最近,我阅读了一篇介绍计算机体系结构的文章,感觉比较简洁而且全面的介绍了计算机体系结构的内容。文章的链接是Modern Microprocessors A 90-Minute Guide!。因此,我谨以此文来做下总结,好让以后来回忆。
首先,我先说下对计算机体系结构(computer architecture)的理解。我觉得计算机体系结构就是计算机组成原理,而且与IC设计密切相关,核心的问题就是在既定的指令集下,如何设计CPU的微架构来使它尽可能的快速执行指令。还有一点就是,在摩尔定律的作用下,也就是制造工艺的越来越精细,在相同的芯片面积上,我们设计微架构可用的晶体管越来越多。因此,如何有效的利用这些数以亿计的晶体管来为我们的目标服务,也是一个很重要的问题。
下面,我就总结一下内容。
-
不只是频率
一个处理器的性能与它的频率有一定的关系,但是不一定频率越高的处理器性能就越好。这就要涉及到在不同的微架构下,一个时钟周期到底干了什么事。也就是要比较不同微架构的优越性了。
-
流水线和指令级并行(ILP)
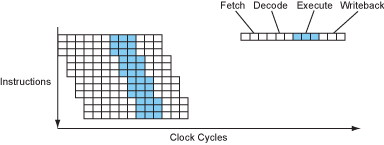
一开始的处理器处理指令是一条接着一条的,这是简单明了的,但是也是效率低下的。因为指令执行的过程中至少可以分为4个阶段,分别为:取指令、解码、执行和写回存储器。这几个阶段负责的模块只有在相应的阶段才会处于工作状态,其余阶段都是闲置,于是这显然就有提升的空间。没错,就是让下一条指令接着马上执行。这就是流水线设计的核心思想。具体就是:当一条指令取完了,就可以立即取下一条指令了,后面的操作以此类推。
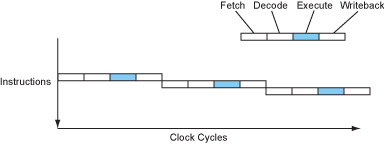
可以看到,流水线的设计使处理器的CPI(cycle per instruction)从4降到了1。当然这是理论值。其实,我觉得这已经是一种指令级并行的形式了,只不过这种方法属于比较简单的。还有,早期的RISC处理器d都实现了5阶段的流水线设计。而早期的CISC处理器,如80386,因为复杂指令集的原因没有实现流水线设计。
-
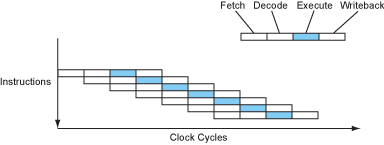
更深的流水线——超流水线
因为时钟周期的长度是由最耗时的流水线阶段来决定的,所以一种思想就是将那些耗时长的阶段再分成一些较短的阶段。这样做的话就能使时钟周期尽可能的短,从而提升了处理器的频率。还有,因为CPI还是1,而每秒钟的周期数提升了,所以总体的性能提升了。
-
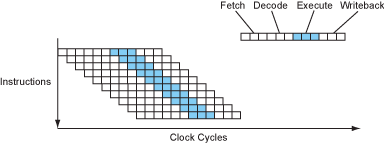
多发射(Multiple Issue)——超标量 (Superscalar)
因为在执行阶段有许多的功能单元,比如整数处理单元、浮点数处理单元和访存处理单元,它们各自完成它们自己的任务。于是,我们就会想到能不能让它们同时工作起来而不闲置,从而提高效率。为了做到这样,就必须改进取指令单元和解码单元,让它们能同时取和解码多条指令,从而根据指令功能的不同分发给不同的处理单元。
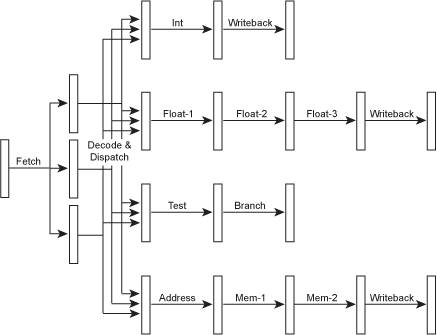
鉴于不同的处理单元所要求的处理阶段数量不同,于是每条流水线的深度就不同。于是,当我们描述一个处理器的流水线深度时通常是用它处理整数的深度,因为这个深度通常是最少的。
当然,我们可以让一个处理器同时是超标量和超流水线设计的,因为这两种设计并不冲突。最终,在这种设计加持下,指令级并行程度进一步提高。
-
显式并行——VLIW(Very Long Instruction Word)
这种设计是重新设计指令集,使每条指令包含多条小指令,从而变得很长(very long instruction)。这样做的话就相当于一条指令就能让多个功能单元都工作起来,与超标量处理器非常相似,但是大大简化了解码和分发单元的逻辑设计。但是我们编程的方式并没有变,所以指令间的相关性还是存在。因此我觉得这种设计的实质是把指令间相关性检查的工作从硬件转移到编译器(软件) ,从而简化了硬件的设计,让处理器的速度得以提升。
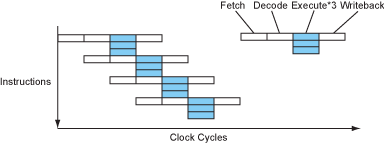
但是,这种设计的处理器都没有取得商业上的成功。其中最著名的例子就是Intel的IA-64架构,Intel希望用这个指令集取代X86指令集,但是最终被AMD的X86_64指令集打败。
-
指令相关性和延迟
既然超流水线和多发射这么好,那为什么不尽量让这些指标多些呢?比如做一个50级流水线和20发射的处理器。。。
但是,实际上不是这样的,很多指令间都存在相关性,比如下一条指令要用到上一条指令的执行结果。这样就阻止的指令的并行执行。还有,不同指令的执行时间不同,有的要流水线较短,有的较长,所以不同指令的执行延迟就不同。对于短延迟的整数操作,下一条指令可以马上开始解码执行,但是对于长延迟的浮点数操作,下一条相关指令就必须等待。这些相关性就限制了指令间的并行性。
-
分支和分支预测
还有一个影响指令级并行的因素是分支指令。对于流水线设计的处理器,指令是一条接着一条马上执行,但是如果出现了分支指令,就代表着紧接着的下面的指令有可能是不用执行了。若执行了,就是在做无用功。而且,对于越深的流水线,无用功就越多。对于这种情况,处理器可以选择等待分支指令的执行结果,但是这会大大降低性能,因为平均下来,一个程序有1/6的指令是分支指令。因此,处理器必须猜一条执行路径。对于猜测路径,分为两种方法。一种是编译器来猜,这种方法称为静态分支预测。这种方法实际上是把工作重点放在软件上,但是编译器通常也很难预测分支的走向。另一种方法就是处理器自己猜,这种方法称为动态分支预测。在这种处理器中,通常都有负责分支预测的模块。鉴于分支预测的重要性,目前处理器的分支预测模块非常复杂和庞大。目前最牛逼的预测准确率能达到95%。
-
用断言消除分支预测
这个小节说白了就是用条件转移指令来消除分支预测。(不太懂。。。)
-
指令调度,寄存器重命名和乱序执行
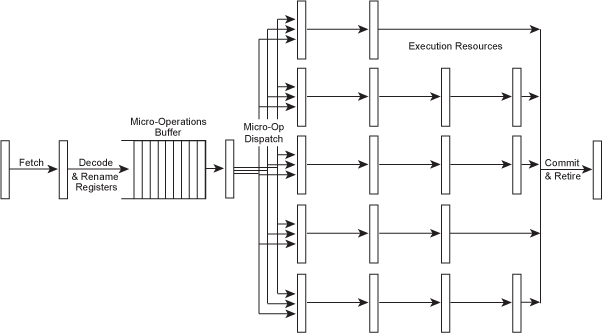
因为分支指令和长延迟指令会使流水线空闲一段时间。 一种思想就是让这些空闲着的流水线执行在后面的不相关的指令。这就打乱了指令的顺序执行性,于是把这种设计称为乱序执行。对于乱序执行,有些指令虽然不相关,但是它们会用到相同的寄存器(因为寄存器就是那么几个),比如都往同一个寄存器写内容,这样也会限制了它们的并行执行。于是又提出来一种技术,称为寄存器重命名。我的理解就是处理器内部拥有许多隐藏的寄存器,为了让这些用相同寄存器的指令同时执行,只能让这些指令使用不同的隐藏的寄存器,而且又为了保证一致性,这些隐藏的寄存器就会被暂时重命名为这条指令所指定的寄存器。
对于如何实现乱序执行,与分支预测相似,也有两种方法。一种是编译器负责重排指令顺序,提高处理器执行指令的并行度,称为静态指令调度。这种方法其实就是完全的软件解决方案,处理器一点改变都没有。另一种就是处理器负责乱序执行后面的指令,称为动态指令调度。这种方法需要处理器的取指令和解码/分发模块大大增强,增加了处理器设计的复杂性和处理器的功耗。
最终,这种技术又进一步的提高了处理器的指令级并行程度。
-
The Brainiac(能力超群的) Debate
这个争论说白了就是处理器核心应该选择乱序执行设计还是顺序执行设计。乱序执行设计的速度快但是核心面积大,导致单个芯片能集成的核心数减少。 顺序执行设计的速度较慢但是核心面积小,于是单个芯片能集成的核心数增加。这就是一种权衡嘛!
-
功耗墙和ILP(指令级并行)墙
这个小节主要就说明了处理器核心的频率不能无止境的提升,提升到一定程度就会使发热和功耗暴增(呈指数形式的),这就是为什么今天处理器的极限频率都差不太多。(5GHz基本极限了) 这个现象称为功耗墙。于是采用顺序执行设计的处理器的频率遇到了瓶颈,被采用乱序执行设计的处理器迎头赶上,于是性能差距变大。
当然,这也不是说明采用乱序执行设计就是完美的。因为真实软件的指令流的可并行性实在是有限。当前,主流软件的单线程模式下,指令级并行程度最多在大约2~3指令每时钟周期,即2~3IPC。这种现象称为ILP墙。
-
关于X86指令集
X86指令集是复杂指令集,它是很难运用上面所说的各种技术的。于是,Intel终于想出了一种办法,就是在处理器内部添加一个 翻译模块,把读取到了X86指令翻译为1~3条类似于RISC指令的微小操作指令μops,后面再根据这些微小指令来进行处理操作。其实,这些微小操作指令集基本就相当于一种RISC指令集了。于是,能顺利用到RISC指令集上的技术都能顺利的用到X86指令集世界了,这大大增强了X86这个古老的CISC指令集的竞争力。这也说明CISC和RISC之争是有结论的,RISC取得胜利!
-
线程——SMT、超线程和多核
因为单个指令流的并行度有限,导致超标量、流水线设计的处理器的许多功能模块很多时候都是处于空闲状态。于是,有种思想就是既然单个指令流(单个线程)的并行度有限,那么我就在空闲的时候执行另一条线程的指令流不就能充分利用处理器的功能模块了吗?因为这完全是两个指令流,基本上它们是互不相干的,除非有同步机制,所以它们两个之间的指令的并行度肯定很高。于是,基于这种思想,Intel推出了超线程技术,一个核心能同时运行两个线程。那么既然要同时运行两个线程,那么单独记录每个线程的执行状态的单元必然要有两份,这些单元包括程序计数器(PC)、体系结构可见的全部寄存器和缓存页表记录的TLB等等。其实,这些单元只占很少的芯片面积,真正的大头:解码器、功能单元和cache等等都是可以共用的,所以这个设计大约只增加10%的芯片面积 。
还有,虽然一个核心能同时运行两个线程,但是毕竟只是一个核心,那么不同线程之间对于相同功能单元的利用必然要竞争,有竞争就必然有等待。所以速度肯定是不如两个核心运行两个线程的,还有可能造成两个线程都执行得很慢。这就要靠处理器厂商的慢慢优化了,我这里只说明大概思想。
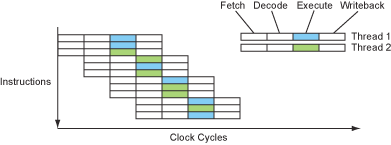
这种技术利用的并行性称为线程级并行。
-
更多的核心还是更宽的核心?
本节就主要讨论一个芯片的核心应该怎么设计好,是应该每个核心把上面的技术都用上呢,还是尽量保持小核心呢?如果都把上面的技术用上,那么单个核心的面积必然会很大,于是单个芯片能集成的核心数就变少。这种情况就相当于单线程的速度很快,但同时运行的线程数较少。如果尽量保持小核心,就是有选择的使用上面所述的技术,那么单个核心的面积就会变小,于是单个芯片能集成的核心数就会变多。这种情况就相当于单线程的速度变慢,但是同时运行的线程数增多。
其实,这两种设计没有孰优孰劣,只是各自都有自己适合的应用领域。Intel的桌面处理器通常都是核心超大,就是单核能力超群,而单芯片的核心数较少。
-
数据级并行——SIMD 向量指令
说完了指令级并行和线程级并行,现在就来说说另一种并行——数据并行。我觉得数据并行就是对一组数据都做相同的操作,于是我们可以开发一种指令专门来统一处理这种操作,就称为Single Instruction Multiple Data。因此,就可以用一条指令来完成以前需要多条指令完成的任务,提升了性能。这种指令集对特定应用非常有用,比如图像和视频处理、3D图形渲染和各种科学计算代码等等。
现在几乎所有的体系结构都添加了SIMD指令集,比如SPARC (VIS), x86 (MMX/SSE/AVX), POWER/PowerPC (AltiVec) and ARM (NEON)。
那篇文章下面的内容都是讨论存储器的问题,我就不多说了。。。。。