版权声明:转载声明来源,请勿用于商业用途! https://blog.csdn.net/qq_27180763/article/details/83617196
64位计算机和32位计算机CPU对内存处理的区别
64位CPU,位宽为8个字节。(64位/8位/字节=8字节)
32位CPU,位宽位4个字节。(32位/8位/字节=4字节)
我们假想内存空间是一个二阶矩阵。(事实上内存是一维线性排列的)
那么二维数组的列数在64位CPU上就是8字节,在32位CPU上就是4个字节。
CPU为了寻址方便,会自动优化内存,来让数据尽量在同一二维数组行中,以减少寻址时间。(这里我们只探讨内存。不涉及寄存器以及cache。)
C语言结构体 操作系统进行内存管理的体现
我们先创建以下结构体
#include <stdio.h>
struct student1 {
char name[8];
int age;
};
struct student2 {
char name[6];
int age;
};
在64位操作系统中。char型占一个字节。age型占4个字节
所以理论上,student1这个类型新建的对象所占字节大小应该是8+4=12个字节。student2这个类型新建的对象所占字节大小应该是6+4=10字节。
但是在实际运行中,两个字节大小都是12字节。
先来看四个重要的基本概念:
1) 数据类型自身的对齐值:char型数据自身对齐值为1字节,short型数据为2字节,int/float型为4字节,double型为8字节。
2) 结构体或类的自身对齐值:其成员中自身对齐值最大的那个值。
3) 指定对齐值:#pragma pack (value)时的指定对齐值value。
4) 数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小者,即有效对齐值=min{自身对齐值,当前指定的pack值}。
基于上面这些值,就可以方便地讨论具体数据结构的成员和其自身的对齐方式。
其中,有效对齐值N是最终用来决定数据存放地址方式的值。有效对齐N表示“对齐在N上”,即该数据的“存放起始地址%N=0”。而数据结构中的数据变量都是按定义的先后顺序存放。第一个数据变量的起始地址就是数据结构的起始地址。结构体的成员变量要对齐存放,结构体本身也要根据自身的有效对齐值圆整(即结构体成员变量占用总长度为结构体有效对齐值的整数倍)。
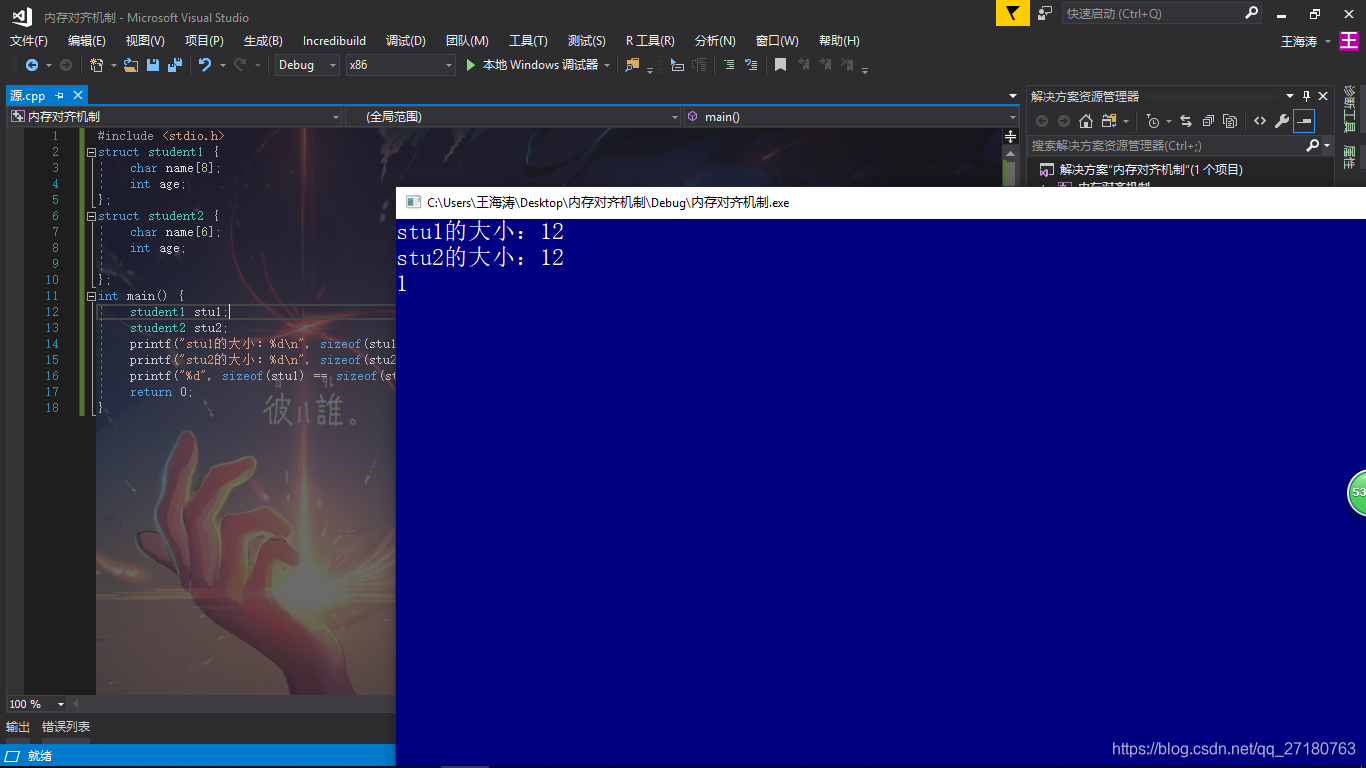
而通过汇编代码可以看出。编译器自动优化了内存空间,两个结构体拿到的地址都是16个字节大小的。这也是由于CPU位宽所导致的关于程序对于地址空间的优化导致的。实际上,这也是一种以空间换时间的方式。