版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_30500113/article/details/83752015
爬取起点中文网免费小说
小说链接:https://book.qidian.com/info/1012136018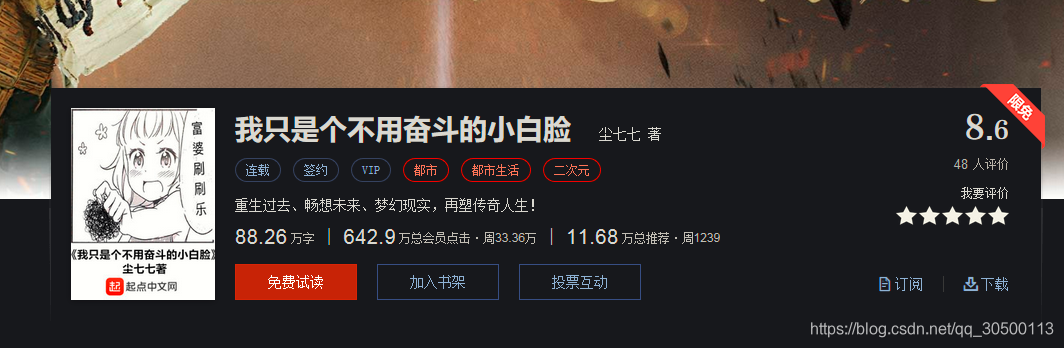
起点中文网是我很喜欢的一个网站,那么学完Python爬虫后我们来试着爬取一本起点的小说吧
面向纯小白的代码
环境:python3.6 ,解析使用pyquery
爬一本小说有个思路,有了这个思路, 你可以爬任意一本想看的小说,所以说代码不是关键,思路才是最重要的
思路如下:
- 确定请求的链接 :https://book.qidian.com/info/1012136018
- 获取全部章节的链接
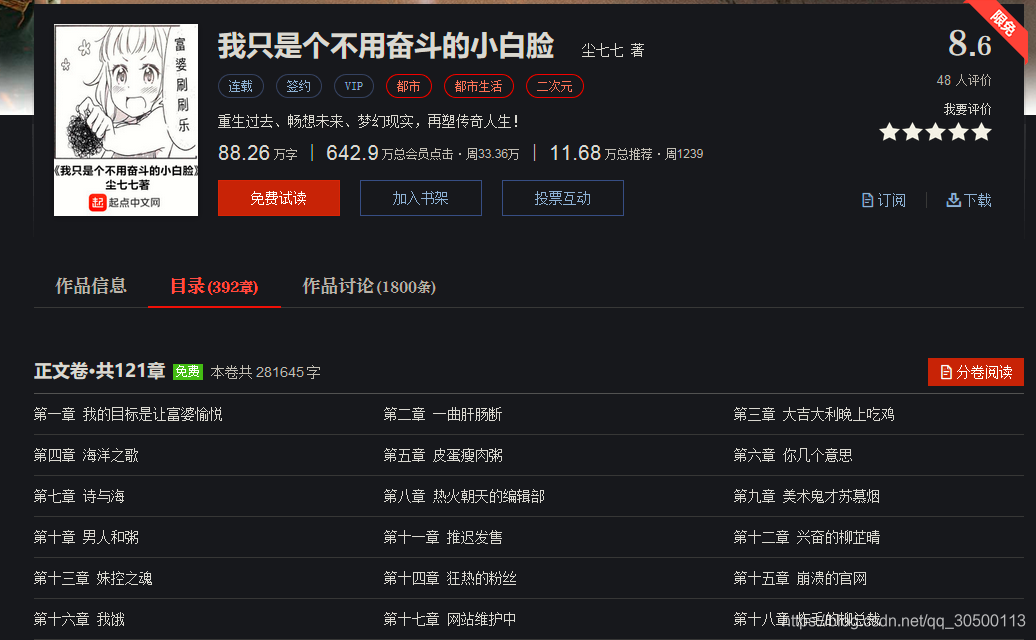
- 请求每一章的链接,获取小说内容
- 将要保存的内容写入文件
ok 且看代码注释:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/11/5 15:42
# @Desc : 爬起点小说
import requests
from pyquery import PyQuery as pq
# 这里我使用了代理 你可以去掉这个代理IP 不要一股脑复制代码
headers = {
'proxy': 'https: 219.135.169.85:47315',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
def start_request(url):
"""请求链接 获得源码"""
r = requests.get(url)
return r.text
def parse(text):
"""解析页面 获得内容并写入文件"""
doc = pq(text)
links = doc('div.volume-wrap ul li a').items()
for link in links:
# 获取每章标题
title = link.text()
# 获取章节链接
href = 'http:' + link.attr('href')
# 请求每章页面 获得源码
down_page = start_request(href)
doc = pq(down_page)
# 每一章小说内容
content = doc('div.read-content').text()
# 写入txt文件
with open('我只是个不用奋斗的小白脸.txt', 'a+', encoding='utf8') as f:
f.write(title+'\n')
f.write(content+'\n\n')
print("正在写入"+title)
print("写入完成")
def main():
url = 'https://book.qidian.com/info/1012136018#Catalog'
text = start_request(url)
parse(text)
if __name__ == "__main__":
main()
运行程序:

好啦 来看下我们的小说是不是保存到txt文件呢:

