EXPLAIN:预估执行计划(预估数据)
EXPLAIN ANALYZE:真实执行计划(真实数据)
复制代码1.EXPLAIN执行计划参数介绍
默认postgresql开启了三个参数那也就说明三个吧,如需更多信息可以配
1.cost:计算单位是磁盘页面的存取数量(分析系统性能瓶颈的关键)
详细:如1.0将表示一次顺序的磁盘页面读取,
其中上层节点的开销将包括其所有子节点的开销。
这里的输出行数(rows)并不是规划节点处理/扫描的行数,
通常会更少一些。一般而言,顶层的行预计数量会更接近于查询实际返回的行数。
复制代码预估损耗代价数据计算公式: 1(seq_page_cost)*13(磁盘总页数)+0.01(cpu_tuple_cost)*1000(表的总记录数)+0.0025(cpu_operation_cost)*1000(表的总记录数)=25.5
复制代码磁盘页面:磁盘的块存储(最小存储单位:扇贝大小)
详细:磁盘中的存储进去的数据是存储在了磁盘的块中,磁盘中有很多块
复制代码具体计算演示如下
创建一张demo表
create table demo(id serial,sid character varying,name character varying);
复制代码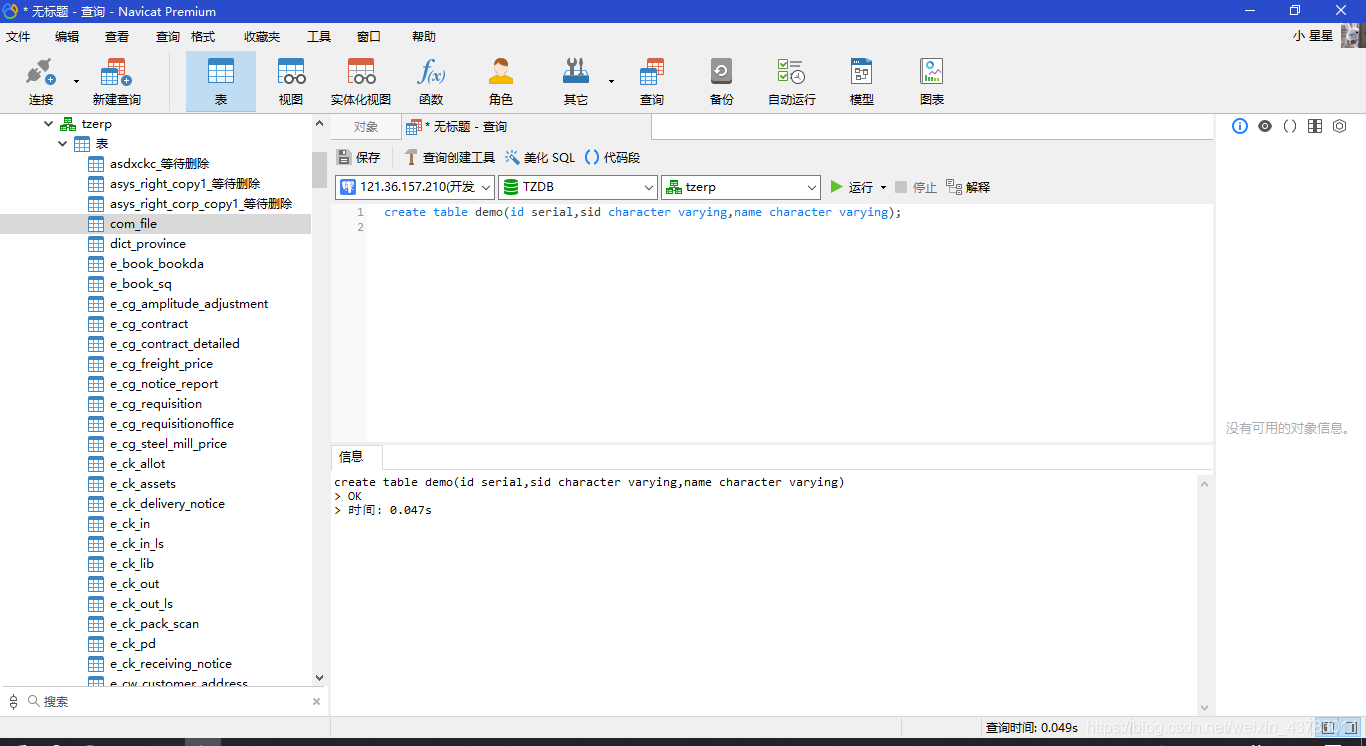
插入1千条数据
insert into demo values(generate_series(1,1000),md5(random()::text),md5(random()::text));
复制代码
explain analyze select * from demo;
可以看到总时间花费了23。
复制代码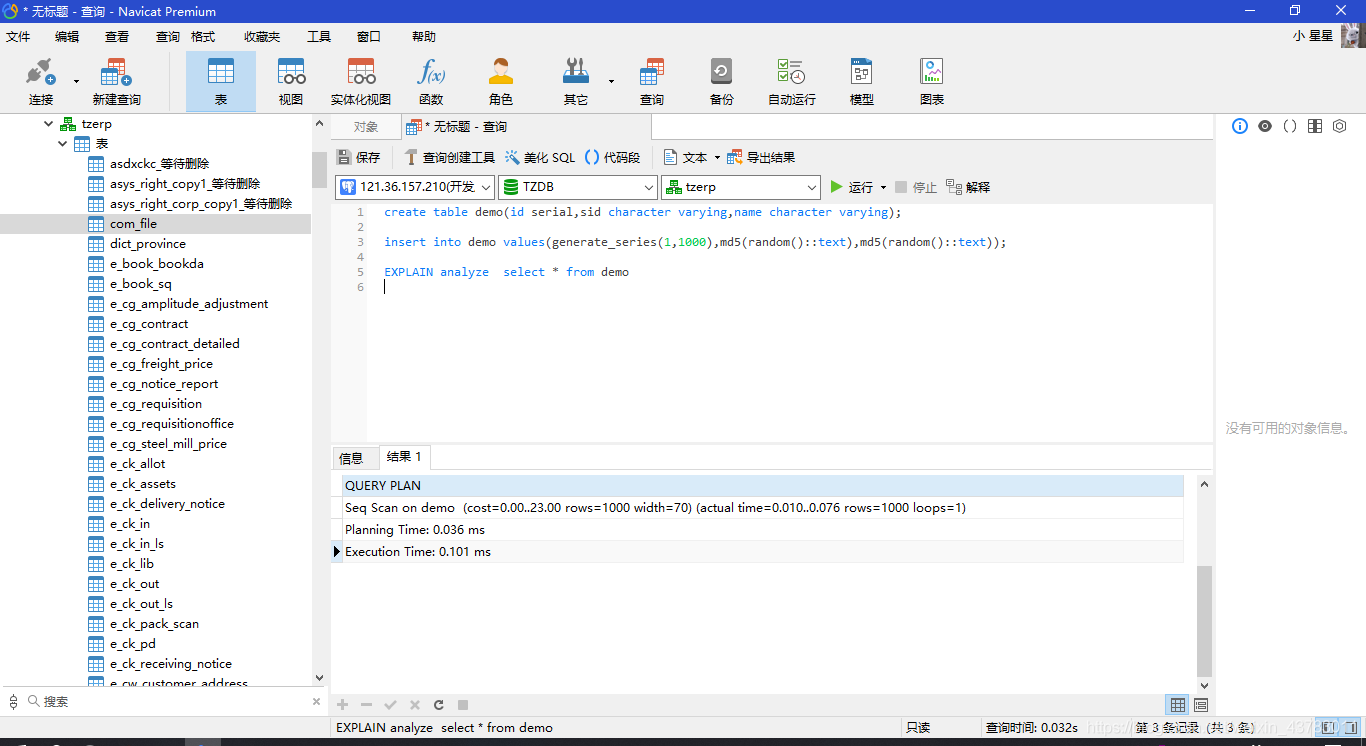
真实数据analyze的actual time等值于预估的EXPLAIN{cost}只不过预估的EXPLAIN{cost}跟真实环境下的cost有点不同,受诸多因素影响。
注意: analyze的{actual time}数值是以真实时间的毫秒来计算的,而EXPLAIN的{cost}预估值是以磁盘页面读取数量来计算的,所以它们很可能是不一致的。然而我们需要关注的只是两组数据的比值是否一致。
复制代码首先了解如下几个系统常量,跟后期的代价计算有关
`seq_page_cost`:连续块扫描操作的单个块的cost. 例如全表扫描
`random_page_cost`: 随机块扫描操作的单个块的cost. 例如索引扫描
`cpu_tuple_cost`:处理每条记录的CPU开销(tuple:关系中的一行记录)
`cpu_index_tuple_cost`:扫描每个索引条目带来的CPU开销
`cpu_operator_cost`:操作符或函数带来的CPU开销.
(需要注意函数以及操作符对应的函数的三态, 执行计划会根据三态做优化, 关系到多条记录时三态对应的调用次数是需要关心的)
复制代码计算结构分析
当前的扫描一个page页的单位成本是1。
show seq_page_cost;
复制代码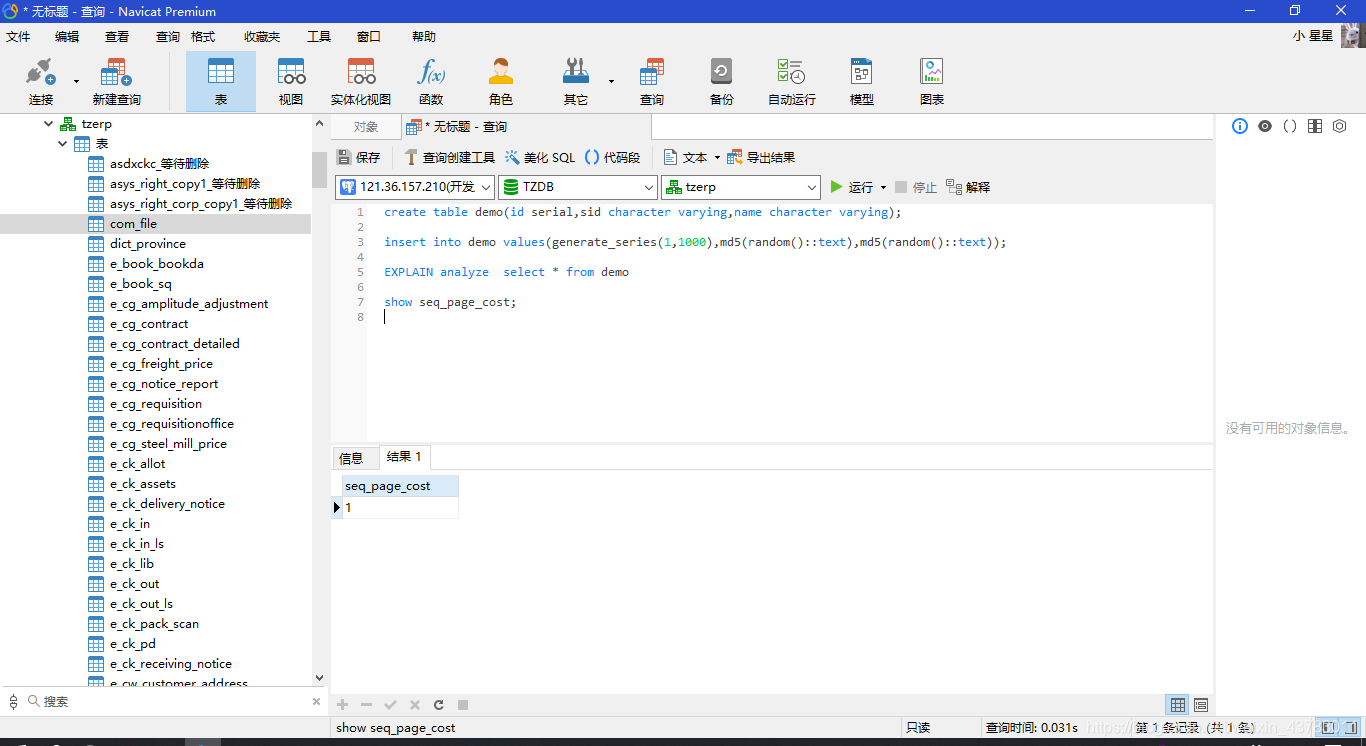
当前是几个page(磁盘块存储)和总共几条记录
select relpages,reltuples from pg_class where relname='demo';
复制代码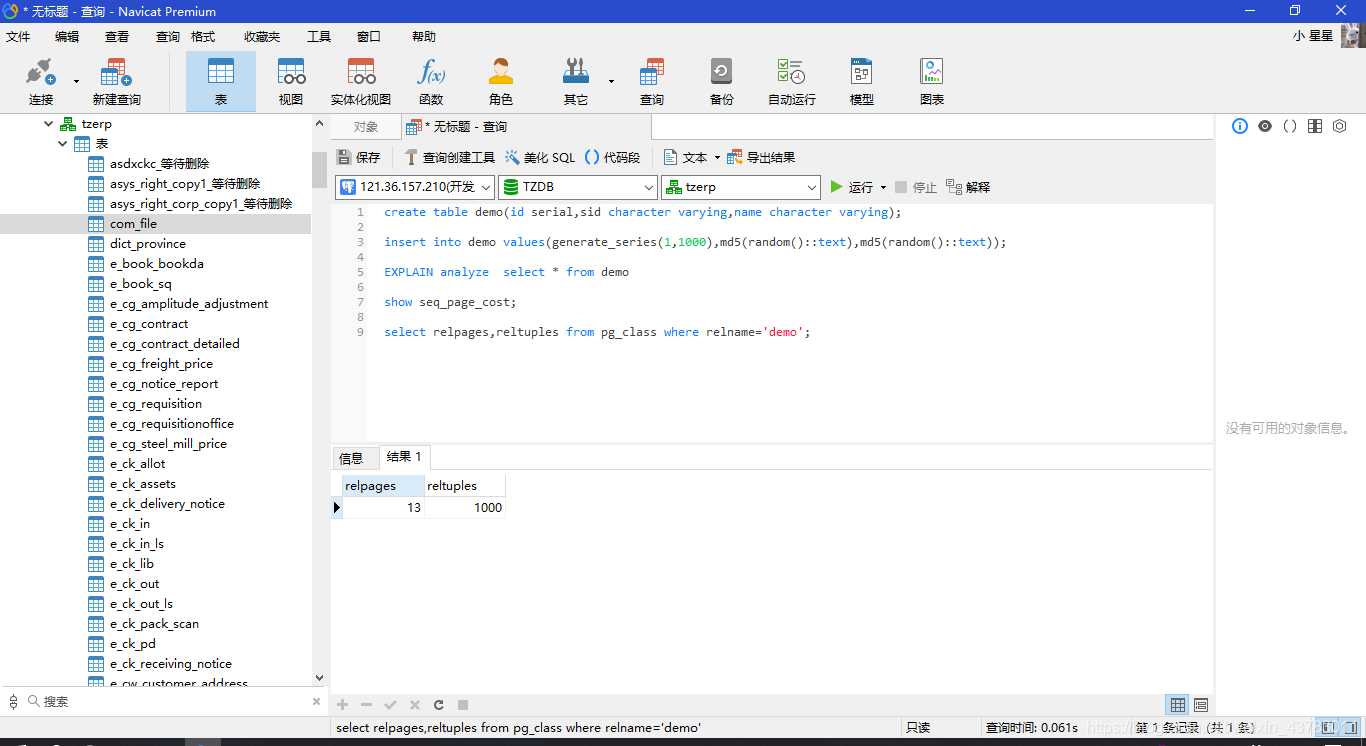
