(一)项目目标
本次要练习的目标时起点中文网里面的免费小说。
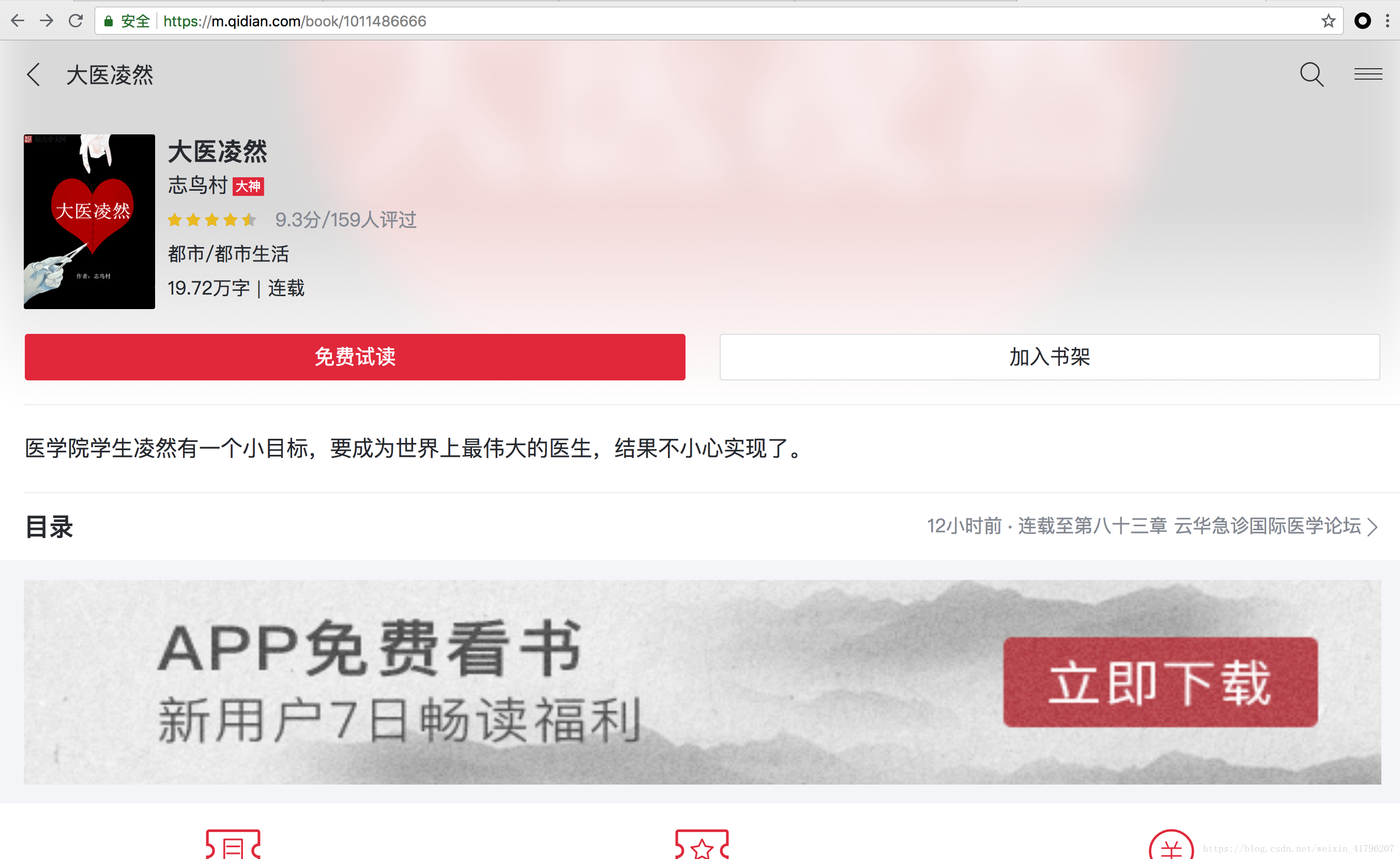
1. 如下图,找到免费小说的目录:

2. 点击更多后,随便找一本免费小说打开:
3. 点击中间的目录按钮,进入小说目录:
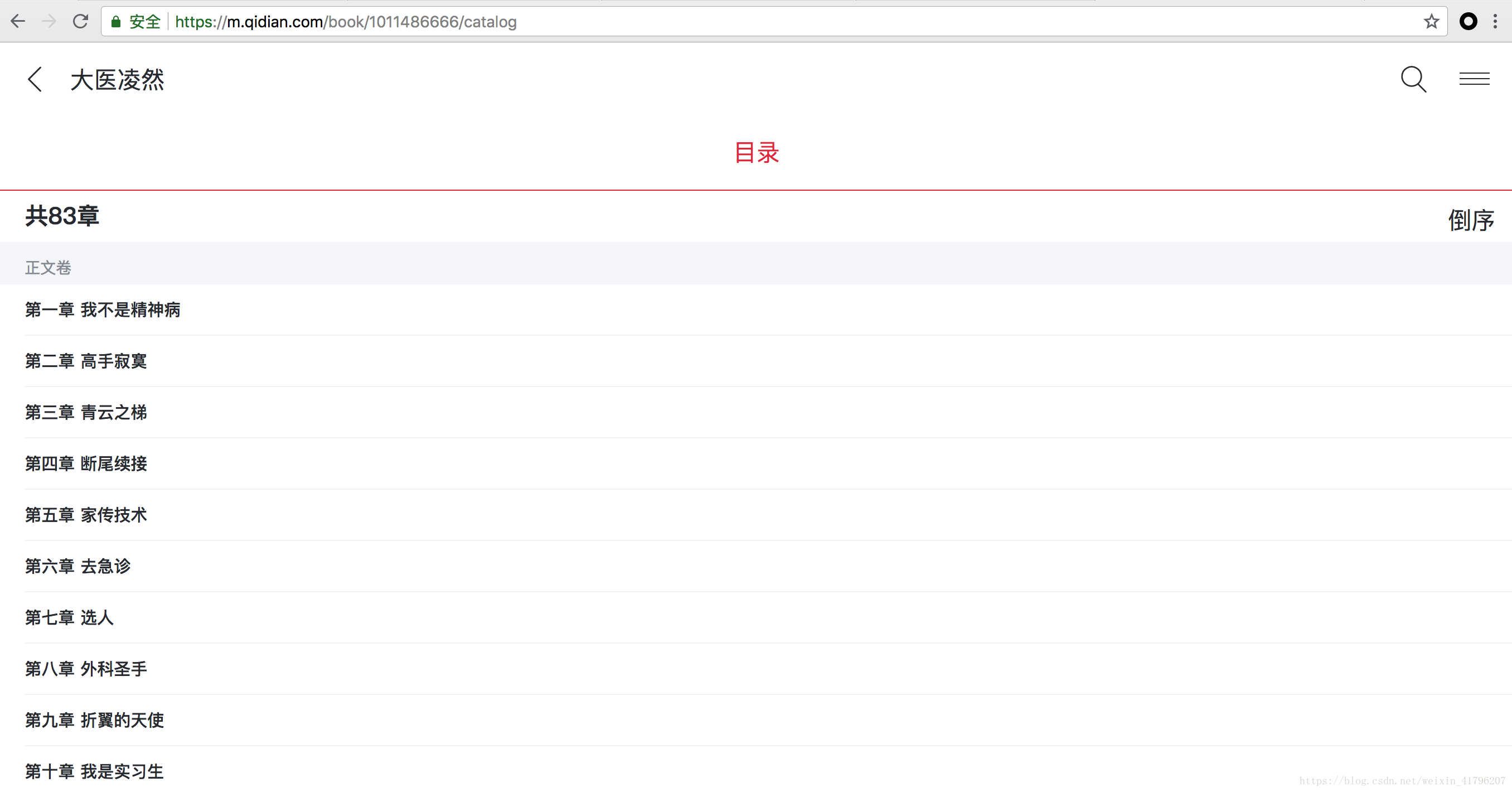
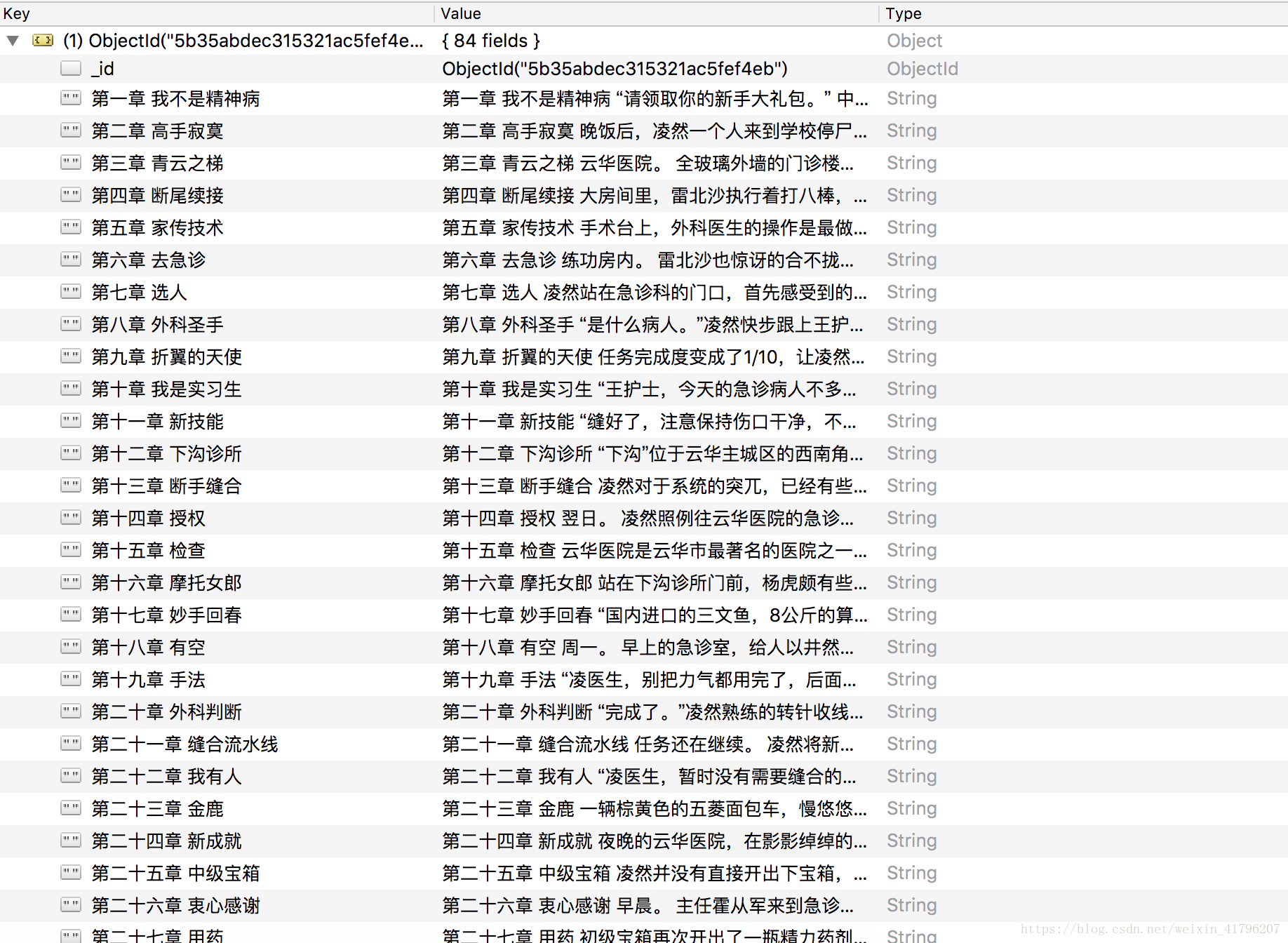
可以看到,该小说一共有83章,这就是本次目标。
(二)网页分析
1. 在目录页中点击一章,进入阅读页面,并同时检查网络,查看内容来源。
请注意下图中标注的三个部分:
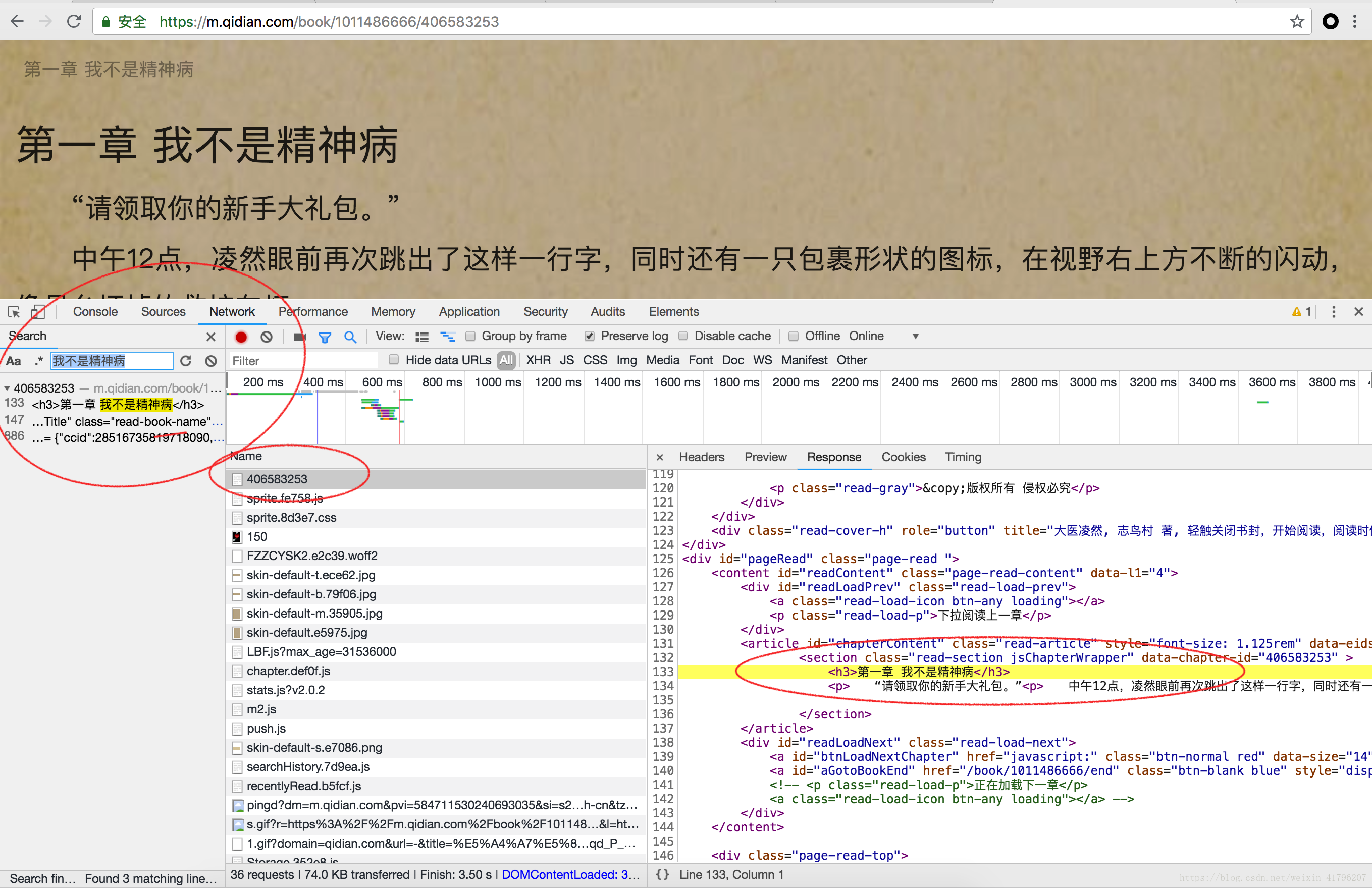
2. 这样,我们找到了获取内容的请求。下面仔细分析该请求:
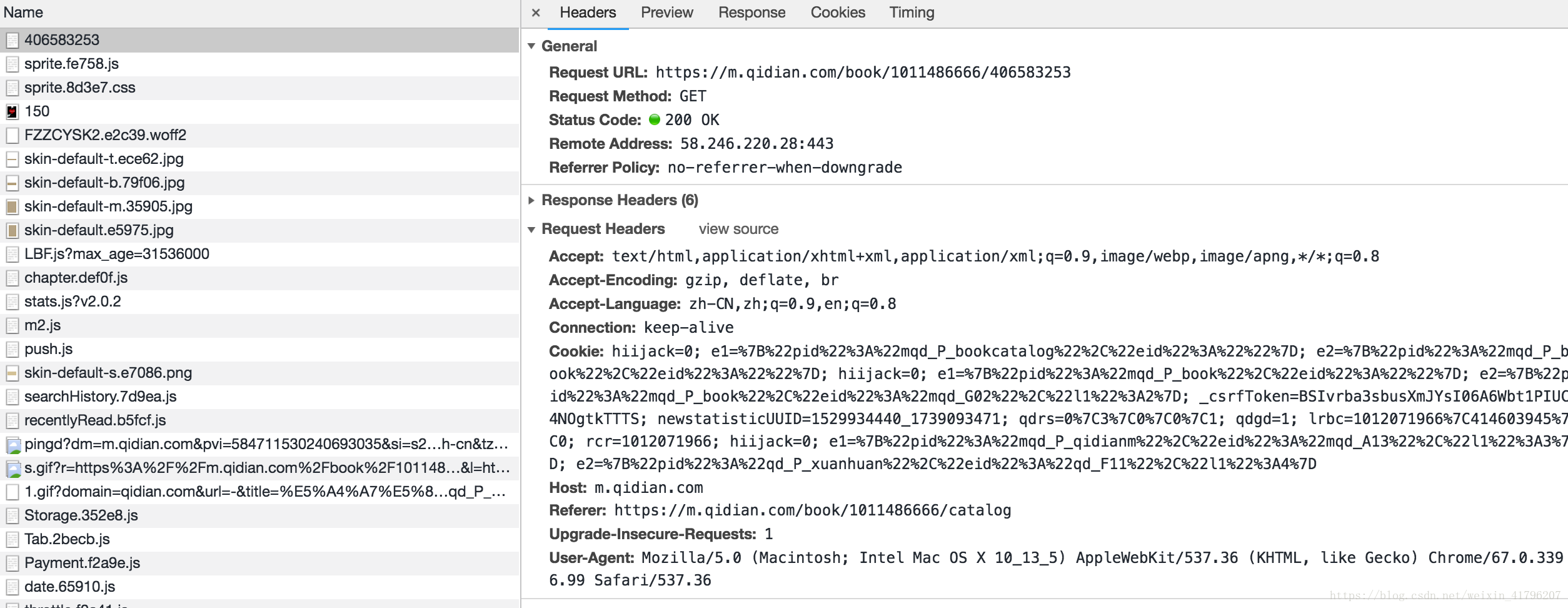
从上面截图可以看到,请求的类型是GET,url与页面url相同。
这样,只要通过页面url就能拿到小说这一章的数据。
那么,其他章的url从哪里可以获取呢?
3. 还是回到最初的目录页,审查元素,发现其中包含了所有章节的相对url。

4. 至此,网页分析完毕。思路如下:
- 通过目录页,拿到所有章节页面url
- 通过章节页面url,拿到小说原文。
(三) 核心代码实现
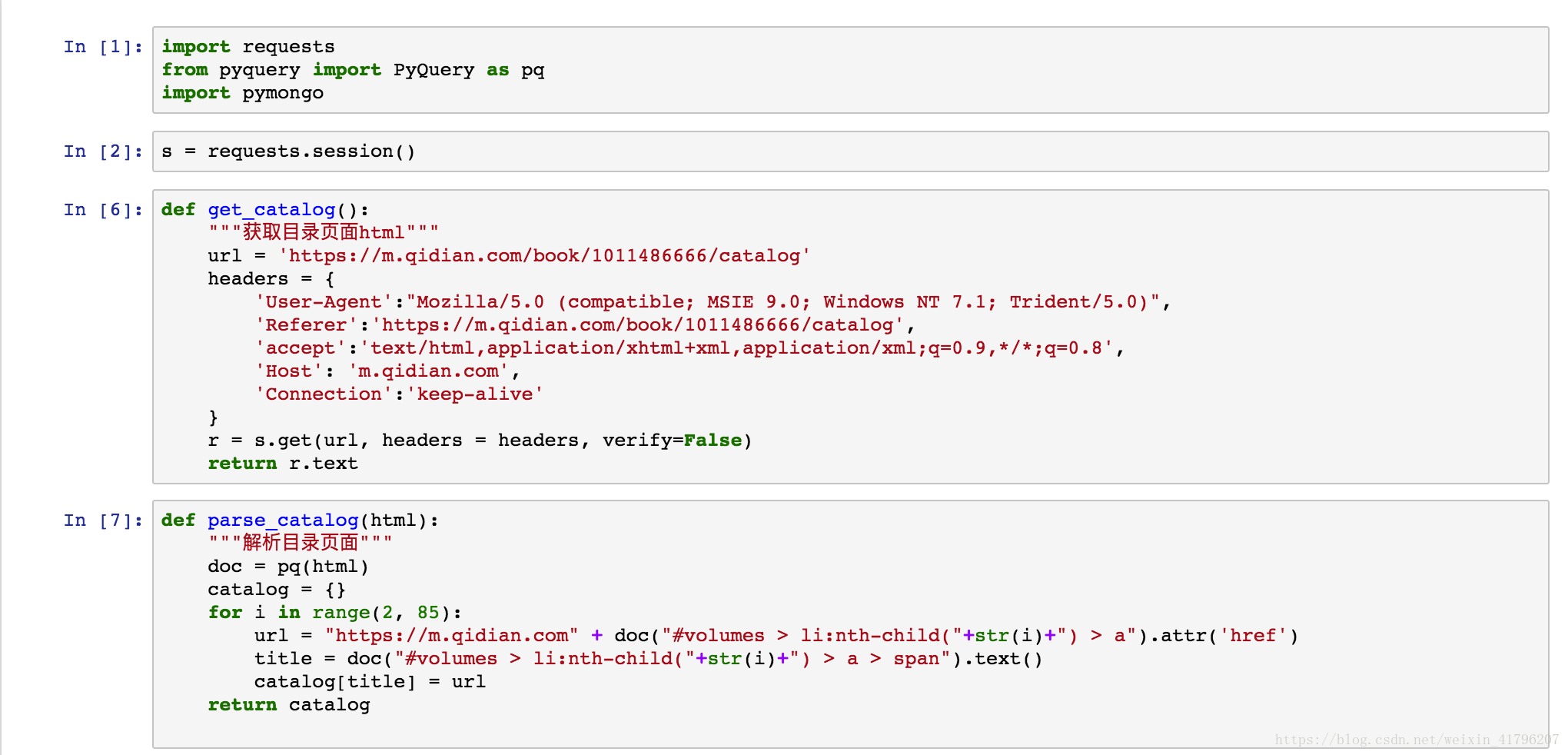
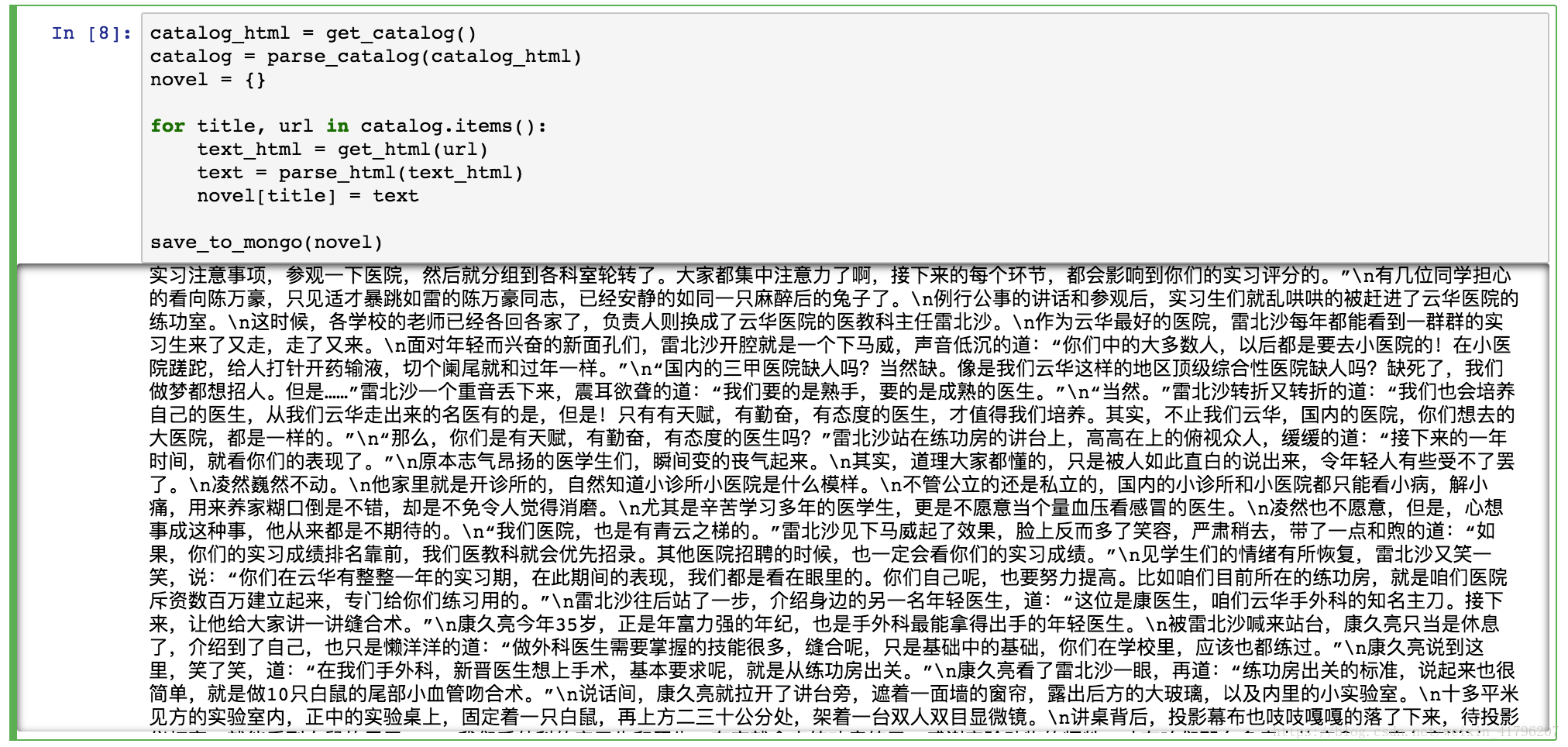
本次代码比较简单,我是直接用jupyter写的,下面将jupyter代码页面直接粘贴如下:

(四)结果展示
由于内容不多,大概程序在20秒左右执行完毕,打开Mongodb查看,爬取结果如下: