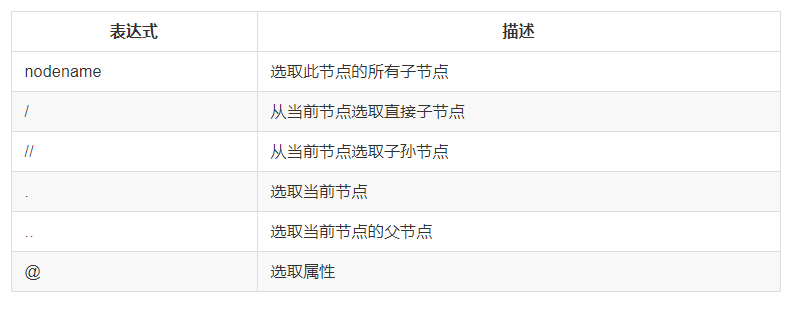
一、xpath库使用:
1、基本规则:
2、将文件转为HTML对象:
1 html = etree.parse('./test.html', etree.HTMLParser()) 2 result = etree.tostring(html) 3 print(result.decode('utf-8'))
3、属性多值匹配:
//a[contains(@class,'li')]
4、多属性匹配:
//a[@class="a" and @font="red"]
5、按序选择:

二、beautifulsoup库学习:
1、基本初始化:
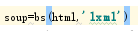
将HTML字符串用lxml格式来解析,并补全标签,创建html处理对象。
2、获取信息:
(1)获取title的name属性:
soup.title.name
(2)获取多属性:
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))