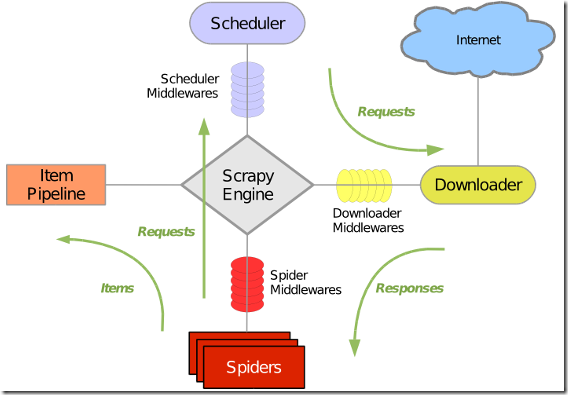
一、项目简单流程
1、创建项目
scrapy startproject 项目名
2、创建Spider
cd 项目名
scrapy genspider 爬虫名 域名
class YokaSpider(scrapy.Spider):
name = 'yoka'
allowed_domains = ['www.yoka.com/fashion/']
start_urls = ['http://www.yoka.com/fashion/']
def parse(self,response):
pass
创建的Spider类需继承scrapy.Spider
name:爬虫名
allowed_domains:允许爬取的域名,不在域名下的请求链接会被过滤掉
start_urls:Spider启动时爬取的url列表,初始请求由它来定义
parse:默认情况下, start_urls里的链接请求完成下载后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据、进一步生成要处理的请求
3、创建Item
Item是保存爬取数据的容器,使用方法和字典类似,不过多了额外的保护机制,可以避免拼写错误和定义字段错误
创建的Item类需继承scrapy.Item,并定义类型为scrapy.Field的字段
class YokadapeiItem(scrapy.Item):
text= scrapy.Field()
tags=scrapy.Field()
4、解析Response