在这次的练习中,我们将实现一对多的逻辑回归和手写识别神经网络比较两者的准确性。
需要进行修改的脚本有

在ex3datal .mat中有5000个训练示例,每个训练示例都是一个20像素×20像素的数字灰度图像。每个像素用浮点数表示该位置的灰度强度。20×20的像素网格被“展开”成一个400维的向量。这些训练示例中的每一个都变成了datamatrix X中的一行,这就得到了一个5000×400矩阵X,其中每一行都是一个手写数字图像的训练示例。
Ircostfunction.m
function [J, grad] = lrCostFunction(theta, X, y, lambda)
%LRCOSTFUNCTION Compute cost and gradient for logistic regression with
%regularization
% J = LRCOSTFUNCTION(theta, X, y, lambda) computes the cost of using
% theta as the parameter for regularized logistic regression and the
% gradient of the cost w.r.t. to the parameters.
% Initialize some useful values
m = length(y); % number of training examples
% You need to return the following variables correctly
J = 0;
grad = zeros(size(theta));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost of a particular choice of theta.
% You should set J to the cost.
% Compute the partial derivatives and set grad to the partial
% derivatives of the cost w.r.t. each parameter in theta
%
% Hint: The computation of the cost function and gradients can be
% efficiently vectorized. For example, consider the computation
%
% sigmoid(X * theta)
%
% Each row of the resulting matrix will contain the value of the
% prediction for that example. You can make use of this to vectorize
% the cost function and gradient computations.
%
% Hint: When computing the gradient of the regularized cost function,
% there're many possible vectorized solutions, but one solution
% looks like:
% grad = (unregularized gradient for logistic regression)
% temp = theta;
% temp(1) = 0; % because we don't add anything for j = 0
% grad = grad + YOUR_CODE_HERE (using the temp variable)
%
J = 1/m * (-y' * log(sigmoid(X*theta)) - (1 - y')* log(1-sigmoid(X*theta))) + lambda/2/m*sum(theta(2:end) .^ 2);
grad(1, :) = 1/m * (X(:,1)'* (sigmoid(X*theta) - y));
grad(2:end, :) = 1/m * (X(:,2:end)'* (sigmoid(X*theta) - y)) + lambda/m*theta(2:end, :);
% =============================================================
grad = grad(:);
end
oneVsall.m
function [all_theta] = oneVsAll(X, y, num_labels, lambda)
%ONEVSALL trains multiple logistic regression classifiers and returns all
%the classifiers in a matrix all_theta, where the i-th row of all_theta
%corresponds to the classifier for label i
% [all_theta] = ONEVSALL(X, y, num_labels, lambda) trains num_labels
% logistic regression classifiers and returns each of these classifiers
% in a matrix all_theta, where the i-th row of all_theta corresponds
% to the classifier for label i
% Some useful variables
m = size(X, 1);
n = size(X, 2);
% You need to return the following variables correctly
all_theta = zeros(num_labels, n + 1);
% Add ones to the X data matrix
X = [ones(m, 1) X];
% ====================== YOUR CODE HERE ======================
% Instructions: You should complete the following code to train num_labels
% logistic regression classifiers with regularization
% parameter lambda.
%
% Hint: theta(:) will return a column vector.
%
% Hint: You can use y == c to obtain a vector of 1's and 0's that tell you
% whether the ground truth is true/false for this class.
%
% Note: For this assignment, we recommend using fmincg to optimize the cost
% function. It is okay to use a for-loop (for c = 1:num_labels) to
% loop over the different classes.
%
% fmincg works similarly to fminunc, but is more efficient when we
% are dealing with large number of parameters.
%
% Example Code for fmincg:
%
% % Set Initial theta
% initial_theta = zeros(n + 1, 1);
%
% % Set options for fminunc
% options = optimset('GradObj', 'on', 'MaxIter', 50);
%
% % Run fmincg to obtain the optimal theta
% % This function will return theta and the cost
% [theta] = ...
% fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
% initial_theta, options);
%
for c = 1:num_labels %num_labels 为逻辑回归训练器的个数 为啥不直接写10呢
initial_theta = zeros(n + 1, 1);
options = optimset('GradObj', 'on', 'MaxIter', 50);
[theta] = fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), initial_theta, options);
all_theta(c,:)=theta';
% =========================================================================
end
下面来解释一下 for循环:(救命一样的点醒了我)
num_labels 为分类器个数,共10个,每个分类器(模型)用来识别10个数字中的某一个。
我们一共有5000个样本,每个样本有400中特征变量,因此:模型参数θ 向量有401个元素。
initial_theta = zeros(n + 1, 1); % 模型参数θ的初始值(n == 400)
all_theta是一个10*401的矩阵,每一行存储着一个分类器(模型)的模型参数θ 向量,执行上面for循环,就调用fmincg库函数求出了 所有模型的参数θ 向量了。
求出了每个模型的参数向量θ,就可以用 训练好的模型来识别数字了。对于一个给定的数字输入(400个 feature variables) input instance,每个模型的假设函数hθ(i)(x) 输出一个值(i = 1,2,...10)。取这10个值中最大值那个值,作为最终的识别结果。比如g(hθ(8)(x))==0.96 比其它所有的 g(hθ(i)(x)) (i = 1,2,...10,但 i 不等于8) 都大,则识别的结果为 数字 8
在训练了one-vs-all分类器之后,现在可以使用它来预测给定图像中包含的数字。对于每个输入,应该使用经过训练的逻辑回归分类器计算它属于每个类的“概率”。one-vs-all预测函数将选择对应逻辑回归分类器输出最高概率的类,并返回类标签(1,2,…,或K)作为输入示例的预测。
predictonevsall.m
function p = predictOneVsAll(all_theta, X)
%PREDICT Predict the label for a trained one-vs-all classifier. The labels
%are in the range 1..K, where K = size(all_theta, 1).
% p = PREDICTONEVSALL(all_theta, X) will return a vector of predictions
% for each example in the matrix X. Note that X contains the examples in
% rows. all_theta is a matrix where the i-th row is a trained logistic
% regression theta vector for the i-th class. You should set p to a vector
% of values from 1..K (e.g., p = [1; 3; 1; 2] predicts classes 1, 3, 1, 2
% for 4 examples)
m = size(X, 1);
num_labels = size(all_theta, 1);
% You need to return the following variables correctly
p = zeros(size(X, 1), 1);
% Add ones to the X data matrix
X = [ones(m, 1) X];
% ====================== YOUR CODE HERE ======================
% Instructions: Complete the following code to make predictions using
% your learned logistic regression parameters (one-vs-all).
% You should set p to a vector of predictions (from 1 to
% num_labels).
%
% Hint: This code can be done all vectorized using the max function.
% In particular, the max function can also return the index of the
% max element, for more information see 'help max'. If your examples
% are in rows, then, you can use max(A, [], 2) to obtain the max
% for each row.
%
temp = all_theta * X';
[maxx, pp] = max(temp);
p = pp';
% =========================================================================
end
Y是返回最大值的,I是返回最大值的位置的。
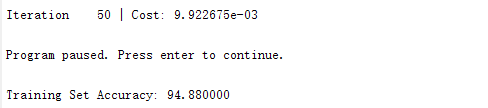
运行结果 94.88
第二部分
在这部分练习中,您将实现一个神经网络,使用与前面相同的训练集识别手写数字。神经网络将能够表示形成非线性假设的复杂模型。本周,你们将使用我们已经训练过的神经网络的参数。您的目标是实现前馈传播算法来使用我们的权重进行预测。
我们的输入是数字图像的像素值。自图像大小20×20,这给了我们400个输入层单位(不包括额外的偏见单位总输出+ 1)。和之前一样,训练数据将被加载到变量X和y。你已经提供了一组网络参数(Θ(1)Θ(2)),我们已经训练。它们存储在ex3weights中。将由ex3nn加载。这些参数的尺寸是为第二层25个单元和10个输出单元(对应于10位类)的神经网络设计的。
接下来的代码我要用python来实现啦 ,下次见