快速排序是对世界影响最大的排序算法之一,至于其背景之类的知识可百度获取.
思路如下:
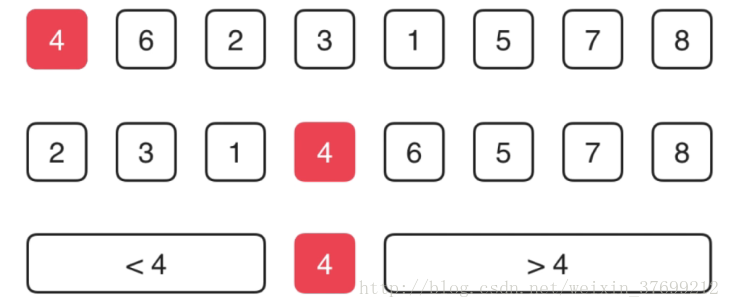
假设待排序数组如下

现在要将4 放到4 应该放到的位置,快速排序的思想是将整个数组划分为两部分,一部分的数据都小于等于4,另一部分的数据都大于4,如下图:
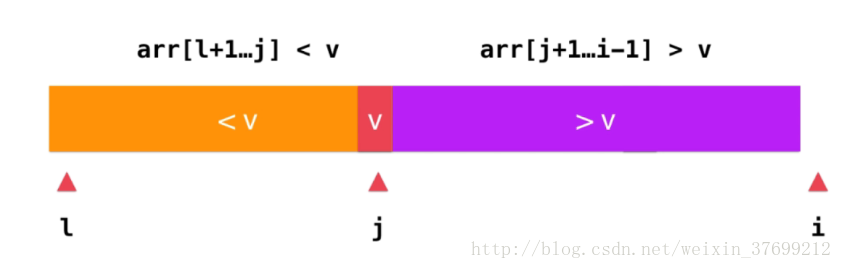
继续抽象思路,观察上面的排列情况,假设待排序数组为[l,r]前闭后闭,[l+1,j]区间满足小于v,[j+1,i)前闭后开满足大于v,当前正在遍历的下标为i,如下图:

等所有的数据都按照上图排列之后,将j与l的元素进行交换,即将l对应的元素放到了应该放的位置,如下图:

理解了思路,那么代码会比较好实现,使用递归思想来实现快速排序:
/**
* 快速排序 思想 V | <= V ||>V|
*
* @author JamesWang Create on 2018年1月22日 下午1:55:10
*/
public class QuikSort {
public static void sort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
/**
* [l,r]
*
* @param arr
* @param i
* @param j
*/
private static void quickSort(int[] arr, int l, int r) {
if (l >= r) {
return;
}
int p = partition(arr, l, r);
quickSort(arr, l, p - 1);
quickSort(arr, p + 1, r);
}
/**
*
* @param arr
* @param p1
* @param p2
*/
public static void swap(int[] arr,int p1,int p2) {
if(p1 == p2 || arr[p1] == arr[p2]) {
return;
}
arr[p1] = arr[p1] ^ arr[p2];
arr[p2] = arr[p1] ^ arr[p2];
arr[p1] = arr[p1] ^ arr[p2];
}
// [l+1,j] <= v [l+1,i) > v
private static int partition(int[] arr, int l, int r) {
int v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++) {
if (arr[i] < v) {// j + 1 与 i 交换
swap(arr,++j,i);
}
}
swap(arr, l, j);
return j;
}
public static void main(String[] args) {
int[] arr = SortUtils.createArray(20);
System.out.println("arr before = " + SortUtils.getString(arr));
sort(arr);
System.out.println("arr after = " + SortUtils.getString(arr));
}
}但是上面的代码还有一些明显的不足,考虑一下此场景,当原数据本身就是接近于有序或者就是有序的情况下,此时该算法会退回到O(N2),在每一次进行递归的时候,都是直接从第二个元素开始都算作后半段,那么此时算法相当于一个链表此时复杂度为O(N),而每次的partition又是O(N),因此此时的时间复杂度为O(N2),下图为说明:

针对这个缺陷,在原有基础上还是比较好改善的,主要是在partition时进行优化
// [l+1,j] <= v [l+1,i) > v
private static int partition(int[] arr, int l, int r) {
int k = random.nextInt(r - l) + l + 1;//随机获取待排序的下标,然后将该下标对应的元素与l对应的元素交换
swap(arr,k,l);
//下面不变
int v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++) {
if (arr[i] < v) {// j + 1 与 i 交换
swap(arr,++j,i);
}
}
swap(arr, l, j);
return j;
}通过上面的改进,虽然不能百分百避免退化为O(N2)的情况,但是已经将这个概率降低为1/ (N * (N-1) * (N - 2) ... * 1) ,随着数据的增大,这个概率会无限接近于0.
现在这个快速排序优化了一个地方,但是当面对有多个重复值得情况时,这个快速排序依然会退化到O(N2),因为在上面的算法实现中,如果有多个重复值得话,会在算法中都分配到同一边,这样又相当于有序了,依然会退化为O(N2),这个时候是需要对重复元素进行处理,下面为双路快排,原理:从两边分别进行遍历,直到两边同时满足条件时才进行交换,具体partition代码如下:
private static int partition(int[] arr, int l, int r) {
int k = random.nextInt(r - l) + l + 1;// 随机获取待排序的下标,然后将该下标对应的元素与l对应的元素交换
swap(arr, k, l);
int v = arr[l];
int lk = l + 1;
int rk = r;
while (true) {
while (lk <= rk && arr[lk] < v) {
lk++;
}
while (rk >= lk && arr[rk] > v) {
rk--;
}
if (lk > rk) {
break;
}
swap(arr, lk, rk);
lk++;
rk--;
}
swap(arr, l, rk);
return rk;
}除了双路快排还有一种改进过的快速排序算法值得借鉴,三路快速排序,整个算法中基本的逻辑不变,改变的是在partition的时候是怎么处理的,首先V是待排元素,核心逻辑:把数组划分为三部分,第一部分为小于V的(在数组左侧),第二部分为等于V的(在第一部分右边),第三部分为大于V的(在数组右侧).详细看下面
/**
* 三路快排
* v 待排元素
* lk [l+1,lk] < v 小于v的边界 在数组的左边
* i [lk+1,i) = v 待排元素的下标 同时要保证 lk + 1 到i-1 为 == v
* rk [rk , r] > v 大于v的边界 在数组的右边
*
* @param arr
* @param l
* @param r
*/
private static void quickSortThreeWays(int[] arr,int l,int r) {
if(l >= r) {//其实这里可以优化为 当元素个数为比较少的时候 直接进行插入排序 即可
return;
}
int k = random.nextInt(r - l) + l + 1;//随机化 待排下标 以保持排序树的平衡 避免退化为O(N^2)
swap(arr,l,k);
int v = arr[l];
int lk = l;
int i = l + 1;
int rk = r + 1;
for(;i < rk;) {
if(arr[i] > v) {
swap(arr,i,--rk);
}
else if(arr[i] < v) {
swap(arr,i,++lk);
i++;
}
else if(arr[i] == v) {
i++;
}
}
swap(arr,l,lk);//将待排元素与小于v的最后一个进行交换
quickSortThreeWays(arr,l,lk - 1);//递归 排序 小于v的部分
quickSortThreeWays(arr,rk,r);//递归排序大于v的部分
}这个的效率在面对有很多重复元素时,其效率会比普通的快速排序和双路快排要好,面对有很多元素并且没有那么多的重复元素时,其效率也不差,因此这个三路快排是快速排序中比较平衡的算法,三路快排是默认的语言库函数中使用的排序算法(比如java).