L1正则化
L1范数是指向量中各个元素的绝对值之和。

对于人脸任务
原版的人脸像素是 64*64,显然偏低,但要提高人脸清晰度,并不能仅靠提高图片的分辨率,还应该在训练方法和损失函数上下功夫。众所周知,简单的 L1Loss 是有数学上的均值性的,会导致模糊。
L2正则化
L2正则化就是权重衰减,是一个手段,是指:
L2正则项(regularization term) * 正则化系数(positive coefficient)
其中,正则项是整个网络的所有权重w的平方的和。正则化系数一般是一个接近0的值(caffe中一般设为0.0005),它一定在(0,1]区间中。
惩罚项,权重衰减
在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网络权值逐渐变大,因此,为了避免出现overfitting,会给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。其用来惩罚大的权值。
之所以称之为权重衰减,是因为它使得权重变⼩。粗看,这样会导致权重会不断下降到0。但是实际不是这样的,因为如果在原始代价函数中造成下降的话其他的项可能会让权重增加。
L2正则化项有让w“变小”的效果,但是还没解释为什么w“变小”可以防止overfitting?人们普遍认为:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好(这个法则也叫做奥卡姆剃刀)。
公式
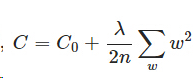


L1与L2正则化的辨析
作用上的差异
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,因此可以用于特征选择,惩罚⼤的权重,倾向于让⽹络优先选择⼩的权重。
L2正则化可以防止模型过拟合(overfitting)。
L1正则化的稀疏化的好处
1)特征选择实现特征的自动选择,去除无用特征。稀疏化可以去掉这些无用特征,将特征对应的权重置为零。
2)可解释性(interpretability)如判断某种病的患病率时,最初有1000个特征,建模后参数经过稀疏化,最终只有5个特征的参数是非零的,那么就可以说影响患病率的主要就是这5个特征。
公式上的差异
L1范式说白了就是平均值的和;L2范式就是平方和。
L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1 。一般还要乘以λ/n(n是训练集的样本大小;λ是正则项系数)。
L2正则化是指权值向量w中各个元素的平方和然后再求平方根,用在回归模型中也称为岭回归(Ridge regression),有人也叫它“权值衰减weight decay”。一般还要乘以λ/n(n是训练集的样本大小;λ是正则项系数)。
L0与L1正则化的辨析
L0范数是指向量中非零元素的个数。如果用L0规则化一个参数矩阵W,就是希望W中大部分元素是零,实现稀疏。
L1范数是指向量中各个元素的绝对值之和,也叫”系数规则算子(Lasso regularization)"。L1范数也可以实现稀疏,通过将无用特征对应的参数W置为零实现。
L0和L1都可以实现稀疏化,不过一般选用L1而不用L0,原因包括:
1)L0范数很难优化求解(NP难);
2)L1是L0的最优凸近似,比L0更容易优化求解(这一段解释过于数学化,姑且当做结论记住)。