-
将函数赋值给变量
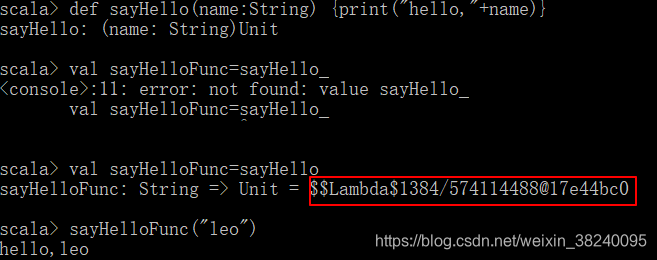
(1) Scala函数是“一级元素”,可以独立定义,独立存在,而且可以直接将一个函数赋值给一个变量
(2) Scala语法规定,将函数赋值给变量时,必须在函数名后面加上空格和下划线
-
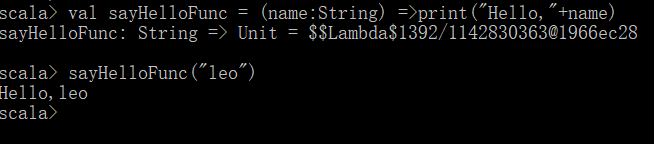
匿名函数(类似Java的Lambda表达式,Spark中将大量使用)
Scala定义匿名函数的语法规则:(参数名:参数类型) => 函数体
-
高阶函数
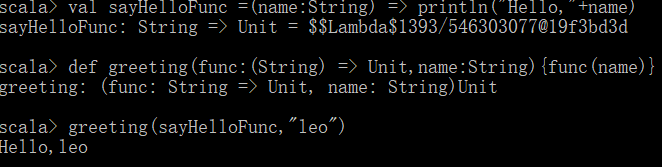
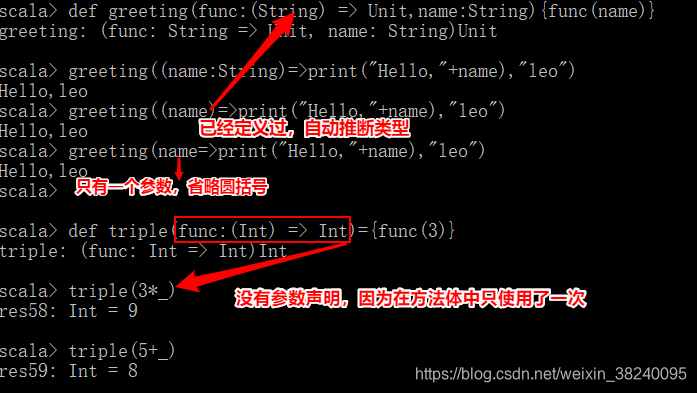
(1) 由于函数是Scala中的一等公民,因此可以直接将某个函数作为参数传入其他函数,接收者即为高阶函数
(2) 关键字func,其定义语法规则为:def 函数名( func : (传入函数的参数类型) => 返回类型,参数名:参数类型){ func(…) }
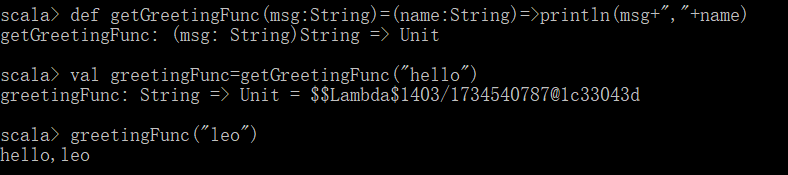
(3) 高阶函数另一个功能是将函数作为返回值
(4) 高阶函数的类型推断
<1> 高阶函数可以自动推断出参数类型,而不需要写明返回类型
<2> 对于只有一个参数的函数,还可以省去其小括号
<3> 如果仅有的一个参数在右侧的函数体内只使用一次,则可以将接收参数省略,并使用“_”来代替参数
(5) 常用的高阶函数
函数 说明 Array.map 对传入的每个元素都进行处理并返回 
Inclusive.foreach 对传入的每个元素进行遍历处理,但没有返回值 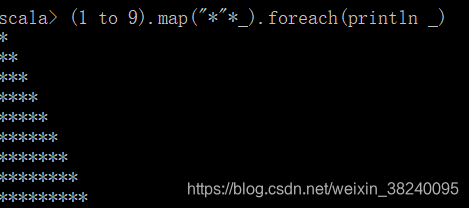
Inclusive.filter 对传入的每个元素都进行条件判断,如果判断后返回true,则保留该元素,否则过滤掉该元素 
Inclusive. reduce, Spark编程的核心 从左侧元素开始,进行reduce操作:即先对元素1和元素2进行处理得到结果1,然后将结果1与元素3处理得到结果2,再将结果2与元素4处理,以此类推,reduce为“一”

Arrays.sortWith 排序 
-
闭包
(1) 简洁解释:函数在变量不处于其有效作用域时,还能够对变量进行访问,即为闭包
(2)案例

说明:
<1> 两次调用getGreetingFunc函数,传入不同msg,并创建不同的函数返回<2> 然而,msg只是一个局部变量,在getGreetingFun执行完后,继续存在创建的函数中。greetingFuncHello(“leo”)调用时,值为"hello"的msg被保留在函数体内部,可以反复使用。这种现象即为闭包
<3> 底层原理:Scala通过为每个函数创建对象来实现闭包,实际上对于getGreetingFunc函数创建的函数,msg是作为函数对象的字段存在的,因此每个函数可以拥有不同状态的msg
-
SAM转换
(1) 在Java中,不支持直接将一个方法作为参数传入另一个方法。通常来说,唯一的办法就是定义一个实现了某接口的匿名类实例,该对象只有一个方法。由于这些接口都只有单个的抽象方法,也就是single abstract method,简称为SAM(2) 由于Scala可以调用Java的代码,因此当调用Java的某个方法时,可能就不得不创建SAM传递给方法,非常麻烦。但Scala又支持直接传递函数,此时就可以使用Scala提供的SAM转换,将SAM转换为Scala函数
(3) 隐式转换
扫描二维码关注公众号,回复: 4146206 查看本文章
-
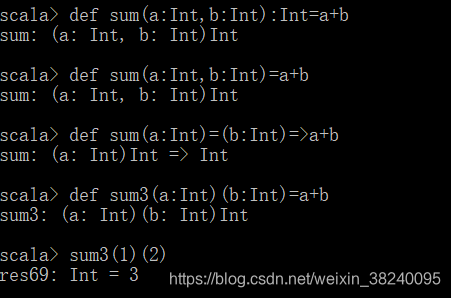
Currying(柯里化)函数
(1) 将原来接收两个参数的一个函数,转换为两个函数:第一个函数接收原来的第一个参数,然后返回接收原先第二个参数的另一个函数
(2) 函数调用的过程中,就变为了两个函数连续调用的形式
(3) 案例
-
return
(1) Scala中,不需要使用return来返回函数的值,函数最后一行语句的值即为返回值
(2) Scala中,return用在内部函数,将值返回给包含它的命名函数,并作为命名函数的返回值
(3) 使用return的内部函数,是必须给出返回类型的,否则编译错误 -
集合操作
(1) Scala集合体系结构
<1> Scala中体系结构主要包括:Iterable, Seq, Set, Map。其中Iterable是所有集合Trait的根
<2> Scala集合分为两类:可变和不可变,分别对应scala.collection.mutabe和scala.collection.immutable
<3> Seq又包含了Range,ArrayBuffer,List等子Trait(2) List
<1>List代表一个不可变列表<2>通过伴生对象创建,val list = List(1,2,3,4)
<3>List-head, tail : head代表第一个元素,即单个元素;tail代表第一个元素之后的所有元素,即子集
<4> 特殊操作符:如0::list,将0和list合并为一个新list,0为head(Spark源码)
<5>案例

※Nil表示只有容器没有元素即空List,而不是没有容器结构即空Null(3) LinkedList
<1> LinkedList代表一个可变列表<2> LinkedList -> elem,next : 使用elem引用其头部;使用next引用其尾部
<3> 案例
使用while循环将LinkedList的每个元素乘2

使用while循环将LinkedList的间隔元素乘2

(4) Set
<1> HashSet
<2> LinkedHashSet
<3> SortedSet(5) 集合函数式编程(重点:高阶函数)
函数 说明 map 
flatmap 
foreach 
zip 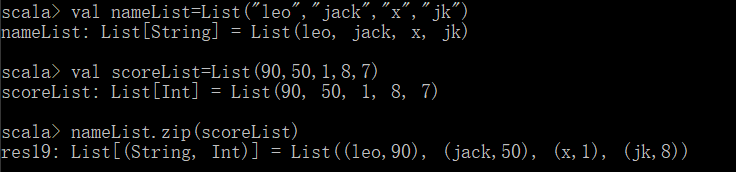
[笔记迁移][Spark开发语言][Scala][12]函数式编程
版权声明:Collected by Bro_Rabbit only for study https://blog.csdn.net/weixin_38240095/article/details/84240617
猜你喜欢
转载自blog.csdn.net/weixin_38240095/article/details/84240617
今日推荐
周排行