本文记录一下我在看FPN这篇paper的时候已经自己用的时候的一些问题。本文中有些摘抄自别人的博客,如有侵权,望联系我删除。
FPN的一个github:https://github.com/unsky/FPN
一、介绍

老样子先上图,图d即为FPN的核心。
二、具体实现方法
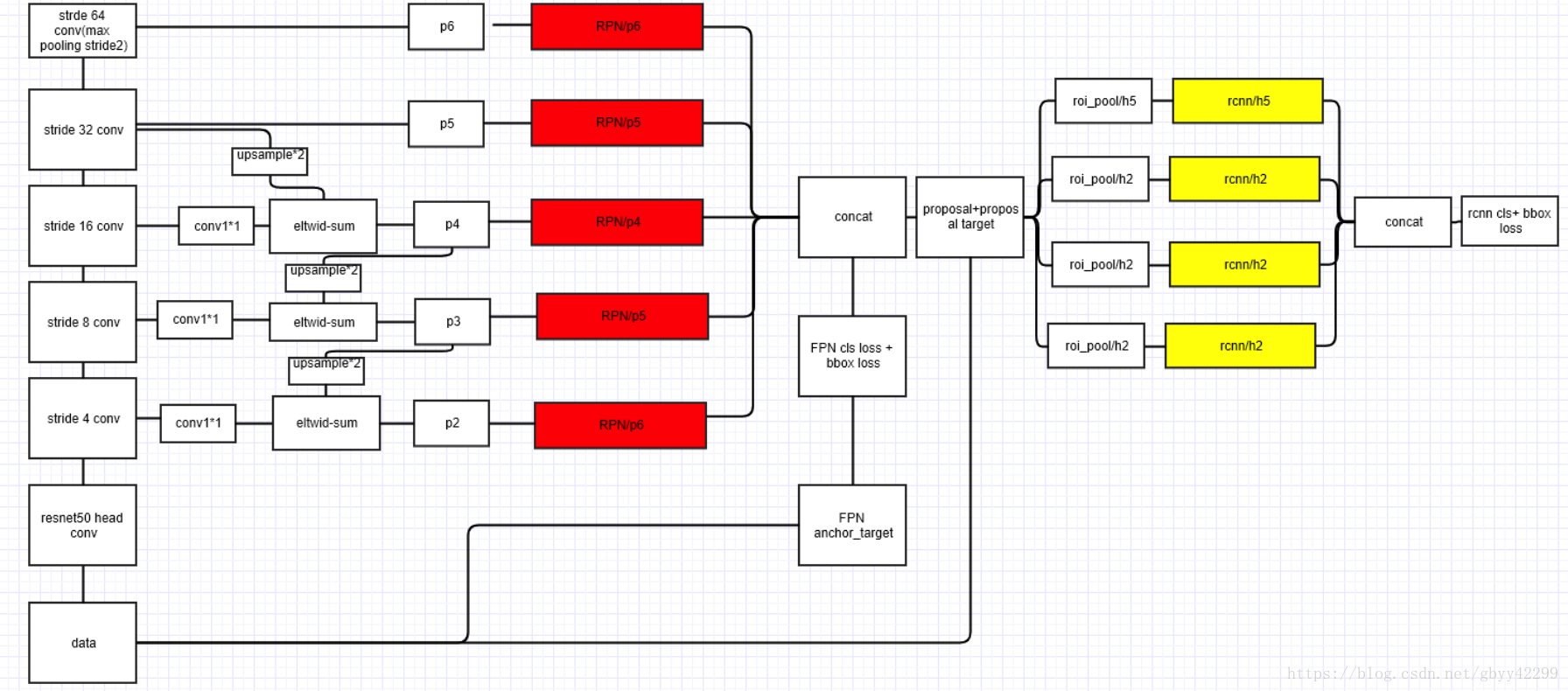
- 将图片送入预训练的特征网络中(如ResNet等),即构建所谓的bottom-up网络;
- 构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作)。如下图down-top其实就是把每个residual block(C1去掉了,因为浅层语义信息不够并且feature map较大很消耗内存)的scale通过卷积的stride=2进行缩小2倍,即:C2,C3,C4,C5(1/4, 1/8, 1/16, 1/32)。top-down就是把高层的低分辨率的语义信息的feature进行上采样2x。lateral conn就是用来调整channel和top-down过来的一样让其可以相加。通过上述操作一直迭代到生成最好分辨率的feature(此处指C2) ;
- 接着,在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作;
- 接着,将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(固定为7x7的特征);
- 最后,在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层;


三、RPN
每个level的feature P2,P3,P4,P5,P6只对应一种scale,比例还是3个比例。
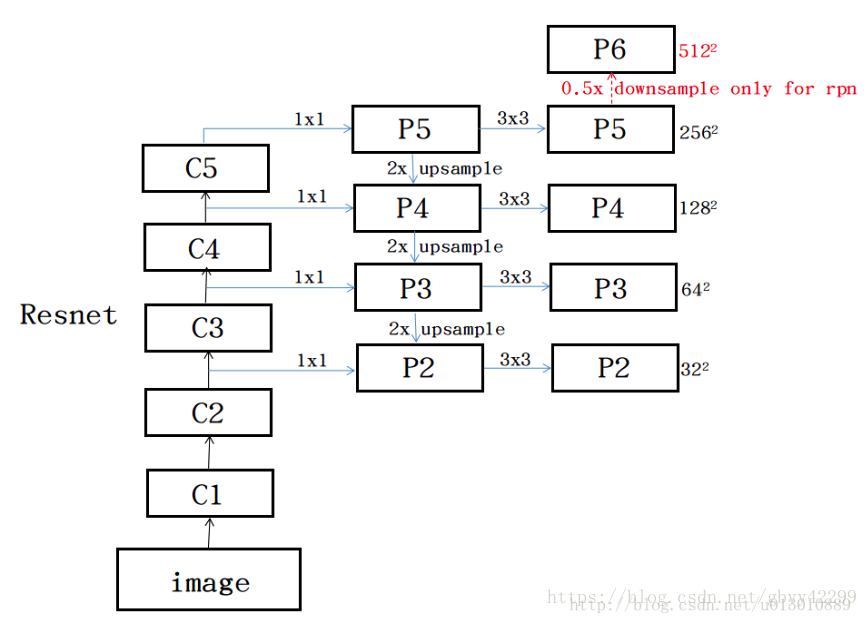
k0是faster rcnn时在哪取的feature map如resnet那篇文章是在C4取的,k0=4(C5相当于fc,也有在C5取的,在后面再多添加fc),比如roi是w/2,h/2,那么k=k0-1=4-1=3。
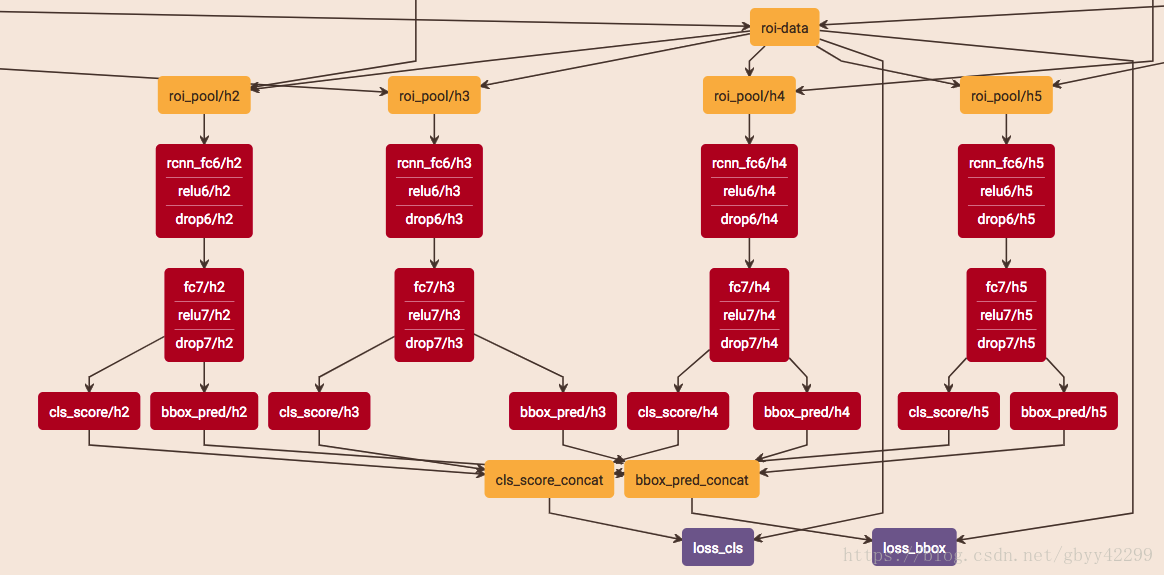
四、FPN的两种构架
第一种为megred rcnn:

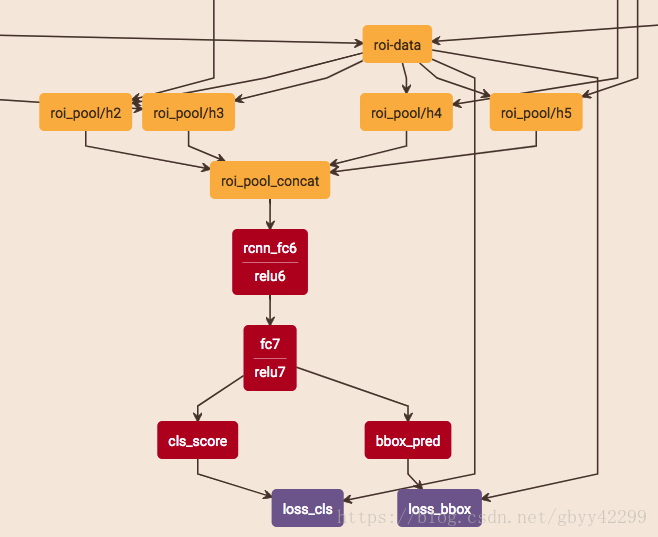
第二种为shared rcnn: