深度学习最令人兴奋的领域之一就是计算机视觉。通过卷积神经网络,我们已经能够创建自动驾驶汽车系统、面部检测系统和自动医学图像分析等等。在本文中,我将向你展示卷积神经网络的基本原理以及如何自己创建一个对手写数字进行分类的系统。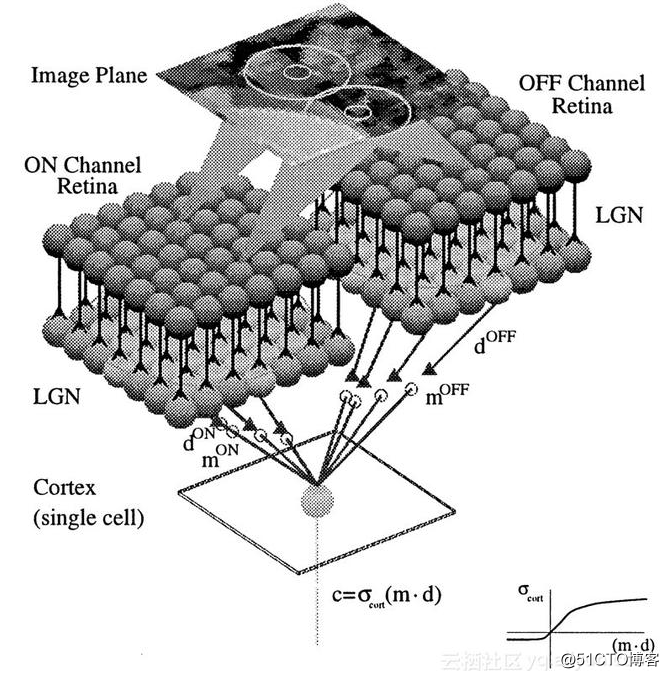
卷积神经网络的功能似乎是人类大脑中生物功能的复制,早在1959年,David Hubel和Torsten Wiesel对猫和猴进行了研究,这些研究揭示了动物视觉皮层的功能。他们发现的是,许多神经元具有小的局部接受性,即仅对整个视野的一小块有限区域起反应。他们发现某些神经元会对某些特定模式做出反应,例如水平线、垂直线和其他圆形。他们还发现其他神经元具有更大的感受野并且被更复杂的模式刺激,这些模式是由较低水平神经元收集的信息组合。这些发现奠定了我们现在称之为卷积神经网络的基础。接下来,我们逐一介绍卷积神经网络的组成。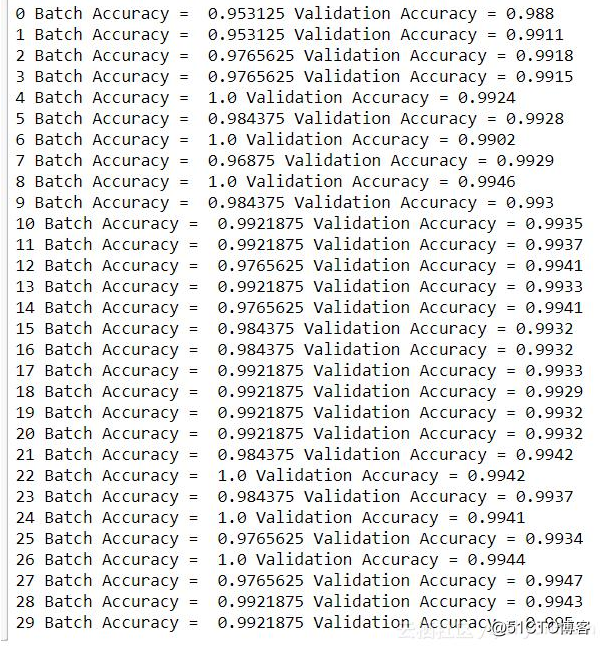
1、卷积层
卷积神经网络中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。你可以将每个过滤器描绘成一个窗口,该窗口在图像的尺寸上滑动并检测属性。滤镜在图像上滑动的像素数量称为步幅。步幅为1意味着滤波器一次移动一个像素,其中2的步幅将向前跳过2个像素。
在上面的例子中,我们可以看到一个垂直线检测器。原始图像为6x6,它使用3x3滤镜进行扫描,步长为1,从而产生4x4尺寸输出。而过滤器仅对其视野左右列中的部分感兴趣。通过对图像的输入求和并乘以3×3滤波器的配置,我们得到3+1+2-1-7-5=-7。然后滤波器向右移动一步,然后计算1+0+3-2-3-1=-2。-2然后进入-7右侧的位置。此过程将持续到4x4网格完成为止。之后,下一个特征图将使用它自己的唯一过滤器/内核矩阵计算自己的值。
2.池化层
池化层的目标是通过聚合卷积层收集的值或所谓的子采样来进一步降低维度。除了为模型提供一些正则化的方案以避免过度拟合之外,这还将减少计算量。它们遵循与卷积层相同的滑动窗口思想,但不是计算所有值,而是选择其输入的最大值或平均值。这分别称为最大池化和平均池化。
这两个组件是卷积层的关键构建块。然后,你通常会重复此方法,进一步减少特征图的尺寸,但会增加其深度。每个特征图将专门识别它自己独特的形状。在卷积结束时,会放置一个完全连接的图层,其具有激活功能,例如Relu或Selu,用于将尺寸重新×××为适合的尺寸送入分类器。例如,如果你的最终转换层为3x3x128矩阵,但你只预测10个不同的类,则需要将其重新×××为1x1152向量,并在输入分类器之前逐渐减小其大小。完全连接的层也将学习它们自己的特征,如在典型的深度神经网络中。
现在让我们看看在MNIST手写数字数据集上的Tensorflow中的实现。首先,我们将加载我们的库。使用sklearn中的fetch_mldata,我们加载mnist数据集并将图像和标签分配给x和y变量。然后我们将创建我们的训练/测试装置。最后,我们将举几个例子来了解任务。
接下来,我们将进行一些数据增强,这是提高模型性能的可靠方法。通过创建训练图像的轻微变化,可以为模型创建正则化。我们将使用Scipy的ndimage模块将图像向右、向左、向上和向下移动1个像素。这不仅提供了更多种类的例子,而且还会大大增加我们训练集的大小。
我将向你展示的最后一种数据增强的方式:使用cv2库创建图像的水平翻转。我们还需要为这些翻转图像创建新标签,这与复制原始标签一样简单。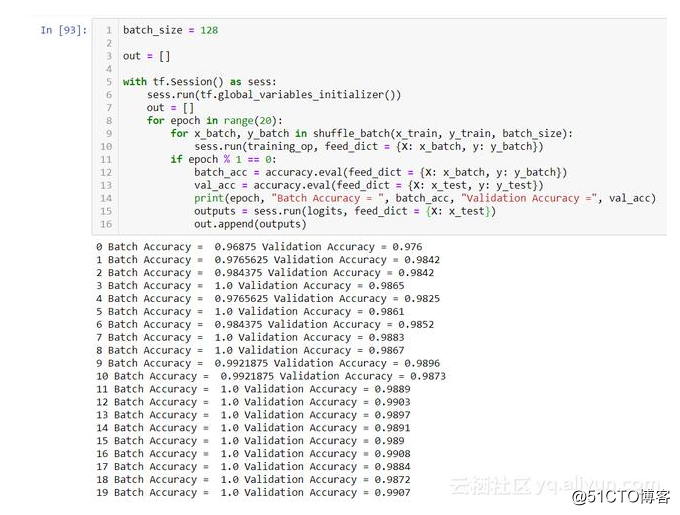
设置“flipCode = 0”将产生垂直翻转
接下来,我们将创建一个辅助函数,用于将随机微型批次提供给我们的神经网络输入。由于卷积层的性质,它们在前向和后向传播步骤期间需要大量的存储器。考虑具有4x4滤镜的图层,输出128步幅为1的特征图和具有尺寸299x299的RGB图像输入的SAME填充。参数的数量将相等(4x4x3+1)x128 = 6272.现在考虑这128个特征图中的每一个都计算299x299个神经元,并且这些神经元中的每一个都计算4x4x3输入的加权和。这意味着我们需要4x4x3x299x299x150=643,687,200次计算,这只是一个训练的例子。
现在我们开始创建我们的网络架构。首先,我们为我们的培训数据/特征创建占位符。我们需要将它们重新×××为(-1,28,28,1)矩阵,因为tensorflow conv2d层需要4维输入。我们将第一个维度设置为“null”,以允许将任意批量大小提供给占位符。
接着我们设计我们的卷积层,我是从Le-NET5(由Yann LeCun开创)网络架构中获取灵感,该架构因其在手写数字分类方面成功而闻名。我建议你研究Le-NET5以及其他经过验证的模型,这样就可以了解哪种卷积网络适用于不同的任务。
我们模型卷积层的第一层由12个特征图组成,使用3x3过滤器,步幅为1。我们选择了SAME填充,通过在输入周围添加一个零填充来保持图像的尺寸。然后,我们设置最大池化层使用3x3过滤器,步幅为1,这将输出13x13x12矩阵。所以我们从一个28x28x1的图像开始,然后我们将这个矩阵传递给第二个转换层,第二个转换层具有3x3过滤器的深度,stride=1和SAME填充。这将输出一个6616维矩阵。你可以看到我们正在缩小特征图的维度空间,但要更深入。接下来,我们使用Selu函数激活两个密集层来减少每层输入的数量大约一半,直到最终将它们输入我们的logits。
