1.残差网络
1)网络结构
当对x求偏导的时候,F(x)对x求偏导的值很小的时候,对整体求x的偏导会接近于1

这样解决了梯度消失问题,我们可以对离输入很近的层进行很好的更新。
要注意的是F(x)与x的张量维度是相同的。

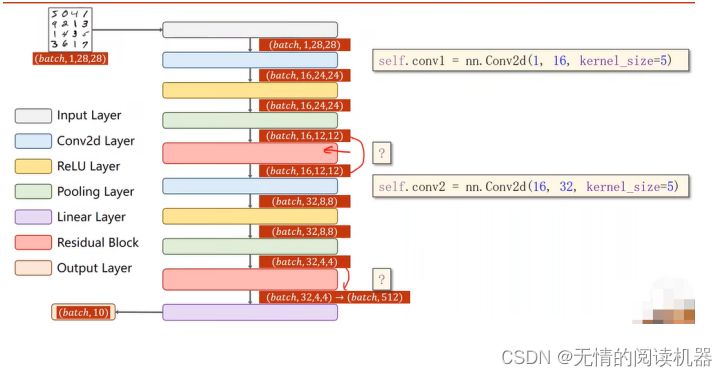
2)代码
import torch
from torchvision import transforms #对图像做原始处理的工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root = './data',train = True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle = True ,batch_size = batch_size)
test_dataset = datasets.MNIST(root = './data',train = False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle = False ,batch_size = batch_size)class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x+y)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,16,kernel_size=5)
self.conv2 = torch.nn.Conv2d(16,32,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = torch.nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.pooling(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1) #flatten
x = self.fc(x)
return xmodel = Net()criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)def train(epoch):
running_loss = 0.0
model.train()
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
#print(inputs.shape)
optimizer.zero_grad()
#向前传播
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' %(epoch +1 ,batch_idx+1,running_loss/300))
running_loss = 0.0for epoch in range(10):
train(epoch)2.Googlenet
1)网络结构
模型出发点:不知道哪个卷积核尺寸最好,所有就需要不同的卷积核求特征图,然后将特征图进行拼接。
注意:每个卷积层产生的特征图,c可以不一样,但是w,h要一样。
我们来看一下1*1的卷积核
这个明显更像是加权求和形式的一种信息融合。每个像素点的信息都不包含其他临近像素的信息。
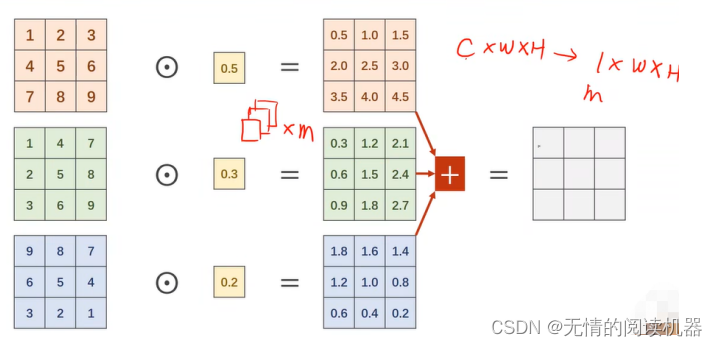
核心网络结构
2)核心代码
class InceptionA(nn.Module):
def __init__(self,in_channels):
super(InceptionA,self).__init__()
self.branch1x1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool = nn.Conv2d(in_channels,24,kernel_size=1)
def forward(self,x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(88,20,kernel_size=5)
self.incep1 = InceptionA(in_channels = 10)
self.incep2 = InceptionA(in_channels = 20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408,10)
def forward(self,x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size,-1)
s = self.fc(x)
return x
model = Net()3.mobilenet
1)网络结构
该模型用到了深度分离卷积, 该卷积可以分成两步Depthwise Convolution和Pointwise Convolution两部分构成。

Depthwise Convolution的计算非常简单,它对输入feature map的每个通道分别使用一个卷积核,然后将所有卷积核的输出再进行拼接得到它的最终输出。因为卷积操作的输出通道数等于卷积核的数量,而Depthwise Convolution中对每个通道只使用一个卷积核,所以单个通道在卷积操作之后的输出通道数也为1。那么如果输入feature map的通道数为N(如图1.1所示),对N个通道分别单独使用一个卷积核之后便得到N个通道为1的feature map。再将这N个feature map按顺序拼接便得到一个通道为N的输出feature map。
Pointwise Convolution实际为1×1卷积,在DSC中它起两方面的作用。第一个作用是让DSC能够自由改变输出通道的数量;第二个作用是对Depthwise Convolution输出的feature map进行通道融合。



2)核心代码
class MobileNet(nn.Module):
def __init__(self,inp,oup,stride):
super(MobileNet,self).__init__()
self.dw = torch.nn.Conv2d(inp,inp,kernel_size=3,stride=stride,padding=1,groups=inp,bias=False)
self.bn1 = torch.nn.BatchNorm2d(inp)
self.pw = torch.nn.Conv2d(inp,oup,kernel_size=1,stride=1,padding=0,bias=False)
self.bn2 = torch.nn.BatchNorm2d(oup)
def forward(self,x):
x = F.relu(self.bn1(self.dw(x)))
x = F.relu(self.bn2(self.pw(x)))
return xclass Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1,32,kernel_size=3,stride=2,padding=1,bias=False)
self.bn1 = torch.nn.BatchNorm2d(32)
self.m1 = MobileNet(32,64,1)
self.m2 = MobileNet(64,128,2)
self.m3 = MobileNet(128,128,1)
self.mp = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(128,10)
def forward(self,x):
in_size = x.size(0)
x = F.relu(self.bn1(self.conv1(x)))
x = self.m1(x)
x = self.m2(x)
x = self.m3(x)
print(x.shape)
x = self.mp(x)
x = x.view(in_size,-1)
x = self.fc(x)
return x
model = Net()4.SqueezeNet
1)网络结构
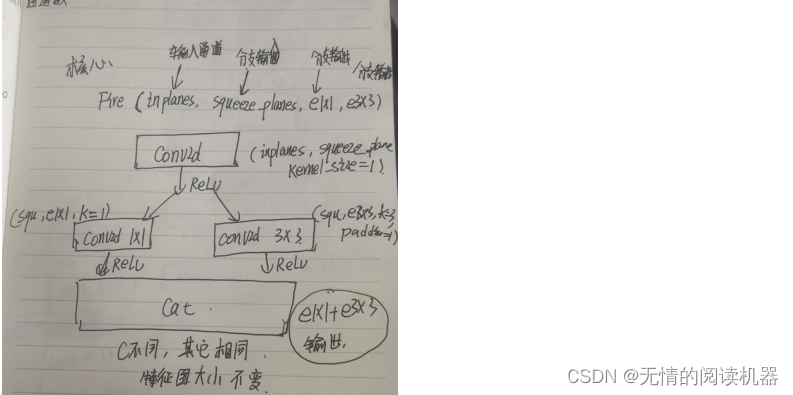

2)核心代码
class Fire(torch.nn.Module):
def __init__(self,inp,squ_outp,e1x1_outp,e3x3_outp):
super(Fire,self).__init__()
self.squeeze = torch.nn.Conv2d(inp,squ_outp,kernel_size=1)
self.conve1x1 = torch.nn.Conv2d(squ_outp,e1x1_outp,kernel_size=1)
self.conve3x3 = torch.nn.Conv2d(squ_outp,e3x3_outp,kernel_size=3,padding=1)
def forward(self,x):
x = F.relu(self.squeeze (x))
x1 = F.relu(self.conve1x1(x))
x3 = F.relu(self.conve3x3(x))
return torch.cat([x1,x3],1)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,32,kernel_size=3,stride=2)
self.fire1 = Fire(32,16,64,64)
self.fire2 = Fire(128,16,64,64)
self.fire3 = Fire(128,16,64,64)
self.final_conv = torch.nn.Conv2d(128,10,kernel_size=1)
self.classifier = torch.nn.Sequential(
torch.nn.Dropout(p=0.5),
self.final_conv,
torch.nn.ReLU(inplace=True),
torch.nn.AdaptiveAvgPool2d((1, 1))
)
self.pooling = torch.nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode=True)
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.fire1(x)
x = self.pooling(self.fire2(x))
x = self.fire3(x)
x = self.classifier(x)
return torch.flatten(x, 1)
model = Net()5.ShuffleNet
1)利用矩阵的转置进行Shuffle(通道重排)
首先看一个简单的例子
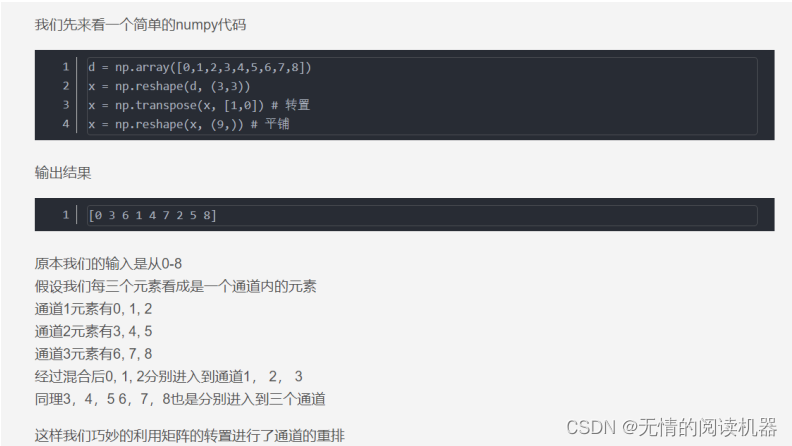
实现通道重排的代码如下:
 效果如下:将每个组特征图打乱(每个组是三个特征图)
效果如下:将每个组特征图打乱(每个组是三个特征图)
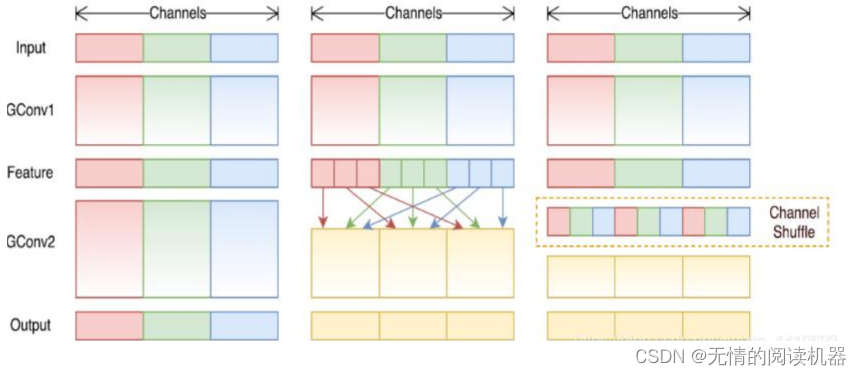
2)分组卷积
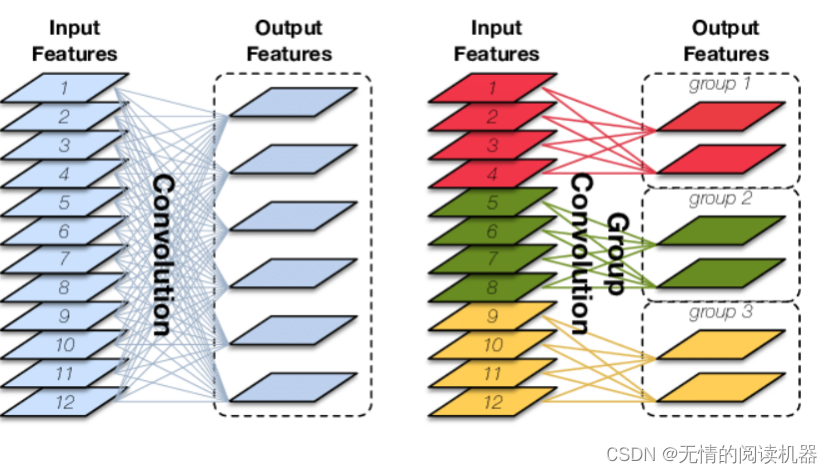
3)核心单元SHUFFLENETUNIT

ShuffleNet的基本单元是在一个残差单元的基础上改进而成的。如图a所示,这是一个包含3层的残差单元:首先是1x1卷积,然后是3x3的depthwise convolution(DWConv,主要是为了降低计算量),这里的3x3卷积是瓶颈层(bottleneck),紧接着是1x1卷积,最后是一个短路连接,将输入直接加到输出上。
现在,进行如下的改进:
将密集的1x1卷积替换成1x1的group convolution,不过在第一个1x1卷积之后增加了一个channel shuffle操作。值得注意的是3x3卷积后面没有增加channel shuffle,按paper的意思,对于这样一个残差单元,一个channel shuffle操作是足够了。还有就是3x3的depthwise convolution之后没有使用ReLU激活函数。改进之后如图b所示。
对于残差单元,如果stride=1时,此时输入与输出shape一致可以直接相加,而当stride=2时,通道数增加,而特征图大小减小,此时输入与输出不匹配。一般情况下可以采用一个1x1卷积将输入映射成和输出一样的shape。但是在ShuffleNet中,却采用了不一样的策略,如图c所示:对原输入采用stride=2的3x3 avg pool,这样得到和输出一样大小的特征图,然后将得到特征图与输出进行连接(concat),而不是相加。这样做的目的主要是降低计算量与参数大小。



总结一下,unitA输出的shape和输入x的shape是一样的。
unitB通道数有变化,特征图大小缩小了一半。
4)核心代码
def shuffle_channels(x, groups):
"""shuffle channels of a 4-D Tensor"""
batch_size, channels, height, width = x.size()
assert channels % groups == 0
channels_per_group = channels // groups
# split into groups
x = x.view(batch_size, groups, channels_per_group,
height, width)
# transpose 1, 2 axis
x = x.transpose(1, 2).contiguous()
# reshape into orignal
x = x.view(batch_size, channels, height, width)
return xclass ShuffelUnitA(torch.nn.Module):
def __init__(self,in_channels, out_channels, groups=3):
super(ShuffelUnitA,self).__init__()
assert in_channels == out_channels
assert out_channels % 4 == 0
bottleneck_channels = out_channels // 4
self.groups = groups
self.group_conv1x1_1 = nn.Conv2d(in_channels, bottleneck_channels,kernel_size=1, groups=groups, stride=1)
self.bn1 = nn.BatchNorm2d(bottleneck_channels)
self.depthwise_conv = nn.Conv2d(bottleneck_channels,bottleneck_channels,kernel_size=3, padding=1, stride=1,groups=bottleneck_channels)
self.bn2 = nn.BatchNorm2d(bottleneck_channels)
self.group_conv1x1_2 = nn.Conv2d(bottleneck_channels, out_channels,kernel_size=1, groups=groups, stride=1)
self.bn3 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.group_conv1x1_1(x)
out = F.relu(self.bn1(out))
out = shuffle_channels(out,groups=self.groups)
out = self.depthwise_conv(out)
out = self.bn2(out)
out = self.group_conv1x1_2(out)
out = self.bn3(out)
out = F.relu(x+out)
return out
class ShuffelUnitB(torch.nn.Module):
def __init__(self,in_channels, out_channels, groups=3):
super(ShuffelUnitB,self).__init__()
out_channels -= in_channels
assert out_channels % 4 == 0
bottleneck_channels = out_channels // 4
self.groups = groups
self.group_conv1x1_1 = nn.Conv2d(in_channels, bottleneck_channels,kernel_size=1, groups=groups, stride=1)
self.bn1 = nn.BatchNorm2d(bottleneck_channels)
self.depthwise_conv = nn.Conv2d(bottleneck_channels,bottleneck_channels,kernel_size=3, padding=1, stride=2,groups=bottleneck_channels)
self.bn2 = nn.BatchNorm2d(bottleneck_channels)
self.group_conv1x1_2 = nn.Conv2d(bottleneck_channels, out_channels,kernel_size=1, groups=groups, stride=1)
self.bn3 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.group_conv1x1_1(x)
out = F.relu(self.bn1(out))
out = shuffle_channels(out,groups=self.groups)
out = self.depthwise_conv(out)
out = self.bn2(out)
out = self.group_conv1x1_2(out)
out = self.bn3(out)
x = F.avg_pool2d(x, 3, stride=2, padding=1)
out = F.relu(torch.cat([x,out],1))
return outclass Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,24,kernel_size=3,stride=2,padding=1)
stage2_seq = [ShuffelUnitB(24, 240, groups=3)] + [ShuffelUnitA(240, 240, groups=3) for i in range(3)]
self.stage2 = nn.Sequential(*stage2_seq)
stage3_seq = [ShuffelUnitB(240, 480, groups=3)] + [ShuffelUnitA(480, 480, groups=3) for i in range(7)]
self.stage3 = nn.Sequential(*stage3_seq)
stage4_seq = [ShuffelUnitB(480, 960, groups=3)] + [ShuffelUnitA(960, 960, groups=3) for i in range(3)]
self.stage4 = nn.Sequential(*stage4_seq)
self.fc = torch.nn.Linear(960,10)
def forward(self,x):
batch_size = x.size(0)
print('nihao')
x = self.conv1(x)
x = F.max_pool2d(x, kernel_size=3, stride=2, padding=1)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = F.avg_pool2d(x, 1)
x = x.view(batch_size,-1) #flatten
x = self.fc(x)
return x
model = Net()5.Densenet
(1)网络核心
dense,通道递增,特征图大小不变
transition,减小通道数,减小特征图大小


 (2)代码
(2)代码
def conv_block(in_channel, out_channel):
layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True),
nn.Conv2d(in_channel, out_channel, 3, padding=1, bias=False)
