版权声明: https://blog.csdn.net/qq_36711757/article/details/81698570
目录
1、CAST
CAST强转函数语法规则是:Cast(字段名 as 转换的类型 ),其中类型可以为:CHAR(N) ,DATE ,TIME,DATETIME ,DECIMAL,BINARY,SIGNED,UNSIGNED
一般用法: select cast(Id aschar(64)) as Id from Building_table
2、select 1
select 1 from table
作用一:select 1 from mytable;与select anycol(目的表集合中的任意一行) from mytable;与select * from mytable 作用上来说是没有差别的,都是查看是否有记录,一般是作条件用的。select 1 from 中的1是一常量,查到的所有行的值都是它,但从效率上来说,1>anycol>*,因为不用查字典表。
作用二:select id, 'xxxx’ from table 给结果集增加临时列,每行的列值是写在select后的数或字符,这条sql语句中是xxxx
3、CASE WHEN THEN ELSE END
CASE WHEN THEN ELSE END
注意:其实从case到end的这段语句完全可以看作一个字段名,后边可以也必须加AS,给结果集中的这个字段添加别名,不然字段名显示的就是从case到end的这段语句!!!!
注意:其实case语句的本质就是对每行记录的某些字段进行比较,然后根据结果,返回一个自定义的新值,最终这些值组成了一个新字段,而行列转换也不过是在这基础上,用了分组聚合!!!!
注意:Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略!!!
--比如说,下面这段SQL,你永远无法得到“第二类”这个结果
CASE WHEN col_1 IN ( 'a', 'b') THEN '第一类'
WHEN col_1 IN ('a') THEN '第二类'
ELSE'其他' END
用法一 :枚举一个字段所有可能的值,然后根据这些值衍生出新的值,这些值将作为一个自定义字段添加到结果集中
-
SELECT -
NAME '英雄', -
CASE NAME -
WHEN '德莱文' THEN -
'斧子' -
WHEN '德玛西亚-盖伦' THEN -
'大宝剑' -
WHEN '暗夜猎手-VN' THEN -
'弩' -
ELSE -
'无' -
END '装备' -
FROM -
user_info;

用法二:判断字段范围,根据判断结果的不同衍生出不同的值,这些值将作为一个自定义字段添加到结果集中
-
-- when 表达式中可以使用 and 连接条件 -
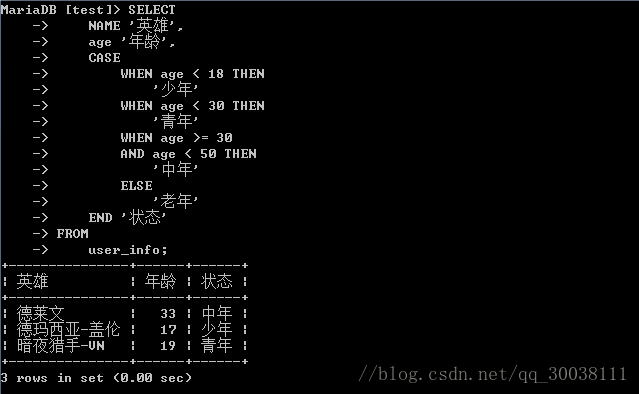
SELECT -
NAME '英雄', -
age '年龄', -
CASE -
WHEN age < 18 THEN -
'少年' -
WHEN age < 30 THEN -
'青年' -
WHEN age >= 30 -
AND age < 50 THEN -
'中年' -
ELSE -
'老年' -
END '状态' -
FROM -
user_info;
用法三:使用 case when 配合 聚合函数 实现行转列,即行数据变列字段,可以大幅减少结果集的记录量,更符合非程序员用户的阅读习惯,但是想要行列转换,就必须要用聚合函数和分组!!!
举个例子,平时数据库想要查学生成绩,结果集都是三列N行,姓名,科目,成绩,有N个科目就有N行,但是上过学的都知道,平时发的成绩条,哪有那么多行,直接一行搞定,要你是用户你觉得这两种方式哪种看着舒服?
实例代码和详细用法都在下边三个链接里面:
https://blog.csdn.net/u014180504/article/details/79150492
https://blog.csdn.net/qq_30038111/article/details/79611167
https://www.cnblogs.com/clphp/p/6256207.html
4、对表字段名的操作
select语句中,对表字段名的所有操作,其实是对字段对应的记录值进行操作,比如+,-,聚合函数,concat拼接函数等
关键点:distinct去重关键字,直接使用即可,例如SELECT DISTINCT stu_id
关键点:+号,在mysql中+号不能作为字符串连接符,如果两个字符串用+连接,会自动把两边转化成数字类型再进行相加操作,如果哪一边字符串不能转为数字,哪一边就返回0。
5、派生表
派生表和子查询通常可互换使用。当SELECT语句的FROM子句中使用独立子查询时,我们将其称为派生表。
派生表必须具有别名。
6、嵌套查询
嵌套查询
定义:一个内层查询语句(select-from-where)块可以嵌套在另外一个外层查询块的where子句中,其中外层查询也称为父查询,主查询。内层查询也称子查询,从查询。子查询一般不使用order by子句,只能对最终查询结果进行排序。
嵌套查询的工作方式是:先处理内查询,由内向外处理,外层查询利用内层查询的结果嵌套查询不仅仅可以用于父查询select语句使用。还可以用于insert、update、delete语句或其他子查询中。
子查询的语法规则:子查询的select查询总是使用圆括号括起来;任何可以使用表达式的地方都可以使用子查询,只要它返回的是单个值;如果某个表只出现在子查询中二不出现在外部查询中,那么该表的列就无法包含在输出中;一般,对于子查询生成的表都给它起个别名。
任何可以使用表达式的地方都可以使用子查询(一般用在WHERE后),这句话是重点,可以分为两种情况:
注意:从本质上来说,这种嵌套查询就是每行的特定字段值代入表达式之后,只有表达式结果为true的那行记录才会被输出。
一、当子查询的返回值只有一个时,可以使用比较运算符如=、<、>、>=、<=、!=等
二、如果子查询的返回值不止一个,而是一个集合时,则不能直接使用比较运算符:(子查询关键字来啦)
any必须与=、>、>=、<、<=、<>结合起来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的任何一个数据。
注意:some是any的别名,用法相同,也就是说知道就行,没卵用
all必须与=、>、>=、<、<=、<>结合是来使用,分别表示等于、大于、大于等于、小于、小于等于、不等于其中的其中的所有数据。
例如:
select s1 from t1 where s1 > any (select s1 from t2);
假设表t1中有一行包含(10),t2包含(21,14,6),则表达式为true;如果t2包含(20,10),或者表t2为空表,则表达式为false。如果表t2包含(null,null,null),则表达式为unkonwn。
all的意思是“对于子查询返回的列中的所有值,如果比较结果为true,则返回true”
例如:
select s1 from t1 where s1 > all(select s1 from t2);
假设表t1中有一行包含(10)。如果表t2包含(-5,0,+5),则表达式为true,因为10比t2中的查出的所有三个值大。如果表t2包含(12,6,null,-100),则表达式为false,因为t2中有一个值12大于10。如果表t2包含(0,null,1),则表达式为unknown。如果t2为空表,则结果为true。
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的两个等效查询
-
select * from user where userId in (1, 2, 3); -
select * from user where userId = 1 or userId = 2 or userId = 3;
not in与in相反,例如:
-
select * from user where userId not in (1, 2, 3); -
select * from user where userId != 1 and userId != 2 and userId != 3;
总的来说,in查询就是先将子查询条件的记录全都查出来,假设结果集为B,如果父表字段值在B中,就返回true,且返回其对应的那条记录!!!!
值得一提的是,in查询的子条件返回结果必须只有一个字段,例如:
select * from user where userId in (select id from B);而不能是
select * from user where userId in (select id, age from B);exists表示存在,它常常和子查询配合使用,例如下面的SQL语句
-
SELECT * FROM `user` -
WHERE exists (SELECT * FROM `order` WHERE user.id = order.user_id)
exists用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False。
当子查询返回为真时,则外层查询语句将进行查询。
当子查询返回为假时,外层查询语句将不进行查询或者查询不出任何记录。
7、while,if
while循环
-
# while循环语法: -
# while 条件 DO -
# 循环体; -
# end while; -
# */ -
-- 实例: -
create procedure sum1(a int) -
begin -
declare sum int default 0; -- default 是指定该变量的默认值 -
declare i int default 1; -
while i<=a DO -- 循环开始 -
set sum=sum+i; -
set i=i+1; -
end while; -- 循环结束 -
select sum; -- 输出结果 -
end
IF ELSE 作为流程控制语句使用
-
IF search_condition Then -
statement_list -
[ELSEIF search_condition Then] -
[ELSE -
statemeny_list] -
END IF;
最关键也是最坑爹的一点,while循环和if只能在存储过程中使用!!!!!
但有一种特殊情况:
如果存在表则删除表然后创建
drop table if exists address_book
但是也只能这么写,不能扩展加and什么的!!!!!
8、临时表
临时表主要用于对大数据量的表上作一个子集,提高查询效率。
临时表使用有一些限制条件:
* 不能使用rename来重命名临时表。但是可以alter table rename代替:
mysql>ALTER TABLE orig_name RENAME new_name;
* 可以复制临时表得到一个新的临时表,如:
mysql>create temporary table new_table select * from old_table;
* 但在同一个query语句中,相同的临时表只能出现一次。如:
可以使用:mysql> select * from temp_tb;
但不能使用:mysql> select * from temp_tb, temp_tb as t;
错误信息: ERROR 1137 (HY000): Can't reopen table: 'temp_tb'
同样相同临时表不能在存储函数中出现多次,如果在一个存储函数里,用不同的别名查找一个临时表多次,或者在这个存储函数里用不同的语句查找,都会出现这个错误。
既然子查询中不能再次打开临时表,那么就使用其他临时表 先把子查询的数据存起来,然后再处理。
* 但不同的临时表可以出现在同一个query语句中,如临时表temp_tb1, temp_tb2:
Mysql> select * from temp_tb1, temp_tb2;
临时表可以手动删除:
DROP TEMPORARY TABLE IF EXISTS temp_tb;
9、读写操作的影响行数
读操作的影响行数:select fount_rows();
写操作的影响行数:select row_count();
但切记:只对一次操作有效!!也就是只返回最后一次操作的影响的行数的值.
10、NULL相关函数
第一步,is NULL要比ISNULL()的比较
SELECT * from 表名 where 字段名 is NULL

SELECT * from 表名 where ISNULL(字段名)

由上面可以看出,is NULL要比ISNULL()快一点。
第二步,is NULL和IFNULL()的比较
SELECT * from 表名 where 字段名 is NULL
SELECT * from 表名 where IFNULL(字段名,'0') = '0';

由上面可以看出,可看出IFNULL()要比is NULL快一点。
综上所述,查询空值的运行速度基本上为IFNULL()>is NULL>ISNULL()。
重点:
IFNULL(expr1,expr2)的用法:
假如expr1 不为 NULL,则 IFNULL() 的返回值为 expr1;
否则其返回值为 expr2。IFNULL()的返回值是数字或是字符串,具体情况取决于其所使用的语境。
| 1 2 3 4 5 6 7 8 9 |
|
NULLIF(expr1,expr2) 的用法:
如果expr1 = expr2 成立,那么返回值为NULL,否则返回值为 expr1。这和CASE WHEN expr1 = expr2
THEN NULL ELSE expr1 END相同。
| 1 2 3 4 5 |
|
IF(exPR1,expr2,expr3) 的用法:
如果 expr1 是TRUE (expr1 <> 0 and expr1 <> NULL),则 IF()的返回值为expr2; 否则返回值则为 expr3。IF() 的返回值为数字值或字符串值,具体情况视其所在语境而定。
SELECT IF(1>2,2,3);11、分组聚合
分组一般和聚合一块出现!!!!!
分组,说白就是找相同,根据字段值(字段组),相同就是一组
分组聚合,在已经分好组的前提上,对每组进行操作,返回对每组操作的结果,也就是一组只有一个结果。比如,如果想知道每组里有多少条记录,可以用count(1)
分组查询,如果查询的字段名和group by 的字段名是一样的,输出结果集就是不同的各个组名(字段名),这很好理解;但如果查询的不光是group by的字段名,那结果集是每组查到的第一条记录,注意是一条,如果你想看每个分组的所有数据,建议你用order by和where。
分组排序:是先排序后分组,造成的结果是,如果查询的不光是group by的字段名,那结果集会因为顺序不同而变化,当然,也只是每个分组里的一条不同记录罢了。
12、时间戳
mysql时间戳
获得当前日期+时间(date + time)函数:now()
13、变量赋值
在MySQL存储过程中使用SELECT …INTO语句为变量赋值:
用来将查询返回的一行的各个列值保存到局部变量中。
要求:
查询的结果集中只能有1行。
SELECT col_name[,...] INTO var_name[,...] table_expr
使用SELECT …INTO语句在数据库中进行查询,并将得到的结果赋值给变量。
①col_name:要从数据库中查询的列字段名;
②var_name:变量名,列字段名按照在列清单和变量清单中的位置对应,将查询得到的值赋给对应位置的变量;
③table_expr:SELECT语句中的其余部分,包括可选的FROM子句和WHERE子句。
14、备份表
MySQL不支持Select Into语句直接备份表结构和数据
错误方法:
MYSQL不支持:
Select * Into new_table_name from old_table_name; 这是sql server中的用法
替代方法:
Create table new_table_name (Select * from old_table_name);
15、DATE函数
DATE_ADD() 函数向日期添加指定的时间间隔。
语法
DATE_ADD(date,INTERVAL expr type)date 参数是合法的日期表达式。expr 参数是您希望添加的时间间隔。
type 参数可以是下列值DAY,HOUR,等等一堆
实例
假设我们有如下的表:
| OrderId | ProductName | OrderDate |
|---|---|---|
| 1 | 'Computer' | 2008-12-29 16:25:46.635 |
现在,我们希望向 "OrderDate" 添加 2 天,这样就可以找到付款日期。
我们使用下面的 SELECT 语句:
SELECT OrderId,DATE_ADD(OrderDate,INTERVAL 2 DAY) AS OrderPayDate
FROM Orders
结果:
| OrderId | OrderPayDate |
|---|---|
| 1 | 2008-12-31 16:25:46.635 |