这里是基于JDK1.8。

可以看出HashMap继承了AbstractMap,实现了Map。
先看看HashMap中的几个关键的属性:
默认初始容量是16:

也很好理解,1的二进制还是1:
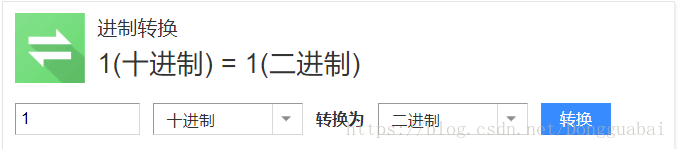
向左位移四位:


最大容量很大:

负载因子,主要用来扩展HashMap的容量,建议不要进行修改:

初始容量是16,那么就是在容量到达12的时候开始进行扩容。扩容越大,数据会越平均,检索速度会越快,但是占用的空间会比较大。比较小扩容会比较频繁,空间占用就会比较大。
链表节点转化为树形节点的阈值,即当链表节点到达8的时候就会转化为树形的结构:

树节点转化为链表节点的阈值:

树的最小容量:

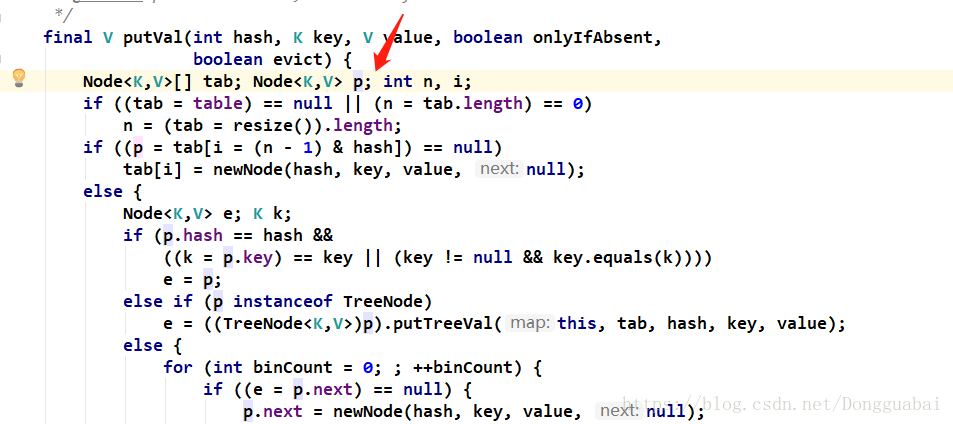
先看看put()方法:

主要是调用了putVal()方法,中间又调用了hash()方法,先看看hash()方法:

当key==null的时候就返回0(从这里也可以看出来HashMap的key是可以为null的),不为null就行计算key的hashCode()赋值给h,随后h和h向右偏移16位的值做一个抑或(可以参看https://blog.csdn.net/Dongguabai/article/details/83148609)。
这里选择位移16位是因为h是一个int类型的值,int值的取值范围是32位,向右位移16位刚好是32位的一半。
假设这是完整的数据,左边是属于高位,右边是属于低位:

向右位移16位就相当于整个低位的数据就没有了,高位的数据都到低位这边来了,原来的高位数据再用0去填充,然后新值和旧值再去做抑或:

这样的好处就是在没有外部数据接入的情况下,充分的使用了hashCode算出来的值进行计算。这样计算出来的hash值会相对的分散,只有尽量分散才尽可能的可以减少hash冲突,散列之后就不容易重复。
可以自己写个Demo测试一下:

在看putVal()方法前先看看Node,Node是HashMap中定义的一个类:

有hash值、K和V,还有一个next,就是指向下一个Node,这就明显是一个链表。
再看看putVal()方法:
//从这里可以看出HashMap的一个结构,数组加上链表:

将table赋值给tab,如果是空的就执行下面的逻辑:

关于table,在第一次使用时初始化,分配时,长度总是两个幂,也可以为0。

初始肯定是空的就会执行resize()方法进行扩容,肯定会执行下面这一段:
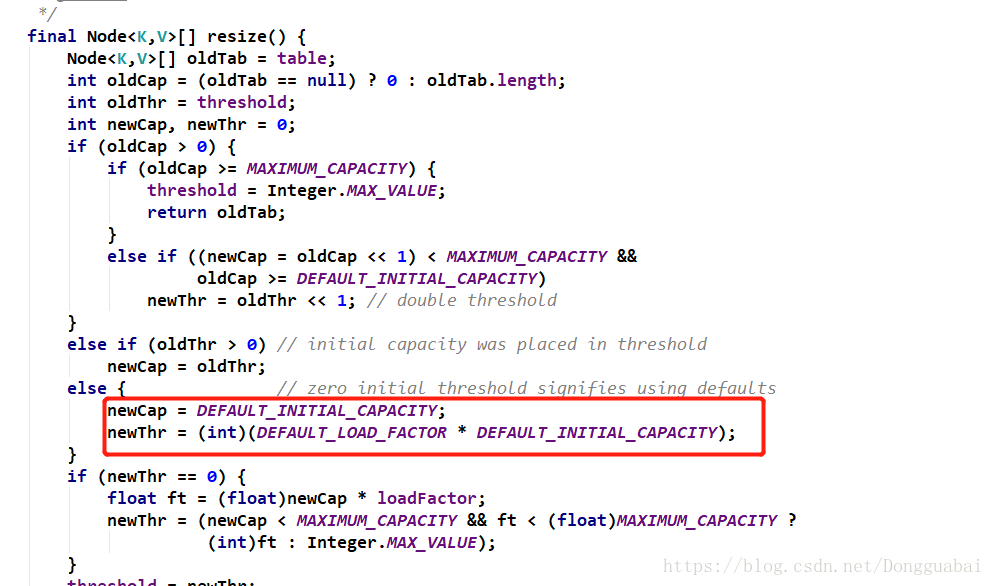
这里的容量的初始值是16。
newThr阈值就是初始值乘以负载因子。
综合也可以看出HashMap在new出来的时候,并没有创建一个16位长度的Node数组,而是在第一次put的时候才会创建一个初始的空间,里面有懒加载的思想,就是你用的时候才去初始容量。
再接着看putVal()方法:

首先,put的数据肯定要落到数组中的某一个节点中去,那具体是落到哪一个节点中去呢,就是通过这一段代码计算出来的。
先看这段:
i = (n - 1) & hashi的值等于(n-1)&hash,这其实是一个取%的过程。因为最大容量就是16,而hash值必然是一个比较大的数据,这里使用了一个&运算(可以参看:https://blog.csdn.net/Dongguabai/article/details/83150402),因为&运算的效率是高于%的。
这里n-1,初始值的n是16,减一就是15:
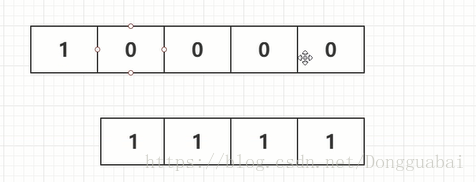
再去&一个值:

这里n必须要是2的倍数,因为2次幂有个特征,就是1的后面全是0:
比如32是这样:

2是这样:

而减去1了之后就是1变成0,后面全部是都是1:

再配合&运算,就可以%了。
再接着代码往下看:

找到了索引之后,如果是空的,就执行下面的方法,去创建一个Node对象并赋值,要注意的是这个时候的next是null。

如果不为空就执行else里面的代码:
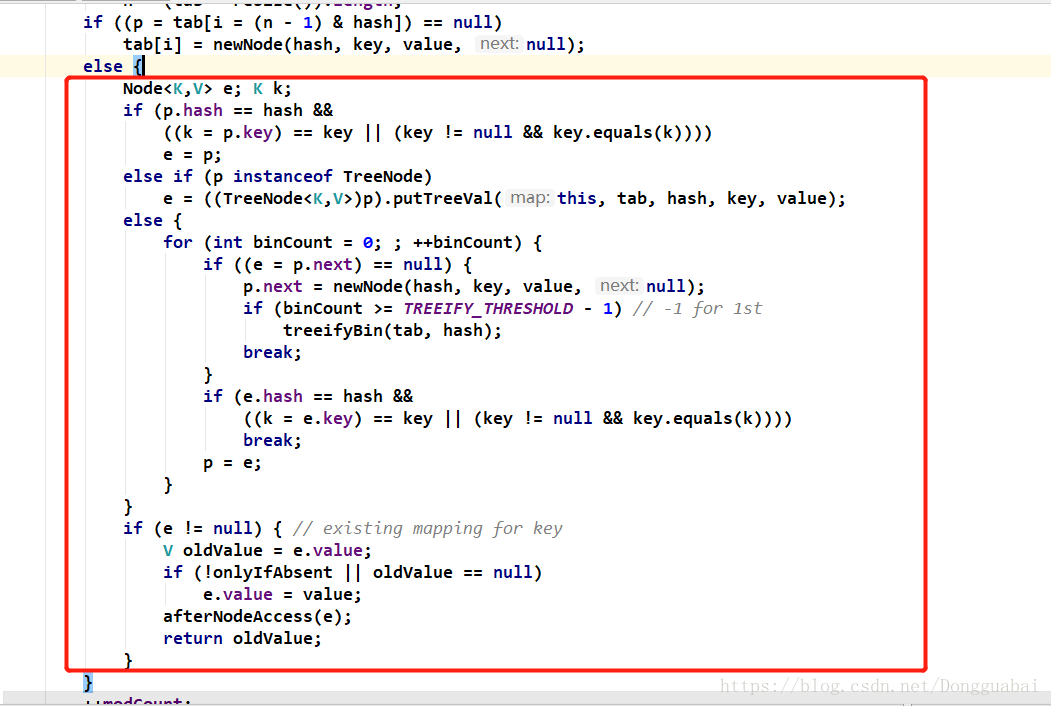
会判断节点是不是一个TreeNode的类型:

这个p是哪里来的呢:
目前暂时还是Node还不是TreeNode,先分析不是TreeNode的情况:
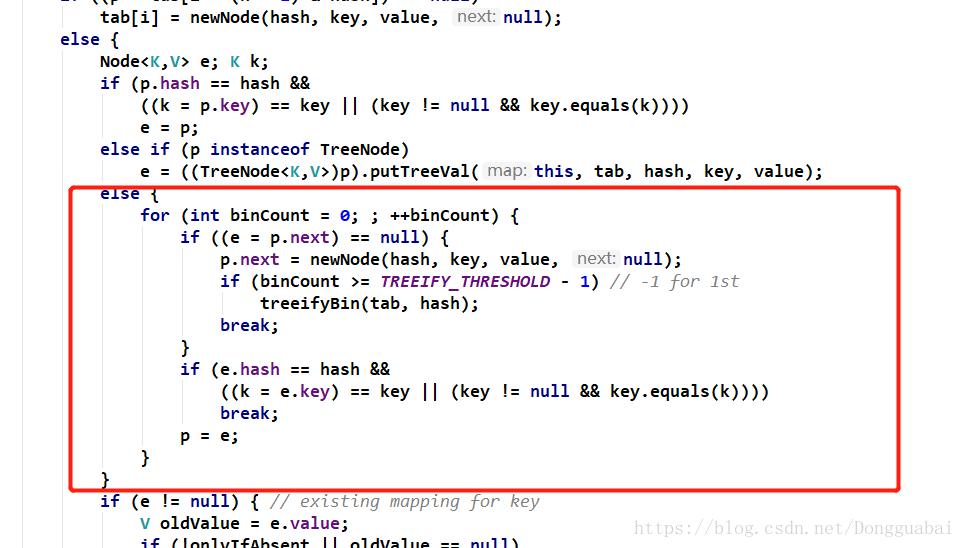
从这里大概可以进一步看出结构就是数组加上链表(JDK1.8就是简单的数组加链表):
继续看代码:

如果next Node是空的,就会创建一个新的Node放进去,即如果数组中的位置被占用了,就会到next Node。而且这一段代码是在一个for循环里面,简单点说,就是因为这个链表可能很长,就会一直找,直到找个那个next Node是空的Node就放进next Node中去,这个说法也不准确。在这段代码中看到了一个熟悉的变量TREEIFY_THRESHOLD,即到了8的时候会把这个Node转化为一个TreeNode。
也就是说,当节点数大于等于7的时候,就会转换成树形结构(红黑树):

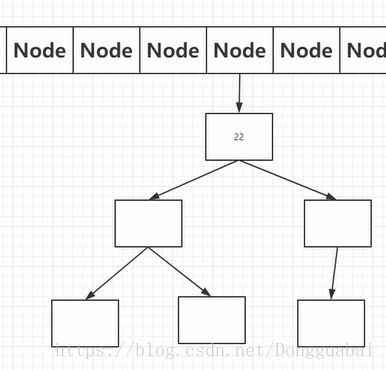
那么为什么要这么做呢,我们把可以先回顾一下put数据的流程,首先要通过hash()方法,然后&运算之后找到数组坐标,找到坐标,找到坐标之后还要再遍历这个链表,时间复杂度是o(N)。而树检索的时间复杂度是o(logN),也就是说在一定的长度内链表数据是很快的,但是超过一定长度,树会比较快。
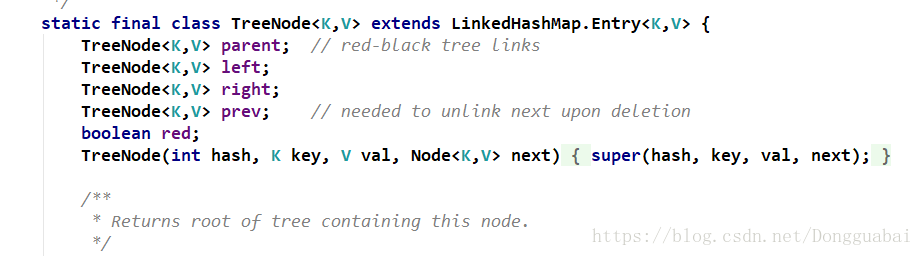
TreeNode,有左、右、父节点、过度节点和是否为red属性:
看看这个转化为树的方法:

首先会判断容量,如果比最小容量还要小,那就要进行扩容处理。然后会将链表结构转化为红黑树的结构。

在一个do...while()循环中不停的转换。看看这个treeify()方法:

涉及到不少红黑树的相关知识(可以参看:https://www.sohu.com/a/201923614_466939)。
接着看putVal()方法:
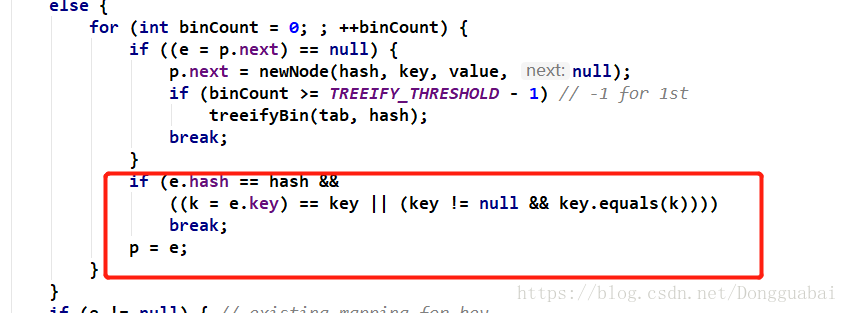
如果没有达到阈值就直接赋值即可。
接着看:

还会判断老的值是不是等于新的值,如果是的话,就会覆盖老的value。这也和我们平时使用的时候HashMap的特性有关,当你连续put两次相同key值的数据的时候,后面一次的value会覆盖前一次的value。
接着看:

当容量大于阈值的时候,就会走这个resize()方法:

会判断容量是否到达了最大的容量,如果容量到达了最大的容量就不进行扩容了。也就是说不能横向扩容了,只能纵向通过链表或者红黑树进行数据增加了。
接着看:

先oldCap<<1,即将容量扩1倍,进行一些判断后会将当前的阈值翻倍。即容量的变化是,当容量超过12会进行扩容,然后是16、32、64...直到到达了1<<30。
到这里,就扩容完成了,那扩容完成之后要干嘛呢,其实就像Redis、MySql、Oracle等,在数据到达一定量的时候,都会需要进行扩容,而扩容之后为了数据的平衡,都会进行一些复制操作。
假设现在容量到达了16,需要进行扩容处理:

这时候会有一个数据迁移的过程:

目的主要是将数据平均分布,这样才能提升检索速度,如果数据都集中在一个链表上面,这样检索速度会很慢。
再来回过头看扩容之后的处理流程:

首先会构建一个新的Node数组,容量就是扩容后的容量。

新的数组索引计算是通过hash值和新的容量减一再进行一个&运算。
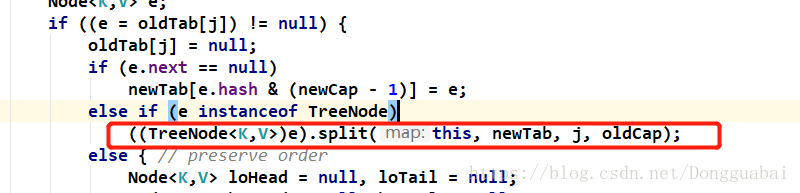
如果当前Node是TreeNode的话,就会“切树”。
接着看:
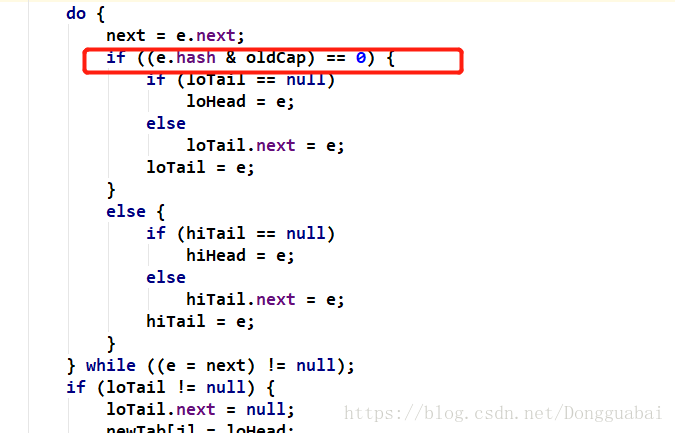
如果e.hash和老的容量进行&运算等于0,就不迁移,不等于0就迁移。迁移之后,Node数组中的某个Node上的链条上的数据就散开分配了。
接着看:

也可以看出,“新家” 的位置就是老的容量加上当前循环到的j(其实这个j就是这个数据之前再数组中的索引)。
HashMap的get()方法的实现就比较简单了:

就是从Node中找数据:
