执行计划能告诉我们什么?
当我们的系统上线后数据库的记录不断增加,之前写的一些SQL语句或者一些ORM操作效率变得非常低。我们不得不考虑SQL优化,SQL优化大概是这样一个流程:1.定位执行效率低的SQL语句(定位),2.分析为什么这段SQL执行的效率比较低(分析),3.最后根据第二步分析的结构采取优化措施(解决)。而EXPLAIN命令的作用就是帮助我们分析SQL的执行情况,属于第二步。说的规范一点就是:EXPLAIN命令是查看查询优化器如何决定执行查询的主要的方法。学会解释EXPLAIN将帮助我们了解SQL优化器是如何工作的。执行计划可以告诉我们SQL如何使用索引,连接查询的执行顺序,查询的数据行数。
如何使用执行计划?
要使用EXPLAIN,只需要在查询的SELECT关键字之前增加EXPLAIN这个词。

解释执行计划中EXPLAIN的列
ID列
是一位数字,表示执行SELECT语句的顺序。
id值相同执行顺序从上到下。
id值不同时id值大的先执行。
这一列显示了对应行是简单还是复杂SELECT.取值如下:SIMPLE值意味着查询不包括子查询和UNION。查询有任何复杂的子部分,则最外层标记为PRIMARY.取值如下:
ABLE
输出数据行所在的表的名称

PARTITIONS
对于分区表,显示查询的分区ID,对于非分区表,显示为NULL
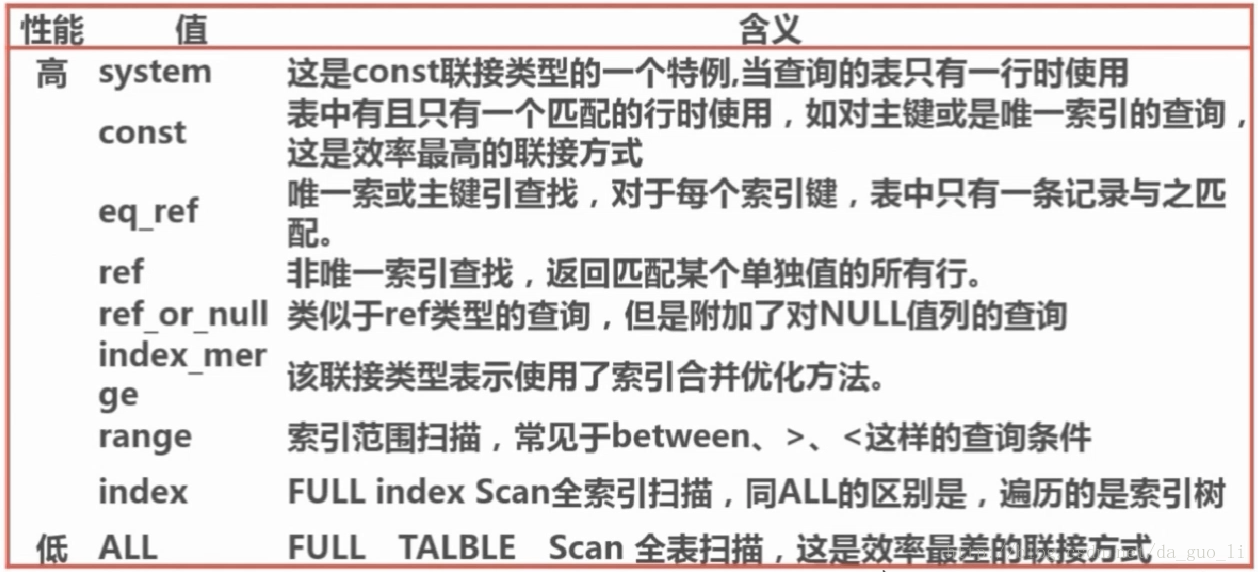
TYPE
EXTRA

POSSIBLE_KEYS
指出MySQL能使用哪些索引来优化查询,查询所涉及的列上的索引都会被列出,但不一定会被使用
KEY
查询优化器优化查询实际所使用的索引,如果没有可用的索引,则显示为NULL,如查询使用了覆盖索引,则该索引仅出现在Key列中
KEY_LEN
表示索引字段的最大可能长度,KEY_LEN的长度由字段定义计算而来,并非数据的实际长度
REF
表示哪些列或常量被用于查找索引列上的值
ROWS
表示MySQL通过哪些列或常量被用于查找索引列上的值,ROWS值的大小是个统计抽样结果,并不十分准确
Filtered
表示返回结果的行数占需读取行数的百分比,Filter列的值越大越好
执行计划的限制
无法展示存储过程,触发器,UDF(自定义函数)对查询的影响
无法使用EXPLAIN对存储过程进行分析
早期版本的MySQL只支持对SELECT语句进行分析,如果想要分析UPDATE,INSERT语句需要将它们通过某种手段转换成SELECT语句。