内存模型,英文名Memory Model,他是一个很老的老古董了。他是与计算机硬件有关的一个概念。
CPU和缓存一致性
随着CPU技术的发展,CPU的执行速度越来越快。而由于内存的技术并没有太大的变化,所以从内存中读取和写入数据的过程和CPU的执行速度比起来差距就会越来越大,这就导致CPU每次操作内存都要耗费很多等待时间。
所以,人们想出来了一个好的办法,就是在CPU和内存之间增加高速缓存。缓存的概念大家都知道,就是保存一份数据拷贝。他的特点是速度快,内存小,并且昂贵。
那么,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。
而随着CPU能力的不断提升,一层缓存就慢慢的无法满足要求了,就逐渐的衍生出多级缓存。
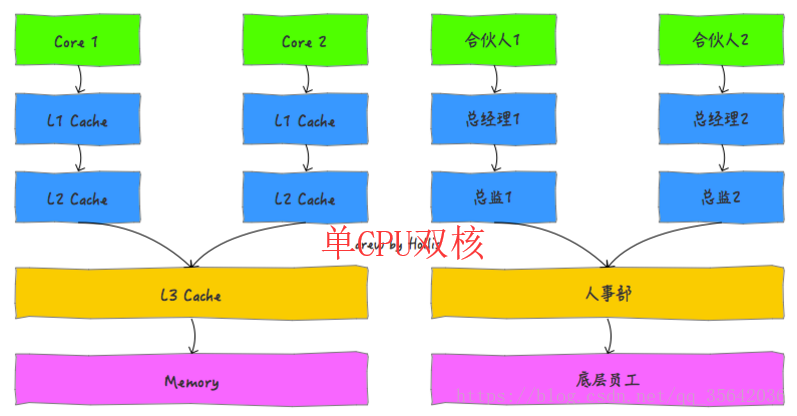
按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存(L1),二级缓存(L2),部分高端CPU还具有三级缓存(L3),每一级缓存中所储存的全部数据都是下一级缓存的一部分。
这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。
当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。
单核CPU只含有一套L1,L2,L3缓存;如果CPU含有多个核心,即多核CPU,则每个核心都含有一套L1(甚至和L2)缓存,而共享L3(或者和L2)缓存。
单线程。cpu核心的缓存只被一个线程访问。缓存独占,不会出现访问冲突等问题。
单核CPU,多线程。进程中的多个线程会同时访问进程中的共享数据,CPU将某块内存加载到缓存后,不同线程在访问相同的物理地址的时候,都会映射到相同的缓存位置,这样即使发生线程的切换,缓存仍然不会失效。但由于任何时刻只能有一个线程在执行,因此不会出现缓存访问冲突。
多核CPU,多线程。每个核都至少有一个L1 缓存。多个线程访问进程中的某个共享内存,且这多个线程分别在不同的核心上执行,则每个核心都会在各自的cache中保留一份共享内存的缓冲。由于多核是可以并行的,可能会出现多个线程同时写各自的缓存的情况,而各自的cache之间的数据就有可能不同。
在CPU和主存之间增加缓存,在多线程场景下就可能存在缓存一致性问题,也就是说,在多核CPU中,每个核在自己的缓存中,关于同一个数据的缓存内容可能不一致。
处理器优化和指令重排
上面提到在CPU和主存之间增加缓存,在多线程场景下会存在缓存一致性问题。除了这种情况,还有一种硬件问题也比较重要。那就是为了使处理器内部的运算单元能够尽量的被充分利用,处理器可能会对输入代码进行乱序执行处理。这就是处理器优化。
除了现在很多流行的处理器会对代码进行优化乱序处理,很多编程语言的编译器也会有类似的优化,比如Java虚拟机的即时编译器(JIT)也会做指令重排。
可想而知,如果任由处理器优化和编译器对指令重排的话,就可能导致各种各样的问题。
并发编程的问题
原子性是指在一个操作中就是cpu不可以在中途暂停然后再调度,既不被中断操作,要不执行完成,要不就不执行。
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性即程序执行的顺序按照代码的先后顺序执行。
缓存一致性问题其实就是可见性问题
处理器优化是可以导致原子性问题
指令重排会导致有序性问题
参考链接: