概述
当我们创建一个对象时:
SWHunter *hunter = [[SWHunter alloc] init];上面这行代码在栈上创建了hunter指针,并在堆上创建了一个SWHunter对象。目前,iOS并不支持在栈上创建对象。
iOS 内存分区
iOS的内存管理是基于虚拟内存的。虚拟内存能够让每一个进程都能够在逻辑上“独占”整个设备的内存。关于虚拟内存,可以参考这里。
iOS又将虚拟内存按照地址由低到高划分为如下五个区:
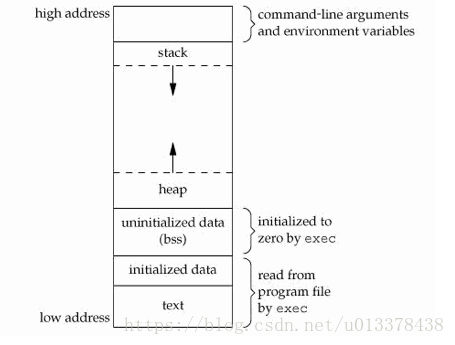
- 代码区: 存放APP二进制代码
- 常量区:存放程序中定义的各种常量, 包括字符串常量,各种被const修饰的常量
- 全局/静态区: 全局变量,静态变量就放在这里
- 堆区:在程序运行时调用alloc,copy,mutablecopy,new会在堆上分配内存。堆内存需要程序员手动释放,这在ARC中是通过引用计数的形式表现的。堆分配地址不连续,但整体是地址从低到高地址分配
- 栈区:存放局部变量,当变量超出作用域时,内存会被系统自动释放。栈上的地址连续分配,在内存地址由高向低增长
在程序运行时,代码区,常量区以及全局静态区的大小是固定的,会变化的只有栈和堆的大小。而栈的内存是有操作系统自动释放的,我们平常说所的iOS内存引用计数,其实是就堆上的对象来说的。
下面,我们就来看一下,在runtime中,是如何通过引用计数来管理内存的。
tagged pointer
首先,来想这么一个问题,在平常的编程中,我们使用的NSNumber对象来表示数字,最大会有多大?几万?几千万?甚至上亿?
我相信,对于绝大多数程序来说,用不到上亿的数字。同样,对于字符串类型,绝大多数时间,字符个数也在8个以内。
再想另一个方面,自2013年苹果推出iphone5s之后,iOS的寻址空间扩大到了64位。我们可以用63位来表示一个数字(一位做符号位),这是一个什么样的概念?2^31=2147483648,也达到了20多亿,而2^63这个数字,用到的概率基本为零。比如NSNumber *num=@10000的话,在内存中则会留下很多无用的空位。这显然浪费了内存空间。
苹果当然也发现了这个问题,于是就引入了tagged pointer。tagged pointer是一种特殊的“指针”,其特殊在于,其实它存储的并不是地址,而是真实的数据和一些附加的信息。
在引入tagged pointer 之前,iOS对象的内存结构如下所示(摘自唐巧博客):
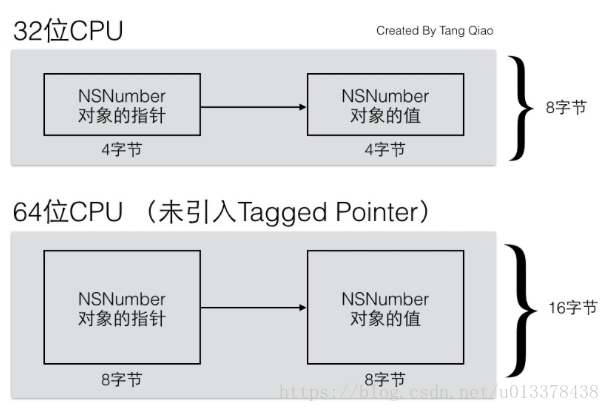
显然,本来4字节就可以表示的数值,现在却用了8字节,明显的内存浪费。而引入了tagged pointer 后, 其内存布局如下
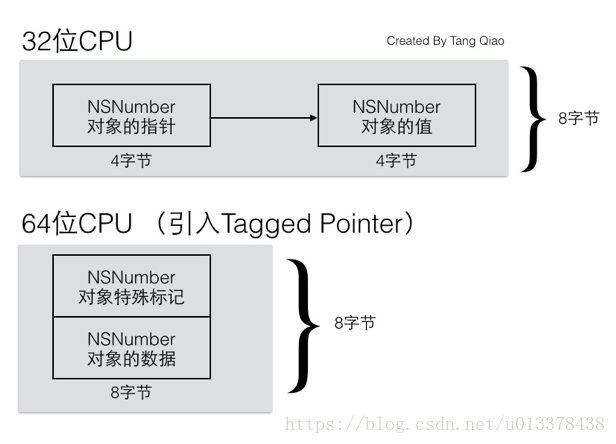
可以看到,利用tagged pointer后,“指针”又存储了对本身,也存储了和对象相关的标记。这时的tagged pointer里面存储的不是地址,而是一个数据集合。同时,其占用的内存空间也由16字节缩减为8字节。
我们可以在WWDC2013的《Session 404 Advanced in Objective-C》视频中,看到苹果对于Tagged Pointer特点的介绍:
- Tagged Pointer专门用来存储小的对象,例如NSNumber, NSDate, NSString。
- Tagged Pointer指针的值不再是地址了,而是真正的值。所以,实际上它不再是一个对象了,它只是一个披着对象皮的普通变量而已。所以,它的内存并不存储在堆中,也不需要malloc和free。
- 在内存读取上有着3倍的效率,创建时比以前快106倍。
运行如下代码:
NSMutableString *mutableStr = [NSMutableString string];
NSString *immutable = nil;
#define _OBJC_TAG_MASK (1UL<<63)
char c = 'a';
do {
[mutableStr appendFormat:@"%c", c++];
immutable = [mutableStr copy];
NSLog(@"%p %@ %@", immutable, immutable, immutable.class);
}while(((uintptr_t)immutable & _OBJC_TAG_MASK) == _OBJC_TAG_MASK);输出为:
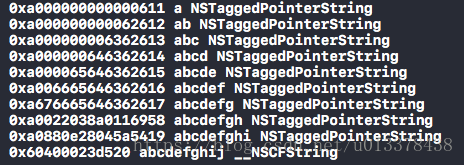
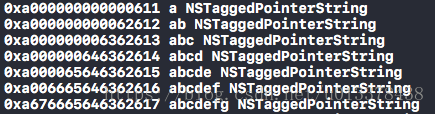
我们看到,字符串由‘a’增长到‘abcdefghi’的过程中,其地址开头都是0xa 而结尾也很有规律,是1到9递增,正好对应着我们的字符串长度,同时,其输出的class类型为NSTaggedPointerString。在字符串长度在9个以内时,iOS其实使用了tagged pointer做了优化的。
直到字符串长度大于9,字符串才真正成为了__NSCFString类型。
我们回头分析一下上面的代码。
首先,iOS需要一个标志位来判断当前指针是真正的指针还是tagged pointer。这里有一个宏定义_OBJC_TAG_MASK (1UL<<63) ,它表明如果64位数据中,最高位是1的话,则表明当前是一个tagged pointer类型。
然后,既然使用了tagged pointer,那么就失去了iOS对象的数据结构,但是,系统还是需要有个标志位表明当前的tagged pointer 表示的是什么类型的对象。这个标志位,也是在最高4位来表示的。我们将0xa转换为二进制,得到
1010,其中最高位1xxx表明这是一个tagged pointer,而剩下的3位010,表示了这是一个NSString类型。010转换为十进制即为2。也就是说,标志位是2的tagger pointer表示这是一个NSString对象。
在runtime源码的objc-internal.h中,有关于标志位的定义如下:
{
OBJC_TAG_NSAtom = 0,
OBJC_TAG_1 = 1,
OBJC_TAG_NSString = 2,
OBJC_TAG_NSNumber = 3,
OBJC_TAG_NSIndexPath = 4,
OBJC_TAG_NSManagedObjectID = 5,
OBJC_TAG_NSDate = 6,
OBJC_TAG_RESERVED_7 = 7,
OBJC_TAG_First60BitPayload = 0,
OBJC_TAG_Last60BitPayload = 6,
OBJC_TAG_First52BitPayload = 8,
OBJC_TAG_Last52BitPayload = 263,
OBJC_TAG_RESERVED_264 = 264
};最后,让我们再尝试分析一下NSString类型的tagged pointer是如何实现的。
我们前面已经知道,在总共64位数据中,高4位被用于标志tagged pointer以及对象类型标识。低1位用于记录字符串字符个数,那么还剩下59位可以让我们表示数据内容。
对于字符串格式,怎么来表示内容呢?自然的,我们想到了ASCII码。对应ASCII码,a用16进制ASCII码表示为0x61,b为0x62, 依次类推。在字符串长度增加到8个之前,tagged pointer的内容如下。可以看到,从最低2位开始,分别为61,62,63… 这正对应了字符串中字符的ASCII码。
直到字符串增加到7个之上,我们仍然可以分辨出tagged pointer中的标志位以及字符串长度,但是中间的内容部分,却不符合ASCII的编码规范了。

这是因为,iOS对字符串使用了压缩算法,使得tagged pointer表示的字符串长度最大能够达到9个。关于具体的压缩算法,我们就不再讨论了。由于苹果内部会对实现逻辑作出修改,因此我们只要知道有tagged pointer 的概念就好了。有兴趣的同学可以看采用Tagged Pointer的字符串,但其内容也有些过时了,和我们的实验结果并不一致。
我们顺便看一下NSNumber的tagged pointer实现:
NSNumber *number1 = @(0x1);
NSNumber *number2 = @(0x20);
NSNumber *number3 = @(0x3F);
NSNumber *numberFFFF = @(0xFFFFFFFFFFEFE);
NSNumber *maxNum = @(MAXFLOAT);
NSLog(@"number1 pointer is %p class is %@", number1, number1.class);
NSLog(@"number2 pointer is %p class is %@", number2, number2.class);
NSLog(@"number3 pointer is %p class is %@", number3, number3.class);
NSLog(@"numberffff pointer is %p class is %@", numberFFFF, numberFFFF.class);
NSLog(@"maxNum pointer is %p class is %@", maxNum, maxNum.class);
可以看到,对于MAXFLOAT,系统无法进行优化,输出的是一个正常的NSNumber对象地址。而对于其他的number值,系统采用了tagged pointer,其‘地址’都是以0xb开头,转换为二进制就是1011, 首位1表示这是一个tagged pointer,而011转换为十进制是3,参考前面tagged pointer的类型枚举,这是一个NSNumber类型。接下来几位,就是以16进制表示的NSNumber的值,而对于最后一位,应该是一个标志位,具体作用,笔者也不是很清楚。
isa
由于一个tagged pointer所指向的并不是一个真正的OC对象,它其实是没有isa属性的。
在runtime中,可以这样获取isa的内容:
#define _OBJC_TAG_SLOT_SHIFT 60
#define _OBJC_TAG_EXT_SLOT_MASK 0xff
inline Class
objc_object::getIsa()
{
// 如果不是tagged pointer,则返回ISA()
if (!isTaggedPointer()) return ISA();
// 如果是tagged pointer,取出高4位的内容,查找对应的class
uintptr_t ptr = (uintptr_t)this;
uintptr_t slot = (ptr >> _OBJC_TAG_SLOT_SHIFT) & _OBJC_TAG_SLOT_MASK;
return objc_tag_classes[slot];
}在runtime中,还有专用的方法用于判断指针是tagged pointer还是普通指针:
# define _OBJC_TAG_MASK (1UL<<63)
static inline bool
_objc_isTaggedPointer(const void * _Nullable ptr)
{
return ((uintptr_t)ptr & _OBJC_TAG_MASK) == _OBJC_TAG_MASK;
}isa 指针(NONPOINTER_ISA)
对象的isa指针,用来表明对象所属的类类型。
但是如果isa指针仅表示类型的话,对内存显然也是一个极大的浪费。于是,就像tagged pointer一样,对于isa指针,苹果同样进行了优化。isa指针表示的内容变得更为丰富,除了表明对象属于哪个类之外,还附加了引用计数extra_rc,是否有被weak引用标志位weakly_referenced,是否有附加对象标志位has_assoc等信息。
这里,我们仅关注isa中和内存引用计数有关的extra_rc 以及相关内容。
首先,我们回顾一下isa指针是怎么在一个对象中存储的。下面是runtime相关的源码:
@interface NSObject <NSObject> {
Class isa OBJC_ISA_AVAILABILITY;
}
typedef struct objc_class *Class;
// ============ 注意!从这一行开始,其定义就和在XCode中objc.h看到的定义不一致,我们需要阅读runtime的源码,才能看到其真实的定义!下面是简化版的定义:============
struct objc_class : objc_object {
Class superclass;
cache_t cache; // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
}
struct objc_object {
private:
isa_t isa;
}
union isa_t
{
isa_t() { }
isa_t(uintptr_t value) : bits(value) { }
Class cls;
uintptr_t bits;
# if __arm64__
# define ISA_MASK 0x0000000ffffffff8ULL
# define ISA_MAGIC_MASK 0x000003f000000001ULL
# define ISA_MAGIC_VALUE 0x000001a000000001ULL
struct {
uintptr_t nonpointer : 1;
uintptr_t has_assoc : 1;
uintptr_t has_cxx_dtor : 1;
uintptr_t shiftcls : 33; // MACH_VM_MAX_ADDRESS 0x1000000000
uintptr_t magic : 6;
uintptr_t weakly_referenced : 1;
uintptr_t deallocating : 1;
uintptr_t has_sidetable_rc : 1;
uintptr_t extra_rc : 19;
# define RC_ONE (1ULL<<45)
# define RC_HALF (1ULL<<18)
};
}结合下面的图,我们可以更清楚的了解runtime中对象和类的结构定义,显然,类也是一种对象,这就是类对象的含义。
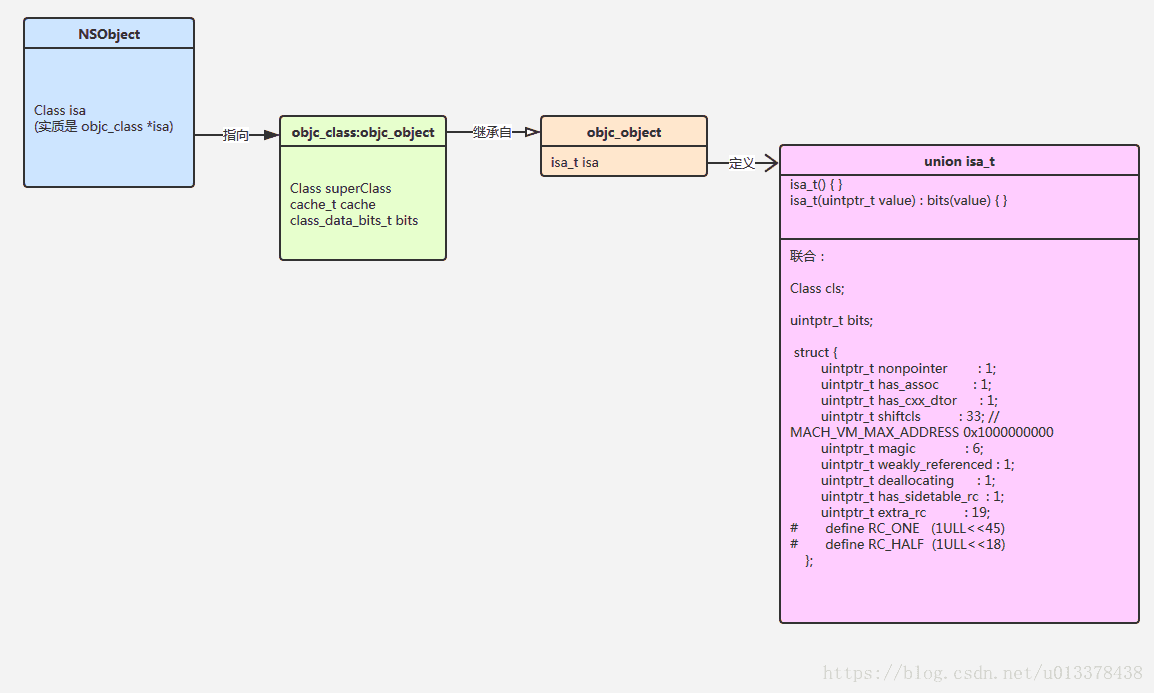
从图中可以看出,我们所谓的isa指针,最后实际上落脚于isa_t的联合类型。联合类型 是C语言中的一种类型,简单来说,就是一种n选1的关系。比如isa_t 中包含有cls,bits, struct三个变量,它们的内存空间是重叠的。在实际使用时,仅能够使用它们中的一种,你把它当做cls,就不能当bits访问,你把它当bits,就不能用cls来访问。
联合的作用在于,用更少的空间,表示了更多的可能的类型,虽然这些类型是不能够共存的。
将注意力集中在isa_t联合上,我们该怎样理解它呢?
首先它有两个构造函数isa_t(), isa_t(uintptr_value), 这两个定义很清晰,无需多言。
然后它有三个数据成员Class cls, uintptr_t bits, struct 。 其中uintptr_t被定义为typedef unsigned long uintptr_t,占据64位内存。
关于上面三个成员, uintptr_t bits 和 struct 其实是一个成员,它们都占据64位内存空间,之前已经说过,联合类型的成员内存空间是重叠的。在这里,由于uintptr_t bits 和 struct 都是占据64位内存,因此它们的内存空间是完全重叠的。而你将这块64位内存当做是uintptr_t bits 还是 struct,则完全是逻辑上的区分,在内存空间上,其实是一个东西。
即uintptr_t bits 和 struct 是一个东西的两种表现形式。
实际上在runtime中,任何对struct 的操作和获取某些值,如extra_rc,实际上都是通过对uintptr_t bits 做位操作实现的。uintptr_t bits 和 struct 的关系可以看做,uintptr_t bits 向外提供了操作struct 的接口,而struct 本身则说明了uintptr_t bits 中各个二进制位的定义。
理解了uintptr_t bits 和 struct 关系后,则isa_t其实可以看做有两个可能的取值,Class cls或struct。如下图所示:
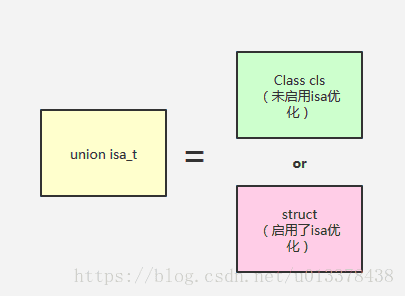
当isa_t作为Class cls使用时,这符合了我们之前一贯的认知:isa是一个指向对象所属Class类型的指针。然而,仅让一个64位的指针表示一个类型,显然不划算。
因此,绝大多数情况下,苹果采用了优化的isa策略,即,isa_t类型并不等同而Class cls, 而是struct。这种情况对于我们自己创建的类对象以及系统对象都是如此,稍后我们会对这一结论进行验证。
先让我们集中精力来看一下struct的结构 :
# if __arm64__
# define ISA_MASK 0x0000000ffffffff8ULL
# define ISA_MAGIC_MASK 0x000003f000000001ULL
# define ISA_MAGIC_VALUE 0x000001a000000001ULL
struct {
uintptr_t nonpointer : 1;
uintptr_t has_assoc : 1;
uintptr_t has_cxx_dtor : 1;
uintptr_t shiftcls : 33; // MACH_VM_MAX_ADDRESS 0x1000000000
uintptr_t magic : 6;
uintptr_t weakly_referenced : 1;
uintptr_t deallocating : 1;
uintptr_t has_sidetable_rc : 1;
uintptr_t extra_rc : 19;
# define RC_ONE (1ULL<<45)
# define RC_HALF (1ULL<<18)
};struct共占用64位,从低位到高位依次是nonpointer到extra_rc。成员后面的:表明了该成员占用几个bit。成员的含义如下:
| 成员 | 位 | 含义 |
|---|---|---|
| nonpointer | 1bit | 标志位。1(奇数)表示开启了isa优化,0(偶数)表示没有启用isa优化。所以,我们可以通过判断isa是否为奇数来判断对象是否启用了isa优化。 |
| has_assoc | 1bit | 标志位。表明对象是否有关联对象。没有关联对象的对象释放的更快。 |
| has_cxx_dtor | 1bit | 标志位。表明对象是否有C++或ARC析构函数。没有析构函数的对象释放的更快。 |
| shiftcls | 33bit | 类指针的非零位。 |
| magic | 6bit | 固定为0x1a,用于在调试时区分对象是否已经初始化。 |
| weakly_referenced | 1bit | 标志位。用于表示该对象是否被别的对象弱引用。没有被弱引用的对象释放的更快。 |
| deallocating | 1bit | 标志位。用于表示该对象是否正在被释放。 |
| has_sidetable_rc | 1bit | 标志位。用于标识是否当前的引用计数过大,无法在isa中存储,而需要借用sidetable来存储。(这种情况大多不会发生) |
| extra_rc | 19bit | 对象的引用计数减1。比如,一个object对象的引用计数为7,则此时extra_rc的值为6。 |
由上表可以看出,和对象引用计数相关的有两个成员:extra_rc和has_sidetable_rc。iOS用19位的extra_rc来记录对象的引用次数,当extra_rc 不够用时,还会借助sidetable来存储计数值,这时,has_sidetable_rc会被标志为1。
我们可以算一下,对于19位的extra_rc ,其数值可以表示2^19 - 1 = 524287。 52万多,相信绝大多数情况下,都够用了。
现在,我们来真正的验证一下,我们上述的结论。注意,做验证试验时,必须要使用真机,因为模拟器默认是不开启isa优化的。
要做验证试验,我们必须要得到isa_t的值。在苹果提供的公共接口中,是无法获取到它的。不过,通过对象指针,我们确实是可以获取到isa_t 的值。
让我们看一下当我们创建一个对象时,实际上是获得到了什么。
NSObject *obj = [[NSObject alloc] init];我们得到了obj这个对象,实质上obj是一个指向对象的指针, 即
obj == NSObject *。
而在NSObject中,又有唯一的成员Class isa, 而Class实质上是objc_class *。这样,我们可以用objc_class * 替换掉 NSObject,得到
obj == objc_class **
再看objc_class的定义:
struct objc_class : objc_object {
。。。
}objc_class 继承自objc_object, 因此,在objc_class 内存布局的首地址肯定存放的是继承自objc_object的内容。从内存布局的角度,我们可以将objc_class 替换为 objc_object 。得到:
obj == objc_object **
而objc_object 的定义如下,仅含有一个成员isa_t :
struct objc_object {
private:
isa_t isa;
}因此,我们又可以将objc_object 替换为isa_t。得到:
obj == isa_t **
好了,这里到了关键的地方,从现在看,我们得到的obj应该是一个指向 isa_t * 的指针,即 obj是一个指针的指针,obj指向一个指针。 但是,obj真的是指向了一个指针吗?
我们再来看一下isa_t的定义,我们看标志为注意!!!的地方:
# if __arm64__
# define ISA_MASK 0x0000000ffffffff8ULL
# define ISA_MAGIC_MASK 0x000003f000000001ULL
# define ISA_MAGIC_VALUE 0x000001a000000001ULL
struct {
uintptr_t nonpointer : 1; // 注意!!! 标志位,表明isa_t *是否是一个真正的指针!!!
uintptr_t has_assoc : 1;
uintptr_t has_cxx_dtor : 1;
uintptr_t shiftcls : 33; // MACH_VM_MAX_ADDRESS 0x1000000000
uintptr_t magic : 6;
uintptr_t weakly_referenced : 1;
uintptr_t deallocating : 1;
uintptr_t has_sidetable_rc : 1;
uintptr_t extra_rc : 19;
# define RC_ONE (1ULL<<45)
# define RC_HALF (1ULL<<18)
};也就是说,当开启了isa_t优化,nonpointer 置位为1, 这时,isa_t *其实不是一个地址,而是一个实实在在有意义的值,也就是说,苹果用isa_t * 所占用的64位空间,表示了一个有意义的值,而这64位值的定义,就符合我们上面struct的定义。
这时,我们可以将isa_t *改写为isa_t,这是因为isa_t *的64位并没有指向任何地址,而是实际表示了isa_t的内容。
继续上面的公式推导,得到结论:
obj == *isa_t哈哈,有意思吗?obj实际上是指向isa_t的指针。绕了这里大一圈,结论竟如此直白。
如果我们想得到isa_t的值,只需要做*obj操作即可,即
NSLog(@"isa_t = %p", *obj);之所以用%p输出,是因为我们要isa_t*本身的值,而不是要取它指向的值。
得出了这个结论,我们就可以通过obj打印出isa_t中存储的内容了(中间需要做几次类型转换,但是实质和上面是一样的):
NSLog(@"isa_t = %p", *(void **)(__bridge void*)obj);我们的实验代码如下:
@interface MyObj : NSObject
@end
@implementation MyObj
@end
@interface ViewController ()
@property(nonatomic, strong) MyObj *obj1;
@property(nonatomic, strong) MyObj *obj2;
@property(nonatomic, weak) MyObj *weakRefObj;
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
MyObj *obj = [[MyObj alloc] init];
NSLog(@"1. obj isa_t = %p", *(void **)(__bridge void*)obj);
_obj1 = obj;
MyObj *tmpObj = obj;
NSLog(@"2. obj isa_t = %p", *(void **)(__bridge void*)obj);
}
- (void)viewDidAppear:(BOOL)animated {
[super viewDidAppear:animated];
NSLog(@"3. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
_obj2 = _obj1;
NSLog(@"4. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
_weakRefObj = _obj1;
NSLog(@"5. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
NSObject *attachObj = [[NSObject alloc] init];
objc_setAssociatedObject(_obj1, "attachKey", attachObj, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
NSLog(@"6. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
}
@end其输出为:
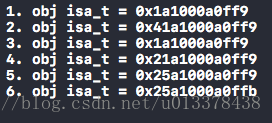
直观的可以看到isa_t的内容都是奇数,说明开启了isa优化。(nonpointer == 1)
接下来我们一行行的分析代码以及相应的isa_t内容变化:
首先在viewDidLoad方法中,我们创建了一个MyObj实例,并接着打印出isa_t的内容,这时候,MyObj的引用计数应该是1:
- (void)viewDidLoad {
...
MyObj *obj = [[MyObj alloc] init];
NSLog(@"1. obj isa_t = %p", *(void **)(__bridge void*)obj);
...
}对应的输出内容为0x1a1000a0ff9:
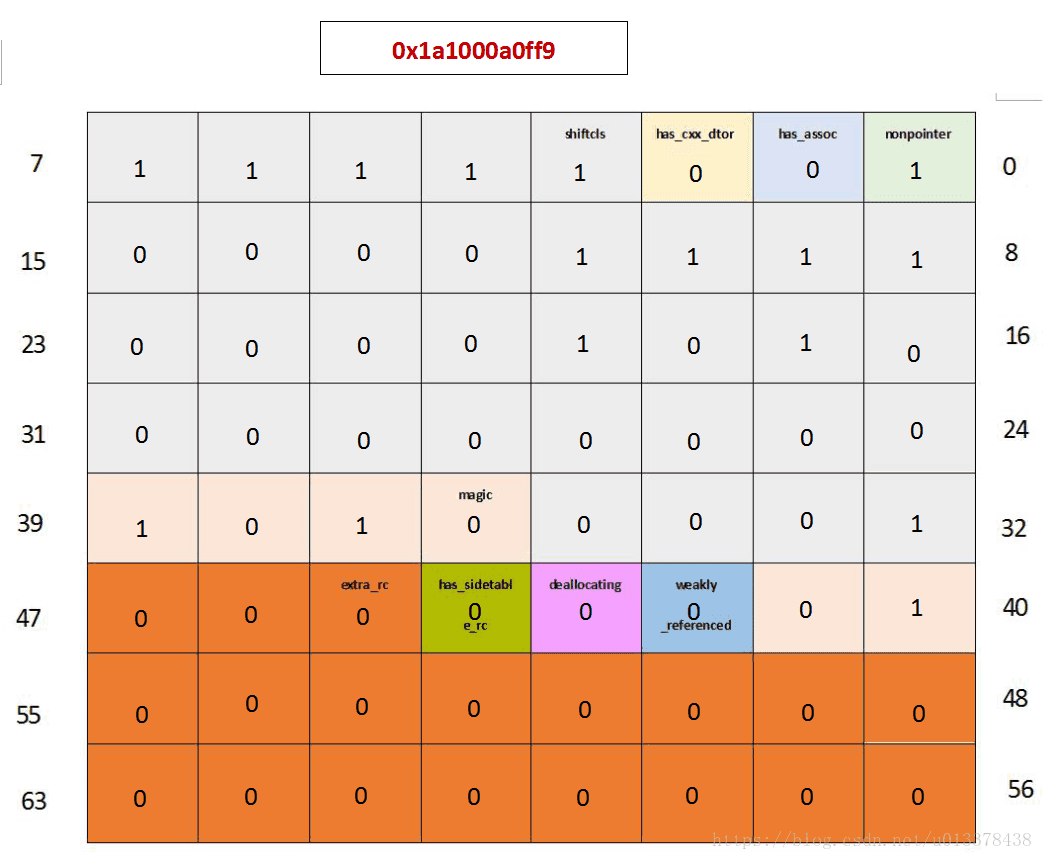
大家可以在图中直观的看到isa_t此时各位的内容,注意到extra_rc此时为0,因为引用计数等于extra_rc + 1,因此,MyObj对象的引用计数为1,和我们的预期一致。
接下来执行
_obj1 = obj;
MyObj *tmpObj = obj;
NSLog(@"2. obj isa_t = %p", *(void **)(__bridge void*)obj);由于_obj1对MyObj对象是强引用,同时,tmpObj的赋值也默认是强引用,obj的引用计数加2,应该等于3。
输出为0x41a1000a0ff9 :
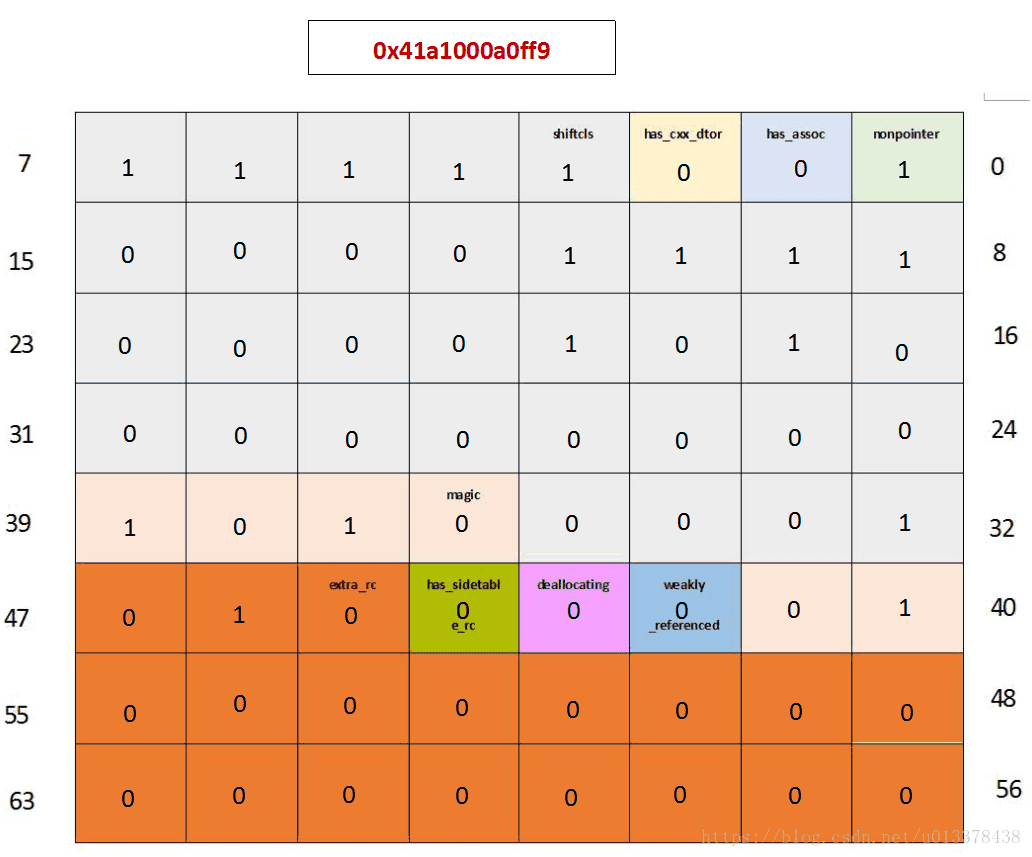
引用计数等于extra_rc + 1 = 2 + 1 = 3, 符合预期。
然后,程序执行到了viewDidAppear方法,并立刻输出MyObj对象的引用计数。因为此时栈上变量obj ,tmpObj已经释放,因此引用计数应该减2,等于1。
- (void)viewDidAppear:(BOOL)animated {
[super viewDidAppear:animated];
NSLog(@"3. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
...
}输出为 0x1a1000a0ff9:
引用计数等于extra_rc + 1 = 0 + 1 = 1, 符合预期。
接下来我们又赋值了一个强引用_obj2, 引用计数加1,等于2。
...
_obj2 = _obj1;
NSLog(@"4. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
...输出为0x21a1000a0ff9 :
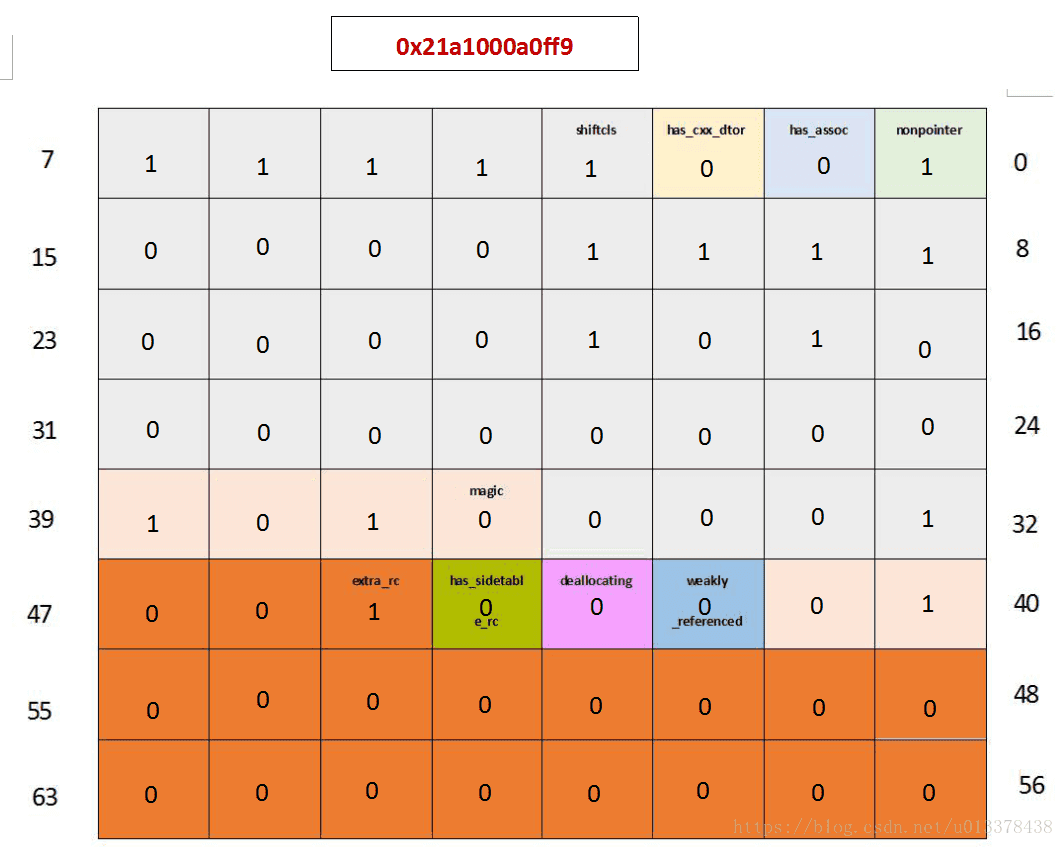
引用计数等于extra_rc + 1 = 1 + 1 = 2, 符合预期。
接下来,我们又将MyObj对象赋值给一个weak引用,此时,引用计数应该保持不变,但是weakly_referenced位应该置1。
...
_weakRefObj = _obj1;
NSLog(@"5. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
...输出0x25a1000a0ff9:
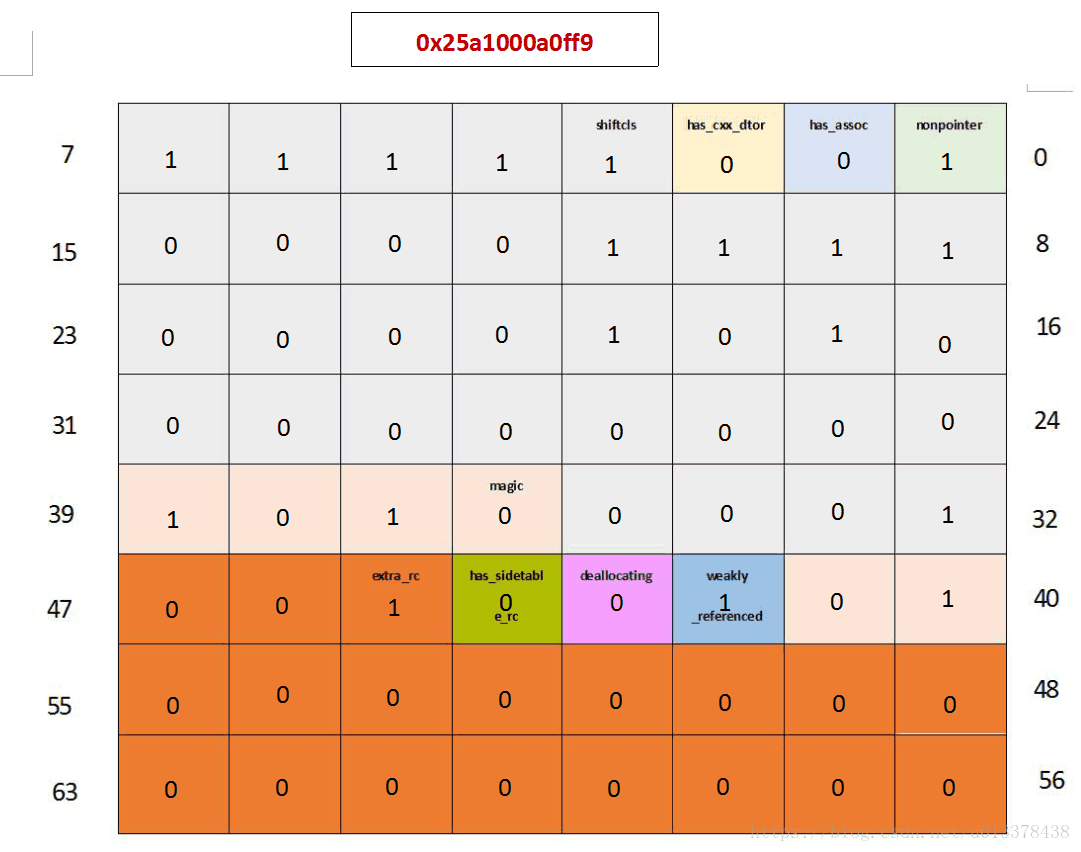
可以看到引用计数仍是2,但是weakly_referenced位已经置位1,符合预期。
最后,我们向MyObj对象 添加了一个关联对象,此时,isa_t的其他位应该保持不变,只有has_assoc标志位应该置位1。
...
NSObject *attachObj = [[NSObject alloc] init];
objc_setAssociatedObject(_obj1, "attachKey", attachObj, OBJC_ASSOCIATION_RETAIN_NONATOMIC);
NSLog(@"6. obj isa_t = %p", *(void **)(__bridge void*)_obj1);
...输出0x25a1000a0ffb:
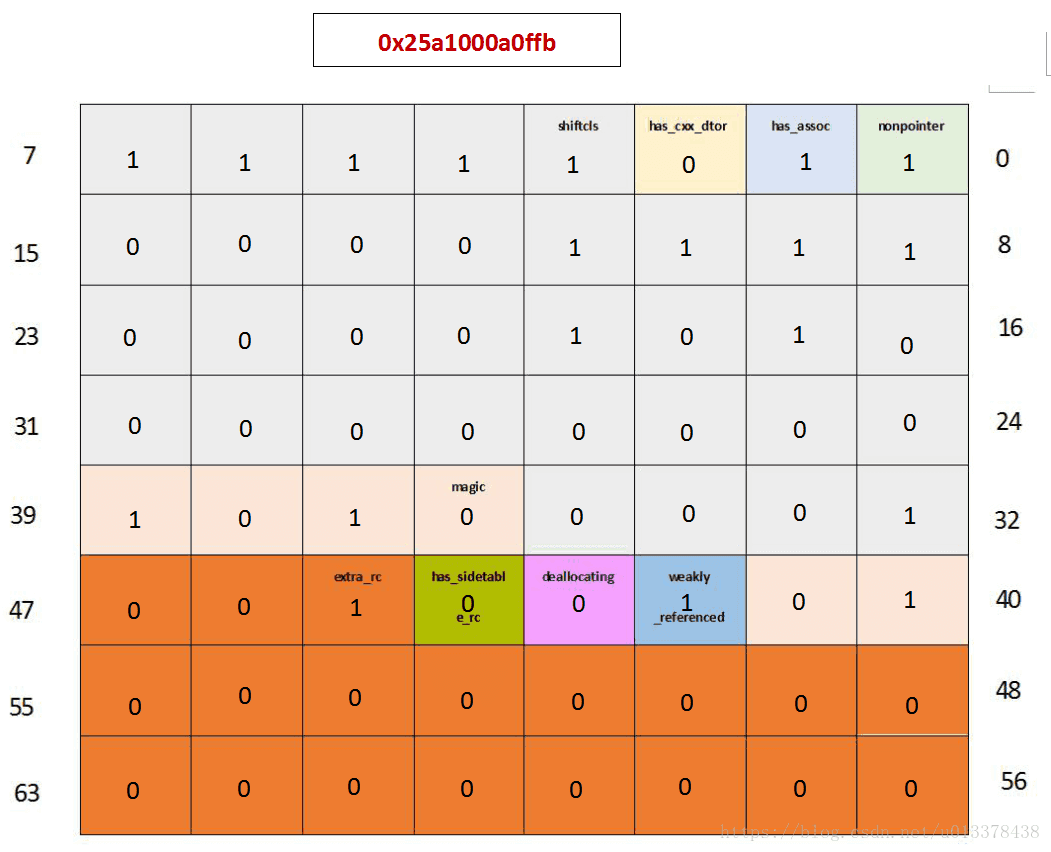
可以看到,其他位保持不变,只有has_assoc被设置为1,符合预期。
OK,通过上面的分析,你现在应该很清楚rumtime里面isa究竟是怎么回事了吧?
PS: 笔者所实验的环境为iPhone5s + iOS 10。
SideTable
其实在绝大多数情况下,仅用优化的isa_t来记录对象的引用计数就足够了。只有在19位的extra_rc盛放不了那么大的引用计数时,才会借助SideTable出马。
SideTable是一个全局的引用计数表,它记录了所有对象的引用计数。
为了弄清extra_rc和sidetable的关系,我们首先看runtime添加对象引用计数时的简化代码。不过在看代码之前,我们需要弄清楚slowpath和fastpath是干啥的。
我们在runtime源码中有时候,有时在if语句中会看到类似下面这些代码:
if (fastpath(cls->canAllocFast())){
...
}
if (slowpath(!newisa.nonpointer)) {
...
}
其实将fastpath和slowpath去掉是完全不影响任何功能的。之所以将fastpath和slowpath 放到if语句中,是为了告诉编译器,if中的条件是大概率(fastpath)还是小概率(slowpath)事件,从而让编译器对代码进行优化。知道了这些,我们就可以来继续看源码了:
# define RC_HALF (1ULL<<18)
ALWAYS_INLINE id
objc_object::rootRetain(bool tryRetain, bool handleOverflow)
{
// 如果是tagged pointer,直接返回this,因为tagged pointer不用记录引用次数
if (isTaggedPointer()) return (id)this;
// transcribeToSideTable用于表示extra_rc是否溢出,默认为false
bool transcribeToSideTable = false;
isa_t oldisa;
isa_t newisa;
do {
transcribeToSideTable = false;
oldisa = LoadExclusive(&isa.bits); // 将isa_t提取出来
newisa = oldisa;
if (slowpath(!newisa.nonpointer)) { // 如果没有采用isa优化, 则返回sidetable记录的内容, 此处slowpath表明这不是一个大概率事件
return sidetable_retain();
}
// 如果对象正在析构,则直接返回nil
if (slowpath(tryRetain && newisa.deallocating)) {
return nil;
}
// 采用了isa优化,做extra_rc++,同时检查是否extra_rc溢出,若溢出,则extra_rc减半,并将另一半转存至sidetable
uintptr_t carry;
newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry); // extra_rc++
if (slowpath(carry)) { // 有carry值,表示extra_rc 溢出
// newisa.extra_rc++ overflowed
if (!handleOverflow) { // 如果不处理溢出情况,则在这里会递归调用一次,再进来的时候,handleOverflow会被rootRetain_overflow设置为true,从而进入到下面的溢出处理流程
return rootRetain_overflow(tryRetain);
}
// 进行溢出处理:逻辑很简单,先在extra_rc中引用计数减半,同时把has_sidetable_rc设置为true,表明借用了sidetable。然后把另一半放到sidetable中
sideTableLocked = true;
transcribeToSideTable = true;
newisa.extra_rc = RC_HALF;
newisa.has_sidetable_rc = true;
}
} while (slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits))); // 将oldisa 替换为 newisa,并赋值给isa.bits(更新isa_t), 如果不成功,do while再试一遍
//isa的extra_rc溢出,将一半的refer count值放到sidetable中
if (slowpath(transcribeToSideTable)) {
// Copy the other half of the retain counts to the side table.
sidetable_addExtraRC_nolock(RC_HALF);
}
return (id)this;
}
添加对象引用计数的源码逻辑还算清晰,重点看当extra_rc溢出后,runtime是怎么处理的。
在iOS中,extra_rc占有19位,也就是最大能够表示2^19-1, 用二进制表示就是19个1。当extra_rc等于2^19时,溢出,此时的二进制位是一个1后面跟19个0, 即10000…00。将会溢出的值2^19除以2,相当于将10000…00向右移动一位。也就等于RC_HALF(1ULL<<18),即一个1后面跟18个0。
然后,调用
sidetable_addExtraRC_nolock(RC_HALF);将另一半的引用计数RC_HALF放到sidetable中。
SideTable数据结构
在runtime中,通过SideTable来管理对象的引用计数以及weak引用。这里要注意,一张SideTable会管理多个对象,而并非一个。
而这一个个的SideTable又构成了一个集合,叫SideTables。SideTables在系统中是全局唯一的。
SideTable,SideTables的关系如下图所示(这张图会随着分析的深入逐渐扩充):
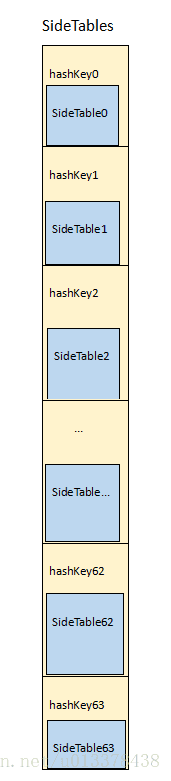
SideTables的类型是是template<typename T> class StripedMap,StripedMap<SideTable> 。我们可以简单的理解为一个64 * sizeof(SideTable) 的哈希线性数组。
每个对象可以通过StripedMap所对应的哈希算法,找到其对应的SideTable。StripedMap 的哈希算法如下,其参数是对象的地址。
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast<uintptr_t>(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount; // 这里 %StripeCount 保证了所有的对象对应的SideTable均在这个64长度数组中。
}注意到这个SideTables哈希数组是全局的,因此,对于我们APP中所有的对象的引用计数,也就都存在于这64个SideTable中。
具体到每个SideTable, 其中有存储了若干对象的引用计数。SideTable 的定义如下:
struct SideTable {
spinlock_t slock;
RefcountMap refcnts;
weak_table_t weak_table;
SideTable() {
memset(&weak_table, 0, sizeof(weak_table));
}
~SideTable() {
_objc_fatal("Do not delete SideTable.");
}
};SideTable包含三个成员:
spinlock_t slock:自旋锁。防止多线程访问SideTable冲突RefcountMap refcnts:用于存储对象引用计数的mapweak_table_t weak_table: 用于存储对象弱引用的map
这里我们暂且不去管weak_table, 先看存储对象引用计数的成员RefcountMap refcnts。
RefcountMap类型实际是DenseMap,这是一个模板类。
typedef objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap;关于DenseMap的实际定义,有点复杂,暂时不想看:(
这里只需要将RefcountMap简单的的理解为是一个map,key是DisguisedPtr<objc_object>,value是对象的引用计数。同时,这个map还有个加强版功能,当引用计数为0时,会自动将对象数据清除。
这也是
objc::DenseMap<DisguisedPtr<objc_object>,size_t,true> RefcountMap的含义,即模板类型分别对应:
key,DisguisedPtr类型。
value,size_t类型。
是否清除为vlaue==0的数据,true。
DisguisedPtr中的采样方法是:
static uintptr_t disguise(T* ptr) {
return -(uintptr_t)ptr;
}
// 将T按照模板替换为objc_object,即是:
static uintptr_t disguise(objc_object* ptr) {
return -(uintptr_t)ptr;
}所以,对象引用计数map RefcountMap的key是:-(object *),就是对象地址取负。value就是该对象的引用计数。
我们来看一下OC是如何获取对象引用计数的:
inline uintptr_t
objc_object::rootRetainCount()
{
//case 1: 如果是tagged pointer,则直接返回this,因为tagged pointer是不需要引用计数的
if (isTaggedPointer()) return (uintptr_t)this;
// 将objcet对应的sidetable上锁
sidetable_lock();
isa_t bits = LoadExclusive(&isa.bits);
ClearExclusive(&isa.bits);
// case 2: 如果采用了优化的isa指针
if (bits.nonpointer) {
uintptr_t rc = 1 + bits.extra_rc; // 先读取isa.extra_rc
if (bits.has_sidetable_rc) { // 如果extra_rc不够大, 还需要读取sidetable中的数据
rc += sidetable_getExtraRC_nolock(); // 总引用计数= rc + sidetable count
}
sidetable_unlock();
return rc;
}
// case 3:如果没采用优化的isa指针,则直接返回sidetable中的值
sidetable_unlock(); // 将objcet对应的sidetable解锁,因为sidetable_retainCount()中会上锁
return sidetable_retainCount();
}可以看到,runtime在获取对象引用计数的时候,是考虑了三种情况:(1)tagged pointer, (2)优化的isa, (3)未优化的isa。
我们来看一下(2)优化的isa 的情况下:
首先,会读取extra_rc中的数据,因为extra_rc中存储的是引用计数减一,所以这里要加回去。
如果extra_rc 不够大的话,还需要读取sidetable,调用sidetable_getExtraRC_nolock:
#define SIDE_TABLE_RC_SHIFT 2
size_t
objc_object::sidetable_getExtraRC_nolock()
{
assert(isa.nonpointer);
SideTable& table = SideTables()[this];
RefcountMap::iterator it = table.refcnts.find(this);
if (it == table.refcnts.end()) return 0;
else return it->second >> SIDE_TABLE_RC_SHIFT;
}注意,这里在返回引用计数前,还做了个右移2位的位操作it->second >> SIDE_TABLE_RC_SHIFT。这是因为在sidetable中,引用计数的低2位不是用来记录引用次数的,而是分别表示对象是否有弱引用计数,以及是否在deallocing,这估计是为了兼容未优化的isa而设计的:
#define SIDE_TABLE_WEAKLY_REFERENCED (1UL<<0)
#define SIDE_TABLE_DEALLOCATING (1UL<<1) // MSB-ward of weak bit所以,在sidetable中做加引用加一操作时,需要在第3位上+1:
#define SIDE_TABLE_RC_ONE (1UL<<2) // MSB-ward of deallocating bit
refcntStorage += SIDE_TABLE_RC_ONE;这里sidetable的引用计数值还有一个SIDE_TABLE_RC_PINNED 状态,表明这个引用计数太大了,连sidetable都表示不出来:
#define SIDE_TABLE_RC_PINNED (1UL<<(WORD_BITS-1))OK,到此为止,我们就学习完了runtime中所有的引用计数实现方式。接下来我们还会继续看和引用计数相关的两个概念:弱引用和autorelease。
Weekly reference
再来回看一下sidetable 的定义如下:
struct SideTable {
spinlock_t slock; // 自旋锁,防止多线程访问冲突
RefcountMap refcnts; // 对象引用计数map
weak_table_t weak_table; // 对象弱引用map
}spinlock_t slock、RefcountMap refcnts的定义我们已经清楚,下面就来看一下weak_table_t weak_table,它记录了所有弱引用对象的集合。
weak_table_t定义如下:
/**
* The global weak references table. Stores object ids as keys,
* and weak_entry_t structs as their values.
*/
struct weak_table_t {
weak_entry_t *weak_entries; // hash数组,用来存储弱引用对象的相关信息weak_entry_t
size_t num_entries; // hash数组中的元素个数
uintptr_t mask; // hash数组长度-1,会参与hash计算。(注意,这里是hash数组的长度,而不是元素个数。比如,数组长度可能是64,而元素个数仅存了2个)
uintptr_t max_hash_displacement; // 可能会发生的hash冲突的最大次数
};weak_table_t 包含一个weak_entry_t类型的数组,可以通过hash算法找到对应object在数组中的index。这种结构,和sidetables类似,不同的是,weak_table_t是可以动态扩展的,而不是写死的64个。
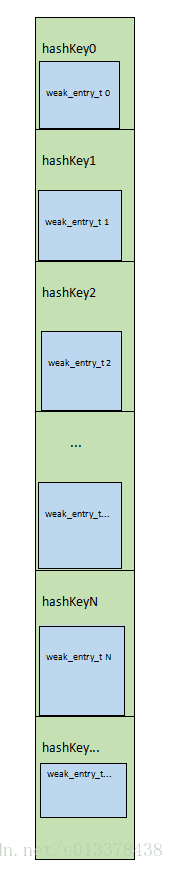
weak_entries实质上是一个hash数组,数组中存储weak_entry_t类型的元素。weak_entry_t的定义如下:
typedef DisguisedPtr<objc_object *> weak_referrer_t;
#define PTR_MINUS_2 62
/**
* The internal structure stored in the weak references table.
* It maintains and stores
* a hash set of weak references pointing to an object.
* If out_of_line_ness != REFERRERS_OUT_OF_LINE then the set
* is instead a small inline array.
*/
#define WEAK_INLINE_COUNT 4
// out_of_line_ness field overlaps with the low two bits of inline_referrers[1].
// inline_referrers[1] is a DisguisedPtr of a pointer-aligned address.
// The low two bits of a pointer-aligned DisguisedPtr will always be 0b00
// (disguised nil or 0x80..00) or 0b11 (any other address).
// Therefore out_of_line_ness == 0b10 is used to mark the out-of-line state.
#define REFERRERS_OUT_OF_LINE 2
struct weak_entry_t {
DisguisedPtr<objc_object> referent; // 被弱引用的对象
// 引用该对象的对象列表,联合。 引用个数小于4,用inline_referrers数组。 用个数大于4,用动态数组weak_referrer_t *referrers
union {
struct {
weak_referrer_t *referrers; // 弱引用该对象的对象列表的动态数组
uintptr_t out_of_line_ness : 2; // 是否使用动态数组标记位
uintptr_t num_refs : PTR_MINUS_2; // 动态数组中元素的个数
uintptr_t mask; // 用于hash确定动态数组index,值实际上是动态数组空间长度-1(它和num_refs不一样,这里是记录的是数组中位置的个数,而不是数组中实际存储的元素个数)。
uintptr_t max_hash_displacement; // 最大的hash冲突次数(说明了最多做max_hash_displacement次hash冲突,肯定会找到对应的数据)
};
struct {
// out_of_line_ness field is low bits of inline_referrers[1]
weak_referrer_t inline_referrers[WEAK_INLINE_COUNT];
};
};
bool out_of_line() {
return (out_of_line_ness == REFERRERS_OUT_OF_LINE);
}
weak_entry_t& operator=(const weak_entry_t& other) {
memcpy(this, &other, sizeof(other));
return *this;
}
weak_entry_t(objc_object *newReferent, objc_object **newReferrer)
: referent(newReferent)
{
inline_referrers[0] = newReferrer;
for (int i = 1; i < WEAK_INLINE_COUNT; i++) {
inline_referrers[i] = nil;
}
}
};
根据注释,DisguisedPtr方法返回的hash值得最低2个字节应该是0b00或0b11,因此可以用out_of_line_ness == 0b10来表明当前是否在使用数组或动态数组来保存引用该对象的列表。
这样,sidetable中的weak_table_t weak_table成员的结构如下所示:

回头再来看一下,会发现在weak talbe中存在两个hash 表。
一个是weak_table_t 自身。它可以通过对象地址做hash(hash_pointer(objc_object *) & weak_table->mask),直接找到weak_entries中该对象对应的weak_entry_t。
另一个是weak_entry_t中的weak_referrer_t *referrers。它可以通过弱引用该对象的对象指针的指针做hash(w_hash_pointer(objc_object **) & (entry->mask)),直接找到对象指针的指针在referrers中对应的weak_referrer_t *。
虽然weak_table_t和referrers 是表示意义不同的hash表,但他们的实现以是一样的,可以看做是同一种hash表。而且还设计的很有技巧。下面,我们就来详细学习一下hash 表示怎么实现的。
weak table的实现细节
由于weak_entries和referrers中的实现类似,这里我们就以weak_table_t为例,来分析hash表的实现。
weak_table_t定义如下:
/**
* The global weak references table. Stores object ids as keys,
* and weak_entry_t structs as their values.
*/
struct weak_table_t {
weak_entry_t *weak_entries; // hash数组,用来存储弱引用对象的相关信息weak_entry_t
size_t num_entries; // hash数组中的元素个数
uintptr_t mask; // hash数组长度-1,用于和hash值做位与计算,来确定数组下标。(注意,这里是hash数组的长度,而不是元素个数。比如,数组长度可能是64,而元素个数仅存了2个)
uintptr_t max_hash_displacement; // 可能会发生的hash冲突的最大次数
};hash定位
当向weak_table_t 中插入或查找某个元素时,是通过如下hash算法的(以查找为例):
static weak_entry_t *
weak_entry_for_referent(weak_table_t *weak_table, objc_object *referent)
{
assert(referent);
weak_entry_t *weak_entries = weak_table->weak_entries;
if (!weak_entries) return nil;
size_t begin = hash_pointer(referent) & weak_table->mask;
size_t index = begin;
size_t hash_displacement = 0;
while (weak_table->weak_entries[index].referent != referent) {
index = (index+1) & weak_table->mask;
if (index == begin) bad_weak_table(weak_table->weak_entries); // 触发bad weak table crash
hash_displacement++;
if (hash_displacement > weak_table->max_hash_displacement) {
return nil;
}
}
return &weak_table->weak_entries[index];
}首先,确定hash值可能对应的数组下标begin:
size_t begin = hash_pointer(referent) & weak_table->mask;hash_pointer(referent)将会对referent进行hash操作:
static inline uint32_t ptr_hash(uint64_t key)
{
key ^= key >> 4;
key *= 0x8a970be7488fda55;
key ^= __builtin_bswap64(key);
return (uint32_t)key;
}这个算法不用深究,知道就是一个hash操作就好了。
有技巧的是后半部分& weak_table->mask,将hash值和mask做位与运算。
之前说过,mask 的值等于数组长度-1。而在下面的小节你会了解到,hash数组的长度会以64,128,256规律递增。总之,数组长度表现为二进制会是1000...0这种形式,即首位1,后面跟n个0。而这个值减1的话,则会变为011...1这种形式,即首位0,后面跟n个1,这即mask的二进制形式。那么用mask & hash_pointer(referent)时,就会保留hash_pointer(referent)的后n位的值,而首位被位与操作置为了0。那么这个值肯定是小于首位是1的数值的,也就是肯定会小于数组的长度。
因此,
begin是一个小于数组长度的一个数组下标,且这个下标对应着目标元素的hash值。
确定了初始的数组下标后,就开始尝试确定元素的真正位置:
while (weak_table->weak_entries[index].referent != referent) {
index = (index+1) & weak_table->mask; // hash冲突,做index+1,尝试下一个相邻位置,& weak_table->mask 确保了index不会越界,而且会使index自动find数组一圈
if (index == begin) bad_weak_table(weak_table->weak_entries); // 在数组中转了一圈还没找到目标元素,触发bad weak table crash
hash_displacement++;
if (hash_displacement > weak_table->max_hash_displacement) { // 如果hash冲突大于了最大可能的冲突次数,则说明目标对象不存在于数组中,返回nil
return nil;
}
}这里,产生了hash冲突后,系统会依次线性循环寻找目标对象的位置。直到找了一圈又回到了起点或大于了可能的hash冲突值。这个max_hash_displacement值是在每个元素插入的时候更新的,它总是记录在插入时,所发生的hash冲突的最大值。因此在查找时,hash冲突的次数肯定不会大于这个值。
这里最巧妙的是这条语句:
index = (index+1) & weak_table->mask它即会让你向下一个相邻位置寻找,同时当寻找到最后一个位置时,它又会自动让你从数组的第一个位置开始寻找。这一切,都归功于二进制运算的巧妙运用。
hash表自动扩容
这里的weak table的大小是不固定的。当插入新元素时,会调用weak_grow_maybe方法,来判断是否要做hash表的扩容。该方法实现如下:
#define TABLE_SIZE(entry) (entry->mask ? entry->mask + 1 : 0)
// Grow the given zone's table of weak references if it is full.
static void weak_grow_maybe(weak_table_t *weak_table)
{
size_t old_size = TABLE_SIZE(weak_table);
// Grow if at least 3/4 full.
if (weak_table->num_entries >= old_size * 3 / 4) { // 当大于现有长度的3/4时,会做数组扩容操作。
weak_resize(weak_table, old_size ? old_size*2 : 64); // 初次会分配64个位置,之后在原有基础上*2
}
}这里的扩容会调用weak_resize方法。每次扩容都会是原有长度的一倍。这样,每次扩容的新增空间都会比上一次要大一倍,而不是固定的扩容n个空间。这么做的目的在于,系统认为,当你有扩容需求时,之后又扩容需求的概率就会变大,为了防止频繁的申请内存,所以,每次扩容强度都会比上一次要大。
hash表自动收缩
当从weak table中删除元素时,系统会调用weak_compact_maybe判断是否需要收缩hash数组的空间 :
// Shrink the table if it is mostly empty.
static void weak_compact_maybe(weak_table_t *weak_table)
{
size_t old_size = TABLE_SIZE(weak_table);
// Shrink if larger than 1024 buckets and at most 1/16 full.
if (old_size >= 1024 && old_size / 16 >= weak_table->num_entries) { // 当前数组长度大于1024,且实际使用空间最多只有1/16时,需要做收缩操作
weak_resize(weak_table, old_size / 8); // 缩小8倍
// leaves new table no more than 1/2 full
}
}hash表resize
无论是扩容还是收缩,最终都会调用到weak_resize方法:
static void weak_resize(weak_table_t *weak_table, size_t new_size)
{
size_t old_size = TABLE_SIZE(weak_table);
weak_entry_t *old_entries = weak_table->weak_entries; // 先把老数据取出来
weak_entry_t *new_entries = (weak_entry_t *) // 在为新的size申请内存
calloc(new_size, sizeof(weak_entry_t));
// 重置weak_table的各成员
weak_table->mask = new_size - 1;
weak_table->weak_entries = new_entries;
weak_table->max_hash_displacement = 0;
weak_table->num_entries = 0; // restored by weak_entry_insert below
if (old_entries) {
weak_entry_t *entry;
weak_entry_t *end = old_entries + old_size;
for (entry = old_entries; entry < end; entry++) {
if (entry->referent) { // 依次将老的数据插入到新的内存空间
weak_entry_insert(weak_table, entry);
}
}
free(old_entries); // 释放老的内存空间
}
}
/**
* Add new_entry to the object's table of weak references.
* Does not check whether the referent is already in the table.
*/
static void weak_entry_insert(weak_table_t *weak_table, weak_entry_t *new_entry)
{
weak_entry_t *weak_entries = weak_table->weak_entries;
assert(weak_entries != nil);
size_t begin = hash_pointer(new_entry->referent) & (weak_table->mask);
size_t index = begin;
size_t hash_displacement = 0;
while (weak_entries[index].referent != nil) {
index = (index+1) & weak_table->mask;
if (index == begin) bad_weak_table(weak_entries);
hash_displacement++;
}
weak_entries[index] = *new_entry;
weak_table->num_entries++;
if (hash_displacement > weak_table->max_hash_displacement) { // 这里记录最大的hash冲突次数,当查找元素时,hash冲突肯定不会大于这个值
weak_table->max_hash_displacement = hash_displacement;
}
}
OK, 上面就是对runtime中weak引用的相关数据结构的分析。关于weak引用数据,是存在于hash表中的。
这关于hash算法映射到数组下标,以及hash表动态的扩容/收缩,还是很有意思的。
autoreleasepool
在iOS中,除了需要手动retain,release(现在已经交给了ARC自动生成)外,我们还可以将对象扔到自动释放池中,由自动释放池来自动管理这些对象。我们可以这样使用autoreleasepool:
int main(int argc, char * argv[]) {
@autoreleasepool {
NSString *a = [NSString stringWithFormat:@"%d", 1];
}
}用clang -rewrite-objc 重写后,得到:
int main(int argc, char * argv[]) {
/* @autoreleasepool */ { __AtAutoreleasePool __autoreleasepool;
NSString *a = ((NSString * _Nonnull (*)(id, SEL, NSString * _Nonnull, ...))(void *)objc_msgSend)((id)objc_getClass("NSString"), sel_registerName("stringWithFormat:"), (NSString *)&__NSConstantStringImpl__var_folders_8k_3pbszhls2czcmz0w335cvc0w0000gn_T_main_1a8fc0_mi_1, 1);
}
}这时会发现, @autoreleasepool 被改写为了 __AtAutoreleasePool __autoreleasepool这样一个对象。__AtAutoreleasePool的定义为:
struct __AtAutoreleasePool {
__AtAutoreleasePool() {atautoreleasepoolobj = objc_autoreleasePoolPush();}
~__AtAutoreleasePool() {objc_autoreleasePoolPop(atautoreleasepoolobj);}
void * atautoreleasepoolobj;
};于是,关于@autoreleasepool的代码可以被改写为:
objc_autoreleasePoolPush();
// Do your code
objc_autoreleasePoolPop(atautoreleasepoolobj);置于@autoreleasepool的{}中的代码实际上是被一个push和pop操作所包裹。当push时,会压栈一个autoreleasepage,在{}中的所有的autorelease对象都会放到这个page中。当pop时,会出栈一个autoreleasepage,同时,所有存储于这个page的对象都会做release操作。这就是autoreleasepool的实现原理。
objc_autoreleasePoolPush()和objc_autoreleasePoolPop(atautoreleasepoolobj)的实现如下:
void *
objc_autoreleasePoolPush(void)
{
return AutoreleasePoolPage::push();
}
void
objc_autoreleasePoolPop(void *ctxt)
{
AutoreleasePoolPage::pop(ctxt);
}
它们都分别调用了AutoreleasePoolPage类的静态方法push和pop。AutoreleasePoolPage 是runtime中autoreleasepool的核心实现,下面,我们就来了解一下它。
AutoreleasePoolPage
AutoreleasePoolPage在runtime中的定义如下:
class AutoreleasePoolPage
{
magic_t const magic; // 魔数,用于自身的完整性校验 16字节
id *next; // 指向autorelePool page中的下一个可用位置 8字节
pthread_t const thread; // 和autorelePool page中相关的线程 8字节
AutoreleasePoolPage * const parent; // autoreleasPool page双向链表的前向指针 8字节
AutoreleasePoolPage *child; // autoreleasPool page双向链表的后向指针 8字节
uint32_t const depth; // 当前autoreleasPool page在双向链表中的位置(深度) 4字节
uint32_t hiwat; // high water mark. 最高水位,可用近似理解为autoreleasPool page双向链表中的元素个数 4字节
// SIZE-sizeof(*this) bytes of contents follow
}每个AutoreleasePoolPage的大小为一个SIZE,即内存管理中一个页的大小。这在Mac中是4KB,而在iOS中,这里没有相关代码,估计差不多。
对象指针栈
由源码可用看出,在AutoreleasePoolPage 类中共有7个成员属性,大小为56Bytes,按照一个Page是4KB计算,显然还有4040Bytes没有用。而这4040Bytes空间,就用来存储AutoreleasePoolPage所管理的对象指针。因此,一个AutoreleasePoolPage的内存布局如下图(摘自Draveness的博客):
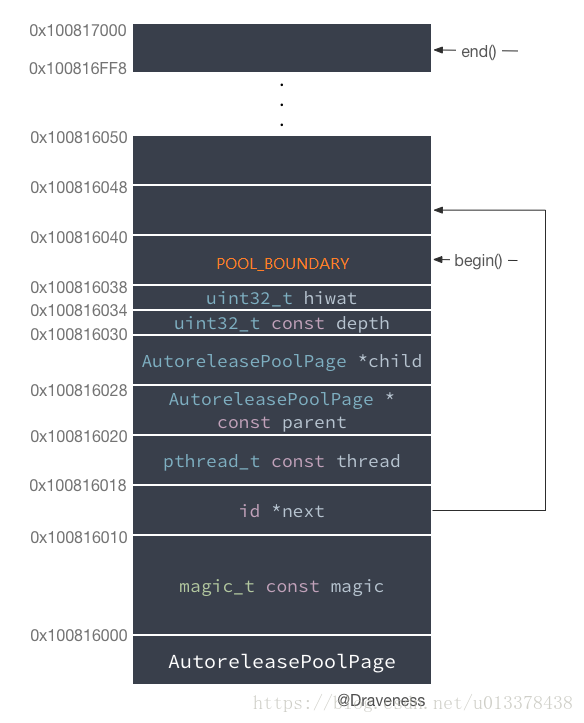
在autoreleasepool中的对象指针是按照栈的形式存储的,栈低是一个POOL_BOUNDARY哨兵,之后对象指针依次入栈存储。
POOL_BOUNDARY
在图中可用看到,除了AutoreleasePoolPage 类中的7个成员之外,还有一个叫POOL_BOUNDARY, 其实这是一个nil指针,AutoreleasePoolPage中的next指针用来指向栈中下一个入栈位置。
# define POOL_BOUNDARY nil它作为一个哨兵,当需要将AutoreleasePoolPage 中存储的对象指针依次出栈时,会执行到POOL_BOUNDARY为止。
双向链表
在图中也可以看出,单个的AutoreleasePoolPage是以栈的形式存储的。
当加入到autoreleasepool中的元素太多时,一个AutoreleasePoolPage 就不够用的了。这时候我们需要新创建一个AutoreleasePoolPage ,多个AutoreleasePoolPage之间通过双向链表的形式串起来。
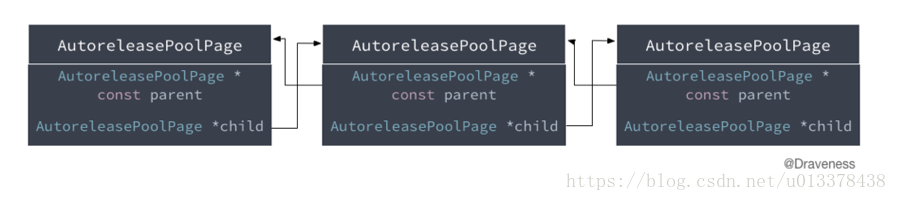
成员parent和child就是用来构造双向链表的。
下面我们就结合具体的代码,来看一下AutoreleasePoolPage是如何在系统中发挥作用的。
Push
当用户调用@autoreleasepool{}的时候,系统首先会调用AutoreleasePoolPage::push()方法,来创建或获取当前的hotPage,并向对象栈中插入一个POOL_BOUNDARY。
static inline void *push()
{
id *dest;
dest = autoreleaseFast(POOL_BOUNDARY);
assert(dest == EMPTY_POOL_PLACEHOLDER || *dest == POOL_BOUNDARY);
return dest;
}我们也可以调用autorelease(id obj)方法将某个特定的对象指针插入到AutoreleasePoolPage中:
static inline id autorelease(id obj)
{
assert(obj);
assert(!obj->isTaggedPointer()); // 注意这个assert,由于tagged pointer不遵循引用计数规则,所以也不会有autorelease操作。
id *dest __unused = autoreleaseFast(obj);
assert(!dest || dest == EMPTY_POOL_PLACEHOLDER || *dest == obj);
return obj;
}可以看到,无论是push还是autorelease方法,最后都是调用了autoreleaseFast(obj),该方法会将一个id放入到autoreleasePage中。:
static inline id *autoreleaseFast(id obj)
{
AutoreleasePoolPage *page = hotPage();
if (page && !page->full()) {
return page->add(obj);
} else if (page) {
return autoreleaseFullPage(obj, page);
} else {
return autoreleaseNoPage(obj);
}
}可以看到方法实现逻辑也很简单:
- 首先取出当前的
hotPage,所谓hotPage,就是在autoreleasePage链表中正在使用的autoreleasePage节点。 - 如果有hotPage,且hotPage还没满,这将obj加入到page中。
- 如果有hotPage,但是已经满了,则进入page full逻辑(
autoreleaseFullPage)。 - 如果没有hotPage,进入no page逻辑
autoreleaseNoPage。
hotPage
hotPage是autoreleasePage链表中正在使用的autoreleasePage节点。实质上是指向autoreleasepage的指针,并存储于线程的TSD(线程私有数据:Thread-specific Data)中:
static inline AutoreleasePoolPage *hotPage()
{
AutoreleasePoolPage *result = (AutoreleasePoolPage *)
tls_get_direct(key);
if ((id *)result == EMPTY_POOL_PLACEHOLDER) return nil;
if (result) result->fastcheck();
return result;
}从这段代码可以看出,
autoreleasepool是和线程绑定的,一个线程对应一个autoreleasepool。而autoreleasepool虽然叫做自动释放池,其实质上是一个双向链表。
在介绍runloop的时候,我们也曾提到过,runloop和线程也是一一对应的,并且在当前线程的runloop指针,也会存储到线程的TSD中。这是runtime对于TSD的一个应用。
add object
如果有hot page,先判断page 是否已经full了,判断逻辑是next*是否等于end():
bool full() {
return next == end();
}关于begin()和end(),定义如下,结合page的图示,应该比较容易理解:
id * begin() {
return (id *) ((uint8_t *)this+sizeof(*this));
}
id * end() {
return (id *) ((uint8_t *)this+SIZE);
}如果page没有满,这调用page的add方法:
id *add(id obj)
{
assert(!full());
id *ret = next; // faster than `return next-1` because of aliasing
*next = obj;
next++;
return ret;
}逻辑比较简单,就是将obj置于next的位置,next++,然后返回obj的位置。
autoreleaseFullPage
如果hot page满了,就需要在链表中‘加页’,同时将新页置为hot page:
static __attribute__((noinline))
id *autoreleaseFullPage(id obj, AutoreleasePoolPage *page)
{
// The hot page is full.
// Step to the next non-full page, adding a new page if necessary.
// Then add the object to that page.
assert(page == hotPage());
assert(page->full() || DebugPoolAllocation);
do {
if (page->child) page = page->child;
else page = new AutoreleasePoolPage(page);
} while (page->full());
setHotPage(page);
return page->add(obj);
}这一段代码重点需要关注的是寻找可用page的do while逻辑。
其实注释中已经写得很清楚,系统会首先尝试在hot page的child pages中挑出第一个没有满的page,如果没有符合要求的child page,则只能创建一个新的new AutoreleasePoolPage(page)。
最后,将挑选出的page作为当前线程的hot page (实际上存储到了TSD中),并将obj存到新的hot page中。
autoreleaseNoPage
若当前线程没有hot Page,则说明当前的线程还未建立起autorelease pool 。这时,就会调用autoreleaseNoPage:
static __attribute__((noinline))
id *autoreleaseNoPage(id obj)
{
// "No page" could mean no pool has been pushed
// or an empty placeholder pool has been pushed and has no contents yet
assert(!hotPage());
bool pushExtraBoundary = false;
if (haveEmptyPoolPlaceholder()) { // 如果当前线程只有一个虚拟的空池,则这次需要真正创建一个page
// We are pushing a second pool over the empty placeholder pool
// or pushing the first object into the empty placeholder pool.
// Before doing that, push a pool boundary on behalf of the pool
// that is currently represented by the empty placeholder.
pushExtraBoundary = true;
}else if (obj == POOL_BOUNDARY && !DebugPoolAllocation) { // 如果obj == POOL_BOUNDARY,这里苹果有个小心机,它不会真正创建page,而是在线程的TSD中做了一个空池的标志
// We are pushing a pool with no pool in place,
// and alloc-per-pool debugging was not requested.
// Install and return the empty pool placeholder.
return setEmptyPoolPlaceholder();
}
// We are pushing an object or a non-placeholder'd pool.
// 创建线程的第一个page,并置为hot page。
AutoreleasePoolPage *page = new AutoreleasePoolPage(nil);
setHotPage(page);
// 如果之前只是做了空池标记,这里还需要在栈中补上POOL_BOUNDARY,作为栈底哨兵
if (pushExtraBoundary) {
page->add(POOL_BOUNDARY);
}
// Push the requested object or pool. 注意,这里的注释,进入page的不光可以有object,还可以是pool。
return page->add(obj);
}当系统发现当前线程没有对应的autoreleasepool时,我们自然的想到需要为线程创建一个page。但是苹果其实在这里是耍了一个小心机的,当在创建第一个page时,苹果并不会真正创建一个page,因为它害怕创建了page后,并没有真正的object需要插入page,这样就造成了无谓的内存浪费。
在没有第一个真正的object入栈之前,苹果是这样做的:仅仅在线程的TSD中做了一个EMPTY_POOL_PLACEHOLDER标记,并返回它。这里没有真正的new 一个AutoreleasePoolPage。
Pop
当autoreleasepool需要被释放时,会调用Pop方法。而Pop方法需要接受一个void *token参数,来告诉池子,需要一直释放到token对应的那个page:
static inline void pop(void *token)
{
AutoreleasePoolPage *page;
id *stop;
if (token == (void*)EMPTY_POOL_PLACEHOLDER) {
// Popping the top-level placeholder pool.
if (hotPage()) {
// Pool was used. Pop its contents normally.
// Pool pages remain allocated for re-use as usual.
pop(coldPage()->begin());
} else {
// Pool was never used. Clear the placeholder.
setHotPage(nil);
}
return;
}
page = pageForPointer(token);
stop = (id *)token;
if (*stop != POOL_BOUNDARY) {
if (stop == page->begin() && !page->parent) {
// Start of coldest page may correctly not be POOL_BOUNDARY:
// 1. top-level pool is popped, leaving the cold page in place
// 2. an object is autoreleased with no pool
} else {
// 这是为了兼容旧的SDK,看来在新的SDK里面,token 可能的取值只有两个:POOL_BOUNDARY, page->begin() && !page->parent
// Error. For bincompat purposes this is not
// fatal in executables built with old SDKs.
return badPop(token);
}
}
// 对page中的object做objc_release操作,一直到stop
page->releaseUntil(stop);
// memory: delete empty children 删除多余的child,节约内存
if (page->child) {
// hysteresis: keep one empty child if page is more than half full
if (page->lessThanHalfFull()) {
page->child->kill();
}
else if (page->child->child) {
page->child->child->kill();
}
}
}何时需要autoreleasePool
OK,以上就是autoreleasepool的内容。那么在ARC的环境下,我们何时需要用@autoreleasepool呢?
一般的,有下面两种情况:
- 创建子线程。当我们创建子线程的时候,需要将子线程的runloop用@autoreleasepool包裹起来,进而达到自动释放内存的效果。因为系统并不会为子线程自动包裹一个@autoreleasepool,这样加入到autoreleasepage中的元素就得不到释放。
- 在大循环中创建autorelease对象。当我们在一个循环中创建autorelease对象(不是用alloc创建的对象),该对象会加入到autoreleasepage中,而这个page中的对象,会等到外部池子结束才会释放。在主线程的runloop中,会将所有的对象的释放权都交给了RunLoop 的释放池,而RunLoop的释放池会等待这个事件处理之后才会释放,因此就会使对象无法及时释放,堆积在内存造成内存泄露。关于这一点,可以参考博客RunLoop和autorelease的一道面试题