当前cpu处理每一行的cost的开销
show cpu_tuple_cost;
复制代码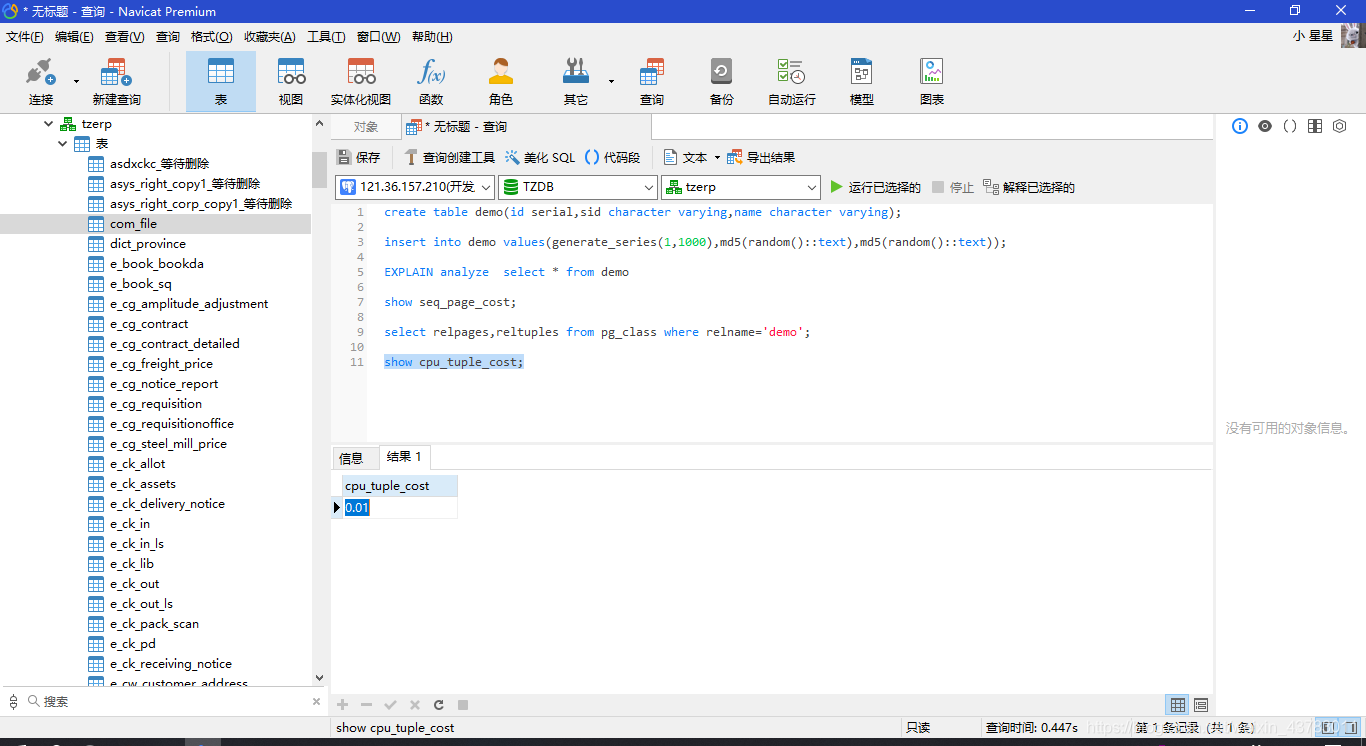
计算结果
(1[seq_page_cost]*13[磁盘总页数])+(0.01[cpu_tuple_cost]*1000[表的总记录数])=23
复制代码再来看一个有问题执行计划
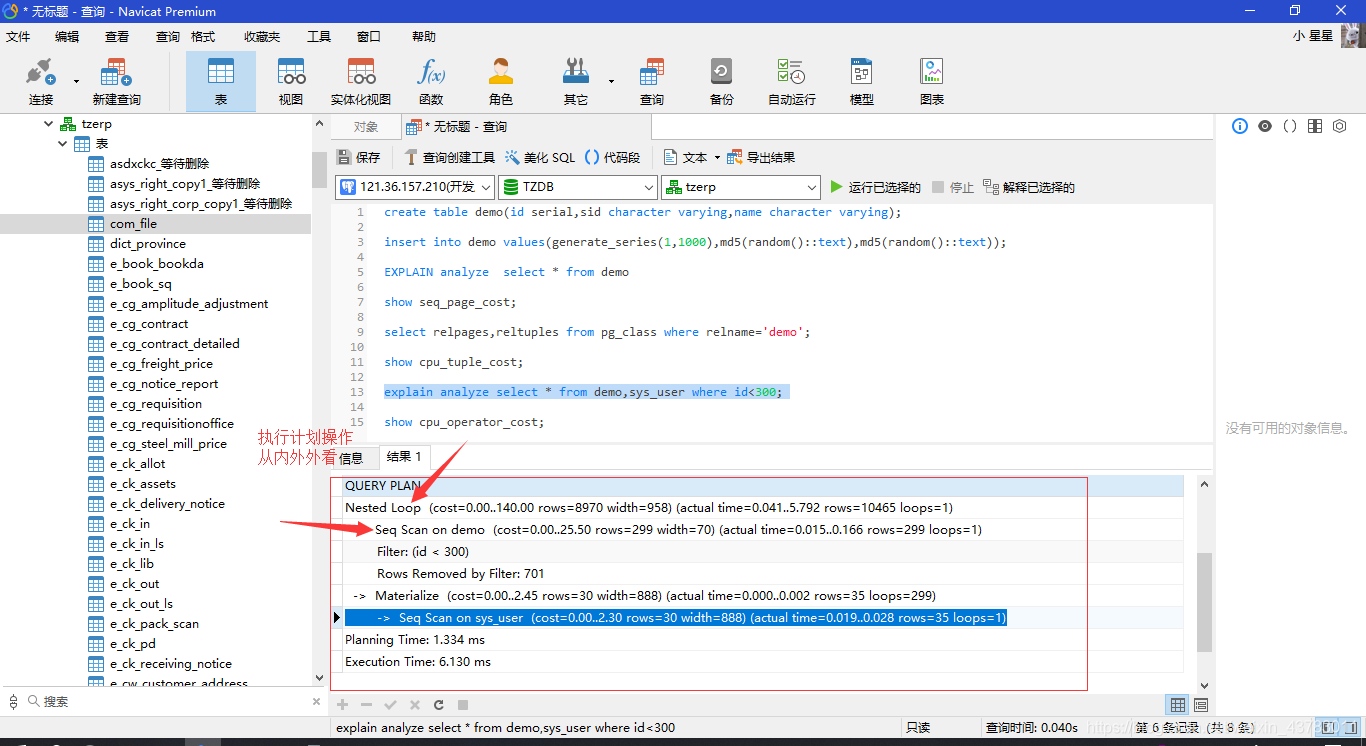
explain analyze select * from demo where id<300;
复制代码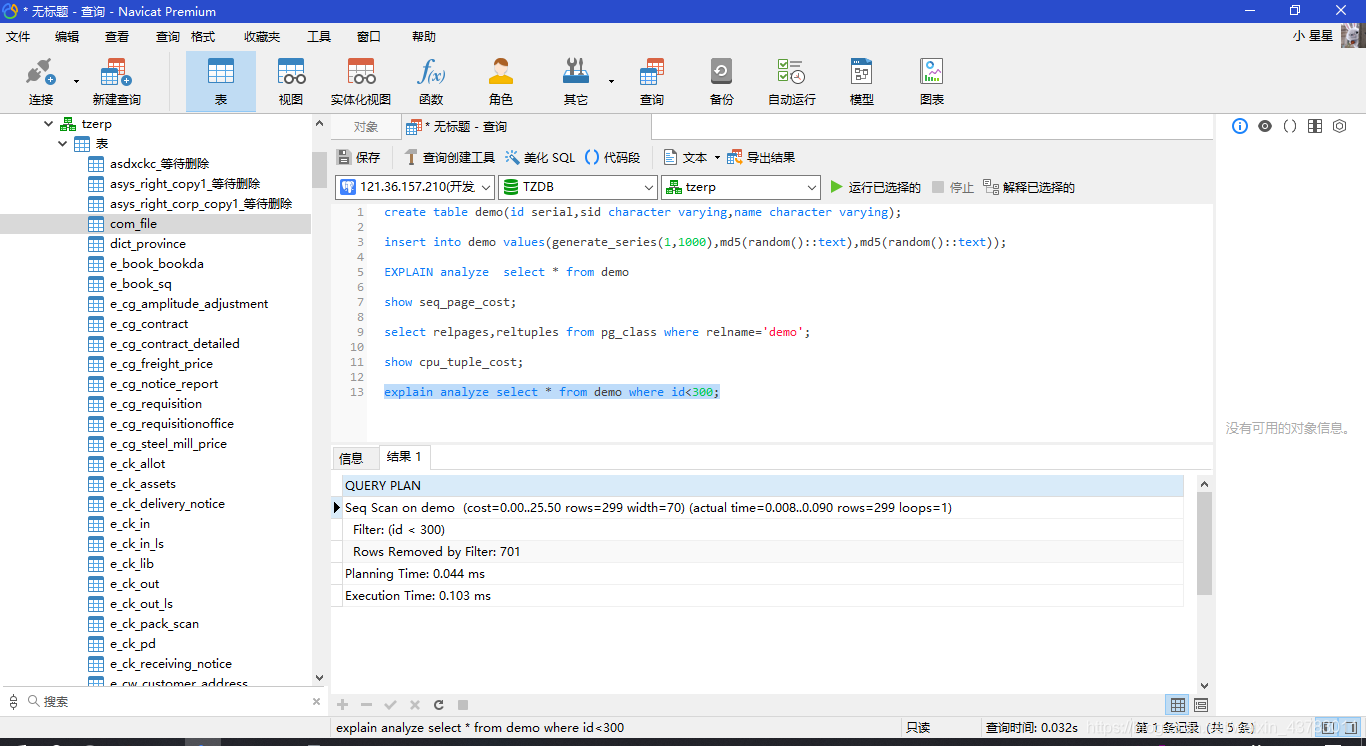 为什么这个查询计划比上一个查询计划返回的行数少,总的cost的时间反而增加呢?
为什么这个查询计划比上一个查询计划返回的行数少,总的cost的时间反而增加呢?
原因如下:
------------------------------------------------------------
1. 该查询计划的扫描数据块的方式和上一个查询计划的扫描方式一样,
都是使用了顺序扫描,即两个查询计划的扫描的数据块文件个数是一样的,
反而该查询计划在过滤每条记录的时候还需要检查where条件id<300,
增加了cpu 的时间开销;
------------------------------------------------------------
2. 该cost只反映规划器关心的东西。
尤其是开销没有把结果行传递给客户端的时间考虑进去,
这个时间可能在真正的总时间里面占据相当重要的分量;
但是被规划器忽略了,因为它无法通过修改规划来改变之
------------------------------------------------------------
复制代码接下来开始计算cost=25.5是怎么来的:
当前操作符或函数带来的CPU开销(预估)
show cpu_operator_cost;
复制代码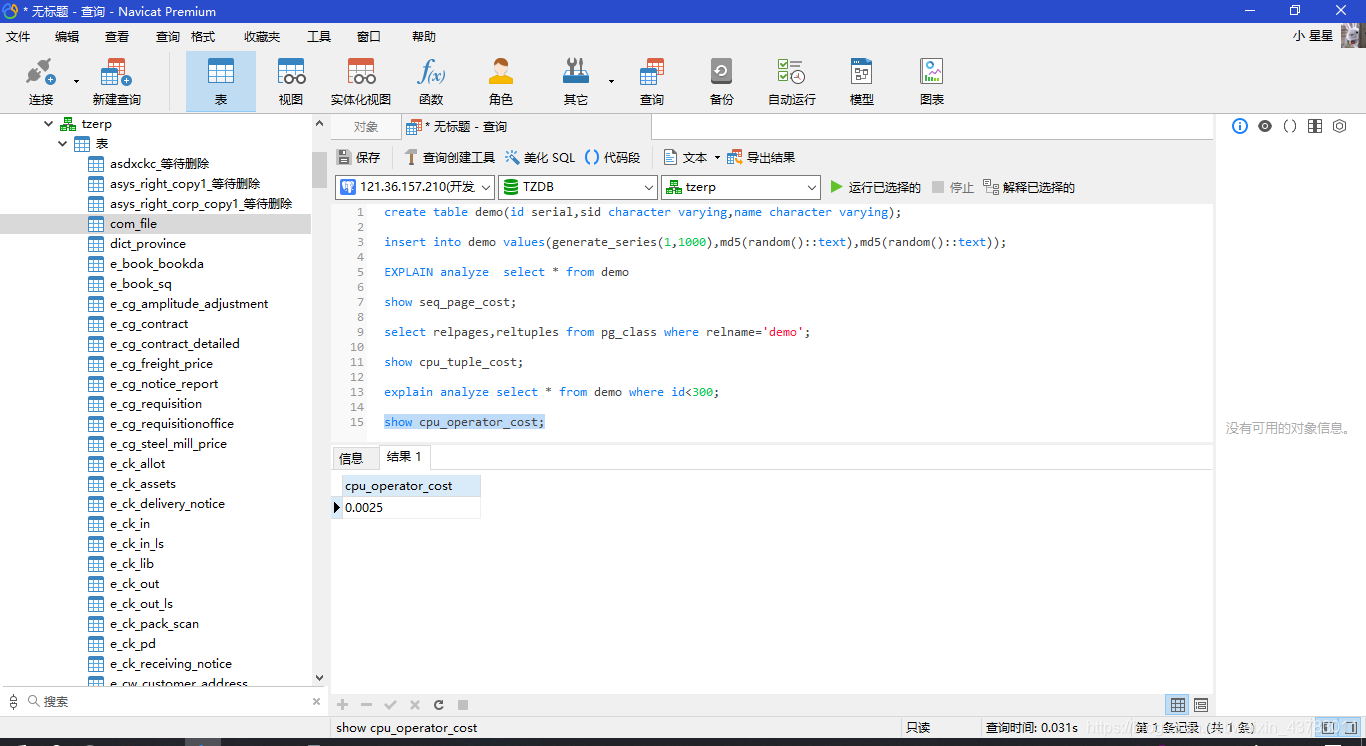
计算结果
(1[seq_page_cost]*13[磁盘总页数])+(0.01[cpu_tuple_cost]*1000[表的总记录数])+(0.0025[cpu_operation_cost]*1000[表的总记录数])=25
复制代码2.rows:返回结果行数 3.width:每行的字节数大小
EXPLAIN ANALYZE 执行计划参数介绍
默认postgresql开启了三个参数那也就说明三个吧,如需更多信息可以配
1.actual time:计算单位是毫秒(分析系统性能瓶颈的关键)
2.rows:返回结果行数
3.loops:显示当前节点执行的总次数
总体的看法:从内往外看,子节点看向父节点