}
});
sheet["A9"].s = { //样式
font: {
sz: 13,
bold: true,
color: {
rgb: "FFFFAA00"
}
},
alignment: {
horizontal: "center",
vertical: "center",
wrap_text: true
}
};
sheet["!cols"] = [{
wpx: 70
}, {
wpx: 70
}, {
wpx: 70
}, {
wpx: 70
}, {
wpx: 150
}, {
wpx: 120
}]; //单元格列宽
openDownloadDialog(sheet2blob(sheet), '下载.xlsx');
}
</script>
</html>
demo源码
总结
- 不是特殊情况不建议修改源码
- 因为毕竟修改了代码,所以这种方法只能面向小众
- 听过收费版功能很全,建议如果有需要的话还是购买收费版本,但是地址没找到…
- 可以根据自己需求对xlsx源码进行修改,以便满足自己工作的需求。但是这样较难以维护,如何取舍还是自行斟酌。
- 我这里只列取了我实际工作中所需要的功能,xlsx的功能很丰富,有空可以多琢磨琢磨。