)
return layerclass dense_block(nn.Module):
def __init__(self, in_channel, growth_rate, num_layers):
super(dense_block, self).__init__()
block = []
channel = in_channel
for i in range(num_layers):
block.append(conv_block(channel, growth_rate))
channel += growth_rate
self.net = nn.Sequential(*block)
def forward(self, x):
for layer in self.net:
out = layer(x)
x = torch.cat((out, x), dim=1)
return xdef transition(in_channel, out_channel):
trans_layer = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True),
nn.Conv2d(in_channel, out_channel, 1),
nn.AvgPool2d(kernel_size = 2, stride = 2)
)
return trans_layerclass Net(nn.Module):
def __init__(self, in_channel=1, num_classes=10, growth_rate=32, block_layers=[6, 12]):
super(Net, self).__init__()
# 模型开始部分的卷积池化层
self.block1 = nn.Sequential(
nn.Conv2d(in_channels=in_channel,out_channels=64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(3, 2, padding=1)
)
self.channels = 64
block = []
# 循环添加dense_block模块,并在非最后一层的层末尾添加过渡层
for i, layers in enumerate(block_layers):
block.append(dense_block(self.channels, growth_rate, layers))
self.channels += layers * growth_rate
if i != len(block_layers) - 1:
# 每经过一个dense_block模块,则在后面添加一个过渡模块,通道数减半channels//2
block.append(transition(self.channels, self.channels // 2))
self.channels = self.channels // 2
self.block2 = nn.Sequential(*block) #将block层展开赋值给block2
# 添加其他最后层
self.block2.add_module('bn', nn.BatchNorm2d(self.channels))
self.block2.add_module('relu', nn.ReLU(True))
self.block2.add_module('avg_pool', nn.AvgPool2d(3))
self.classifier = nn.Linear(512, num_classes)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
model = Net()batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root = './data',train = True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle = True ,batch_size = batch_size)
test_dataset = datasets.MNIST(root = './data',train = False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle = False ,batch_size = batch_size)criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,target = data
#print(inputs.shape)
optimizer.zero_grad()
#向前传播
outputs = model(inputs)
loss = criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' %(epoch +1 ,batch_idx+1,running_loss/300))
running_loss = 0.0for epoch in range(10):
train(epoch)