FPN与Retina Net个人理解
Retina Net前的目标检测网络存在的问题及原因:
- one-stage 算法如YOLO系列速度快但精度不够高
- 原因:训练过程中类别分布不平衡,容易受到大量简单样本的支配
- two-stage算法如Faster RCNN精度高但是速度不够快
- 原因: 两次的预测降低了速度
FPN网络的发展演变
- CNN:直接使用最后一层特征图
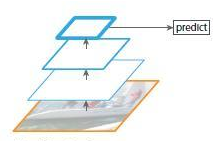
- 上述方法会丢失一些细节特征,因为不同层会提供不同的图片特征,于是想到利用不同尺度图像的特征,进行训练、测试
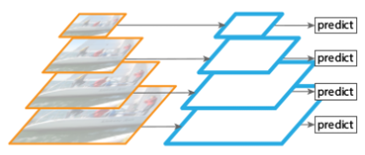
将图片缩放成多种比例,每个比例的单独提取特征 - 为了节约时间,可以在上述思想下直接利用特征图
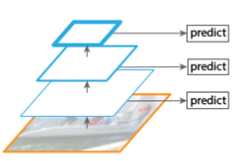
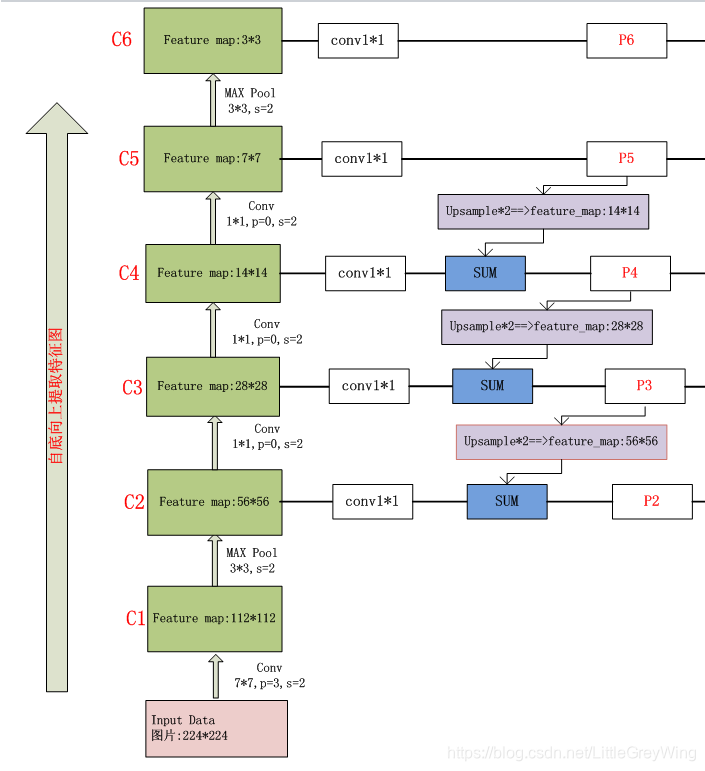
- FPN网络则更加复杂一些,它在获得了各层特征图之后还进行回传,进行上采样,并且和原来正向传播的特征图进行相加,实现特征的融合。
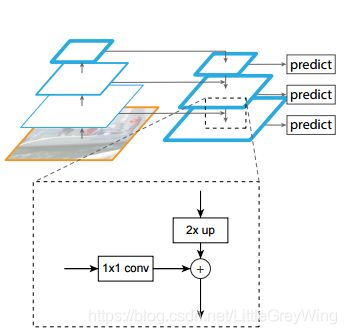
简单来说就是把高层的特征进行上采样(最邻近上采样),把上采样后得到的特征横向连接至前一层特征,这样就将特征进行了加强,横向连接的具体操作就是对应元素间的相加,于是这要求两个矩阵的维度完全一样。
为了实现这样完全一样的矩阵,横向连接时左边的矩阵要先经过1*1的卷积增加通道数,这是因为进行上采样的特征图在之前经过了卷积,因此通道数会和横向连接的左边的特征图不一致,二者完全一致后就可以进行相加操作了。(可以参考下图)
Retina Net
-
网络结构:了解了FPN结构后再接触Retina Net就显得很简单了,他的主网络就是FPN网络,而对于每一个特征图的输出又采取了两个子网络分别进行分类和回归任务。
-
hard/easy positive/negative examples
在说明损失函数前先说明一下examples的概念
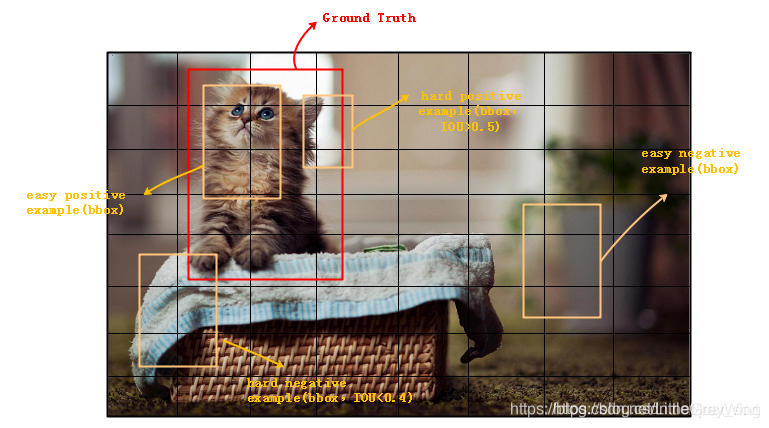
观察上图,可以知道hard examples是难以分辨的例子,easy examples则容易辨别;positive examples和negative examples则是正负样本
此时再考虑为什么one-stage精度低,因为negative example过多(背景),导致它的loss过大,以至于主导了损失函数,不利于收敛。虽然大部分背景图不在物体和背景上的过渡区域,也就是很容易辨别,但是架不住数量众多啊,于是影响了我们想要关注的hard examples对loss的贡献。
另外Faster RCNN在使用FPN阶段时会根据前景分数提出最可能是前景的example,滤除掉大量背景概率高的easy example,但是速度就会慢一些 -
损失函数
Retina Net的损失函数是Focal Loss
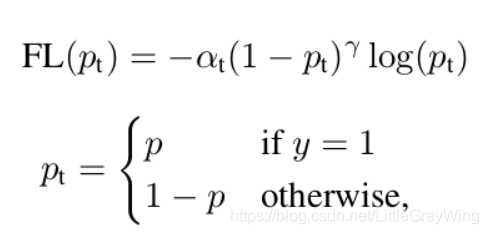
先看一下他以前的版本损失函数是怎么样的:
- 计算分类时的传统loss:交叉熵公式像下面这样:
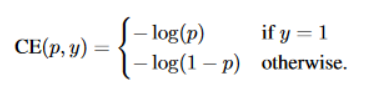
其中y=1表明这个候选框是一个物体而不是背景,而为了解决正负样本数量不均则会加一个系数来平衡,就变成了下面这样:
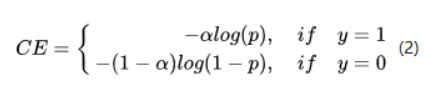
但是现在只解决了positive 和 negative example不均的问题,没有解决hard 和easy example 的不均问题。其实本来easy example就可以很方便地被检测出来。应该关注的是hard example的效果,对着已经可以检测出来的easy example来进行效果上的提升,最终模型训练的效果也就不明显,模型应该主要关注那些难于分类的样本,这才能提升自己。那么想法就是在loss上再加上点什么平衡一下head和easy example的数量影响:

假设gamma = 2,那么p=0.9那么(1-0.9)平方后就是0.001,那么easy example 的权重被大幅减小,另外还不要忘记对positive 和 negative example的关心,于是最终版本如下:
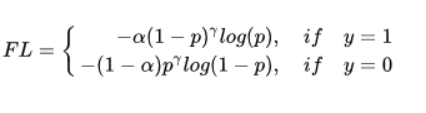
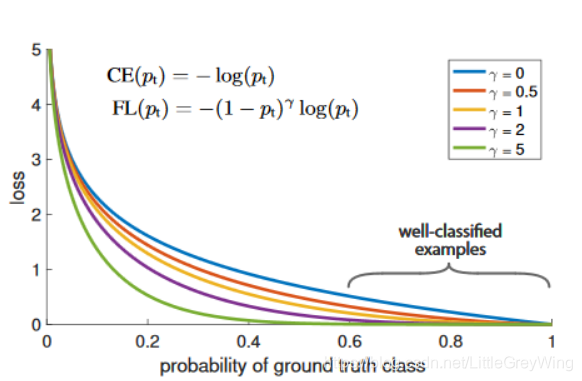
由下面这张图可以看出来,损失已经被hard example主导了
参考资料
目标检测算法之RetinaNet(引入Focal Loss)
学习FPN和retinanet的网络结构
FPN 学习笔记