接着我们创建我们的损失函数,在这种情况下,它将是softmax交叉熵,它将输出多类概率。你可以将交叉熵视为各种数据点之间距离的度量。我们选择AdamOptimizer(自适应矩估计),当梯度下降时自动调整它的学习率。最后,我们创建了一种评估结果的方法。Tensorflow的in_top_k函数将计算我们的logits并选择最高分。然后我们使用我们的准确度变量输出0-1%之间的百分比。
现在我们已经为训练阶段做好了准备,让我们看看我们的模型表现得如何。
在第19epoch,我们的正确率在0.9907。这已经比任何机器学习算法的结果更好,因此卷积已经取得了领先。现在让我们尝试使用我们的移位功能/翻转功能,并为我们的网络添加两个新元素:dropout和批量标准化。
我们使用placeholder_with_default节点修改现有占位符,这些节点将保存批量标准化和dropout层生成的值。在训练期间,我们将这些值设置为True,在测试期间,我们将通过设置为False将其关闭。
批量标准化只是简单地对每批次的数据进行标准化。我们指定了0.9的动量。而dropout和正则化指定动量为1才能在训练期间完全随机地关闭节点。这导致其余节点必须松弛,从而提高其有效性。想象一下,一家公司决定每周随机选择50名员工留在家里。其余的工作人员将不得不有效地处理额外的工作,提高他们在其他领域的技能。
「Tensorflow」手把手CNN入门:手写数字识别
接着我们创建我们的损失函数,训练步骤和评估步骤,然后对我们的执行阶段进行一些修改。通过批量标准化执行的计算在每次迭代期间保存为更新操作。为了访问这些,我们分配一个变量extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)。在我们的训练操作期间,我们将其作为列表项与training_op一起提供给sess.run。最后,在执行验证/测试预测时,我们通过feed_dict为占位符分配False值。我们不希望在预测阶段有任何随机化。为了获得输出,我们使用我们的测试集运行logits操作。让我们看看这个模型添加正则化/标准化并且正在使用增强数据的方法后表现得如何。
在29epoch,我们在10,000个数字的测试集上达到了99.5%的准确率。正如你所看到的那样,第二个epoch时模型精确度达到了99%,而之前的模型只有16%。虽然0.05%可能不是很多,但在处理大量数据时这是一个重大改进。最后,我将向你展示如何在logits输出上使用np.argmax产生的预测。